
Learning ReLU networks to high uniform accuracy is intractable
J Berner, P Grohs, F Voigtlaender
[University of Vienna]
用ReLU网络达到一致的高精度是难以实现的
要点:
-
在 ReLU 网络的学习问题上达到高的统一精度是难以实现的; -
保证一个给定的统一精度所需的训练样本数量随着网络深度和输入维度呈指数级增长;
3、 当误差以 L8-norm 而不是 L2-norm 来衡量时,下界的限制就更大了; -
了解神经网络类的样本复杂性可以帮助设计更可靠的深度学习算法,并评估它们在安全关键场景中的局限性。
一句话总结:
由于所需的最小训练样本数呈指数级增长,特别是对于 L8-norm 来说,学习ReLU网络达到高的统一精度是难以实现的。
Statistical learning theory provides bounds on the necessary number of training samples needed to reach a prescribed accuracy in a learning problem formulated over a given target class. This accuracy is typically measured in terms of a generalization error, that is, an expected value of a given loss function. However, for several applications --- for example in a security-critical context or for problems in the computational sciences --- accuracy in this sense is not sufficient. In such cases, one would like to have guarantees for high accuracy on every input value, that is, with respect to the uniform norm. In this paper we precisely quantify the number of training samples needed for any conceivable training algorithm to guarantee a given uniform accuracy on any learning problem formulated over target classes containing (or consisting of) ReLU neural networks of a prescribed architecture. We prove that, under very general assumptions, the minimal number of training samples for this task scales exponentially both in the depth and the input dimension of the network architecture.
论文链接:https://openreview.net/forum?id=nchvKfvNeX0
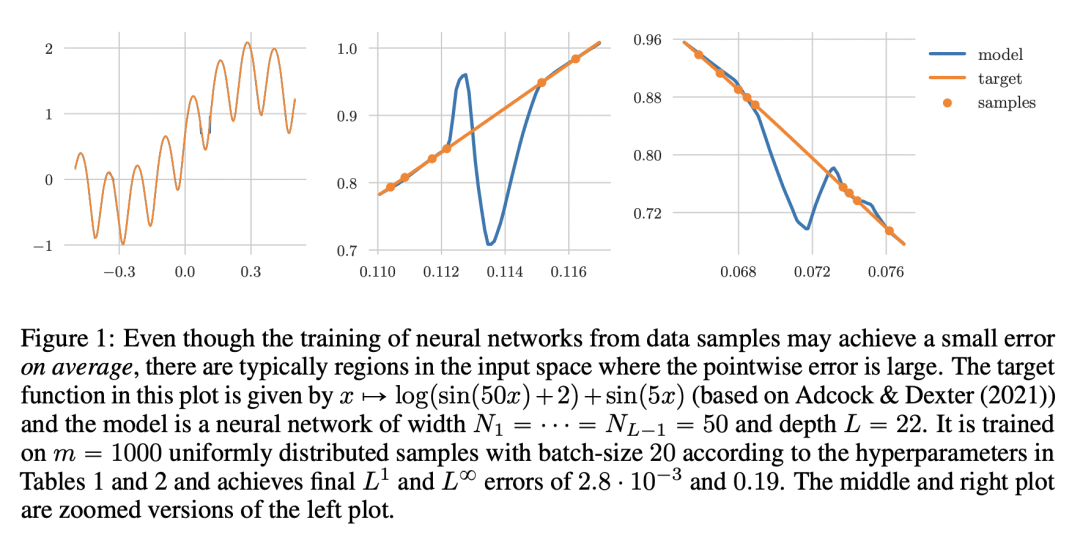
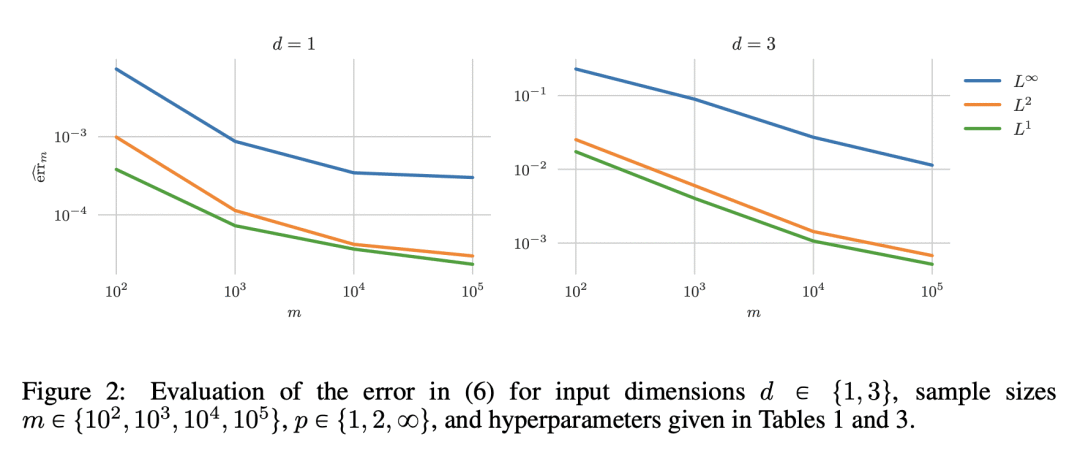
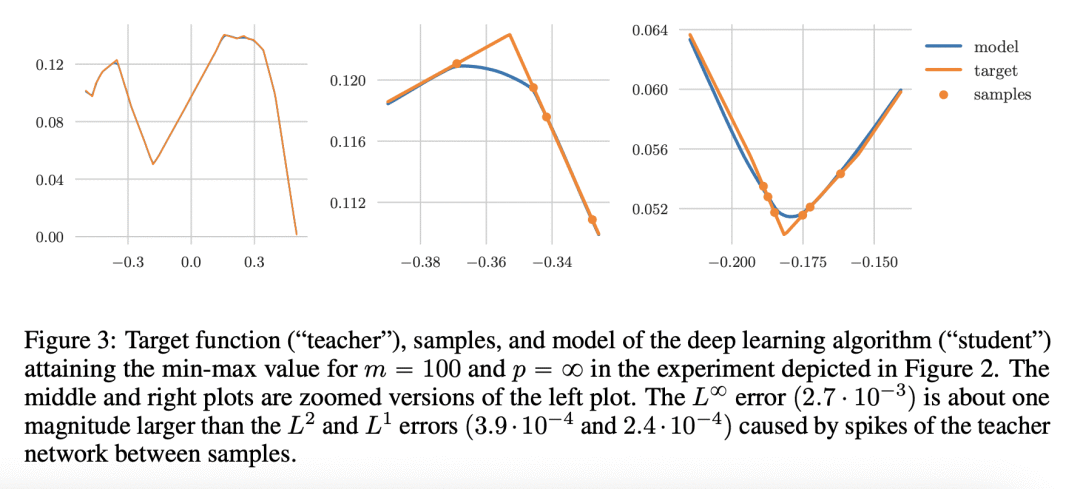
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢