
VQ3D: Learning a 3D-Aware Generative Model on ImageNet
K Sargent, J Y Koh, H Zhang, H Chang, C Herrmann, P Srinivasan, J Wu, D Sun
[Stanford University & CMU & Google Research]
VQ3D: ImageNet上的3D感知生成模型学习
要点:
-
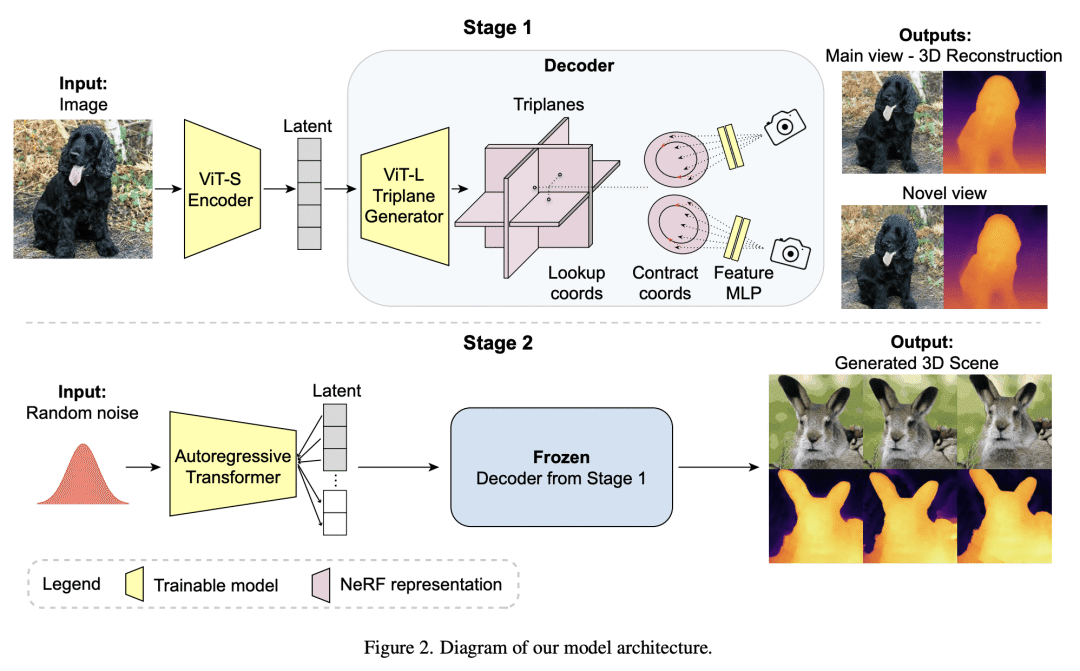
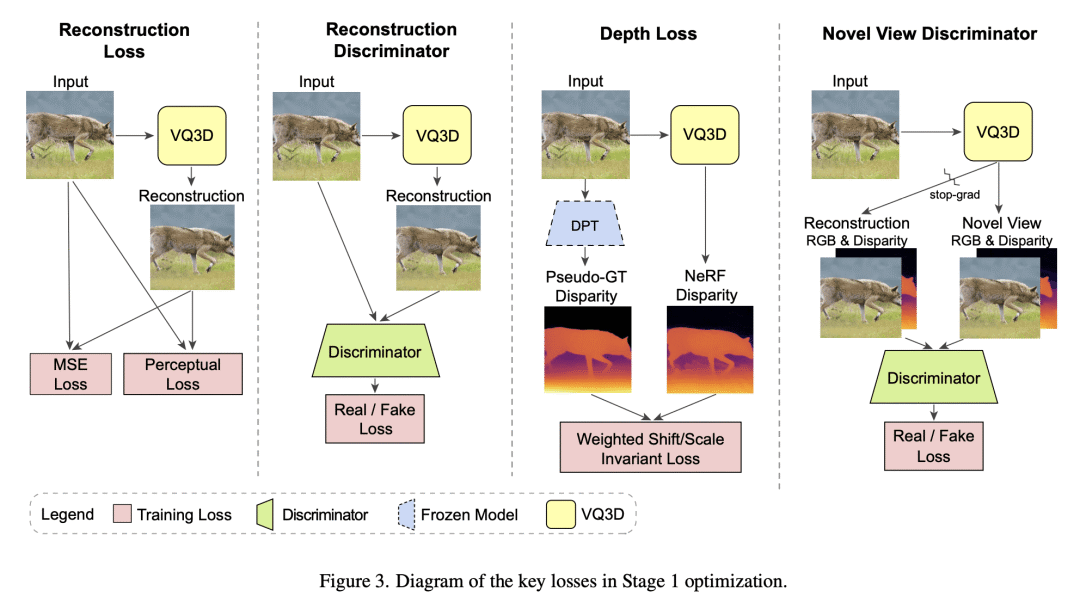
VQ3D 将基于 NeRF 的解码器引入到两阶段矢量量化自编码器中,以建模多样化无约束图像集,如ImageNet; -
VQ3D 实现了 16.8 的 ImageNet 生成 FID 得分,而次好的基线方法为 69.8; -
VQ3D 不需要为每个数据集或真实姿态调整姿态超参数,在训练中可利用伪深度估计器; -
VQ3D 的第1阶段能实现3D感知图像编辑和操纵。
一句话总结:
VQ3D 将基于 NeRF 的解码器引入到两阶段矢量量化自编码器中,以建模多样化无约束图像集合,如 ImageNet,并实现了 ImageNet 生成 FID 得分 16.8,而次好的基线方法为 69.8。
Recent work has shown the possibility of training generative models of 3D content from 2D image collections on small datasets corresponding to a single object class, such as human faces, animal faces, or cars. However, these models struggle on larger, more complex datasets. To model diverse and unconstrained image collections such as ImageNet, we present VQ3D, which introduces a NeRF-based decoder into a two-stage vector-quantized autoencoder. Our Stage 1 allows for the reconstruction of an input image and the ability to change the camera position around the image, and our Stage 2 allows for the generation of new 3D scenes. VQ3D is capable of generating and reconstructing 3D-aware images from the 1000-class ImageNet dataset of 1.2 million training images. We achieve an ImageNet generation FID score of 16.8, compared to 69.8 for the next best baseline method.
https://arxiv.org/abs/2302.06833

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢