
What Do We Maximize in Self-Supervised Learning And Why Does Generalization Emerge?
R Shwartz-Ziv, R Balestriero, K Kawaguchi, Y LeCun
[New York University & Facebook]
自监督学习最大化目标及泛化机制
要点:
-
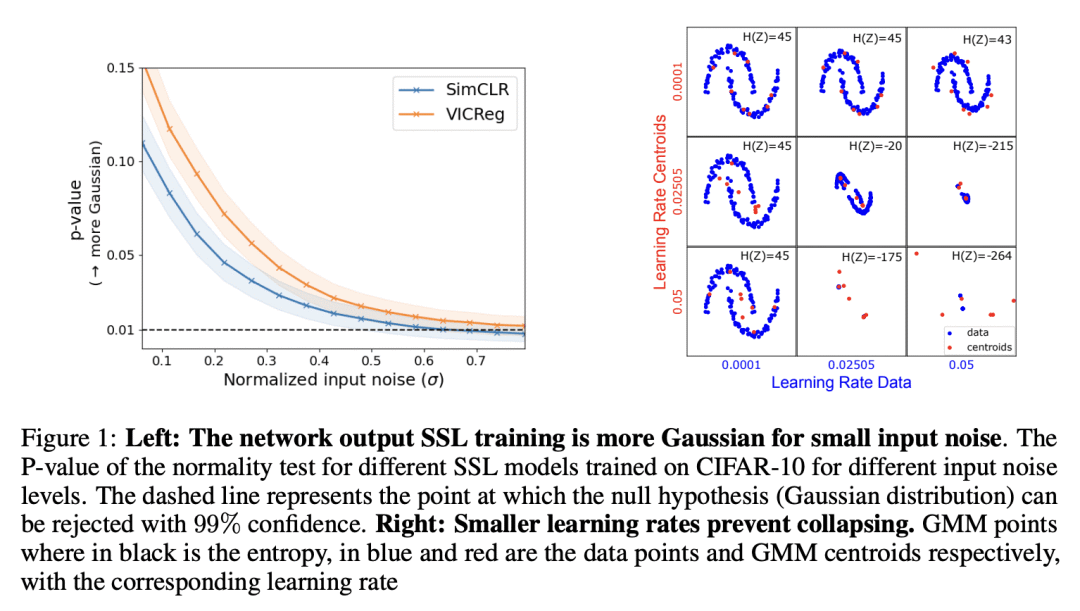
提供了对自监督学习(SSL)方法及其最优性的信息论理解,可以应用于确定性的深度网络训练; -
基于这种理解提出一种新的泛化界,为下游监督学习任务提供了泛化保证; -
基于第一性原理得出了对不同 SSL 模型的见解,并强调了不同 SSL 变体的基本假设,使不同方法的比较成为可能,并为从业者提供了一般的指导; -
在分析基础上介绍了新的SSL方法,并从经验上验证了其优越性能。
一句话总结:
自监督学习方法可以通过信息论来理解,信息论提供了关于其构建、最优性和泛化保证的见解。
In this paper, we provide an information-theoretic (IT) understanding of self-supervised learning methods, their construction, and optimality. As a first step, we demonstrate how IT quantities can be obtained for deterministic networks, as an alternative to the commonly used unrealistic stochastic networks assumption. Secondly, we demonstrate how different SSL models can be (re)discovered based on first principles and highlight what the underlying assumptions of different SSL variants are. Third, we derive a novel generalization bound based on our IT understanding of SSL methods, providing generalization guarantees for the downstream supervised learning task. As a result of this bound, along with our unified view of SSL, we can compare the different approaches and provide general guidelines to practitioners. Consequently, our derivation and insights can contribute to a better understanding of SSL and transfer learning from a theoretical and practical perspective.
论文链接:https://openreview.net/forum?id=tuE-MnjN7DV
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢