
【论文标题】Weakly Supervised Content Selection for Improved Image Captioning 【弱监督+图像描述】选择弱监督内容用以提高图像字幕性能 【论坛网址】https://hub.baai.ac.cn/view/2443 【作者团队】Khyathi Raghavi Chandu, Piyush Sharma, Soravit Changpinyo, Ashish Thapliyal, Radu Soricut(CMU & Google) 【发表时间】2020/9/10 【论文链接】https://arxiv.org/abs/2009.05175
目前图像字幕模型没有明确地对相关语义概念进行建模,只是针对数据集给予的ground truth为最终目标进行训练模型,因此导致现有模型缺乏足够的可解释性和可控制性。
在Google & CMU联合团队最新发表的论文中,为了解决上述问题,作者将图像字幕任务分解成两个更加简单且可管理的任务(内容主干预测任务和基于内容主干字幕生成任务)。对于内容主干预测任务,作者使用现成的简单语言语法解析器,不需要额外的人工注释。对于基于内容主干字幕生成任务,作者使用已有的内容主干信息在编码器,解码器上进行模态对齐(如图),增加模型的语义信息进行训练。
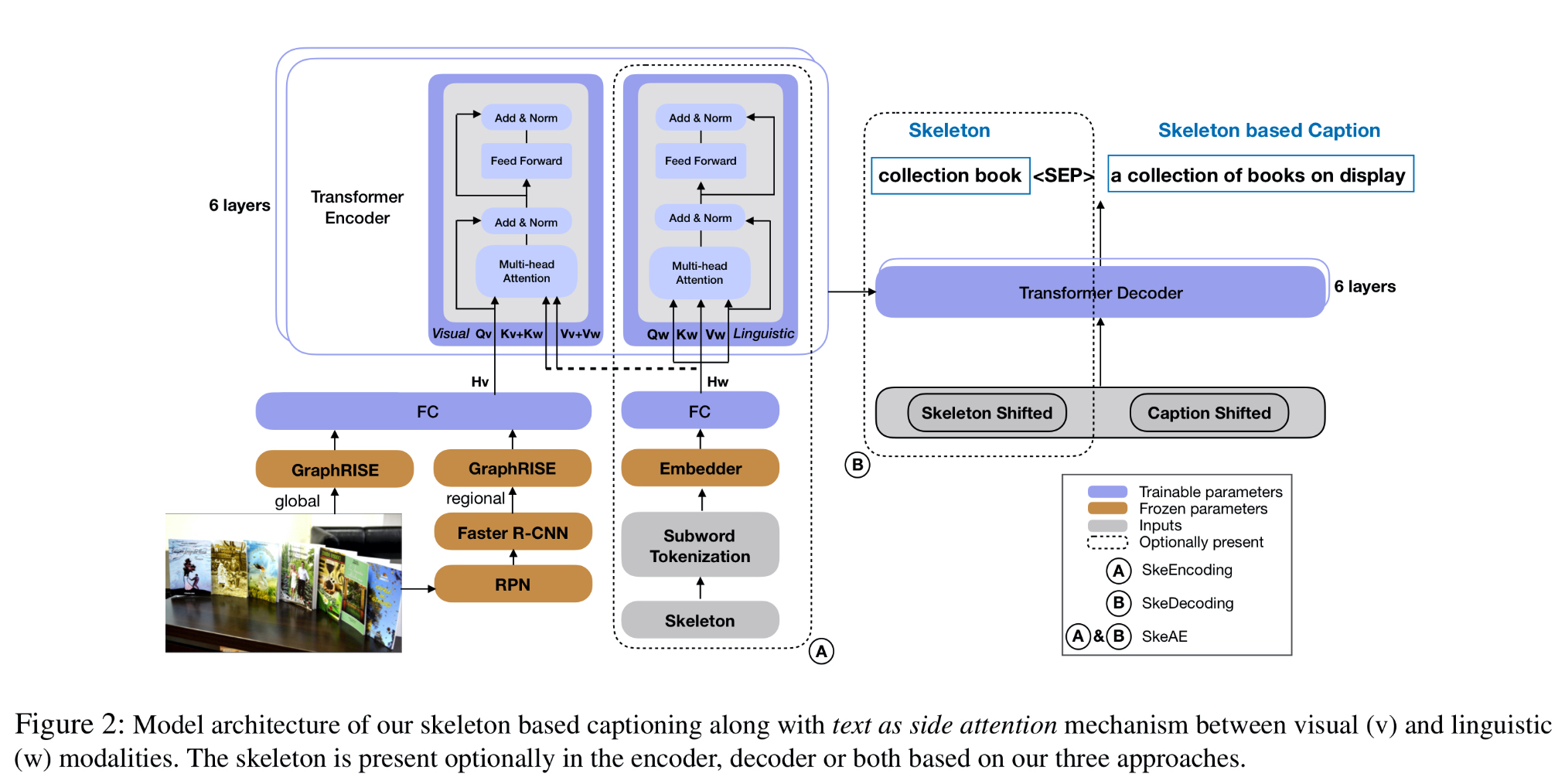
该模型可以在非数据集内的测试图像上生成更好质量的字幕,同时该模型在其他语言(包括法语,意大利语,德语,西班牙语和印度语)也有比较好的表现,模型在未配对图像字幕上取得了比现有方法更好的效果,具有比较好的泛化性。此外,此模型还可以根据内容主干当作旋钮来控制生成图像字幕的一些属性(长度,内容或者性别)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢