
Text-driven Visual Synthesis with Latent Diffusion Prior
T Liao, S Ge, Y Xu, Y Lee, B AlBahar, J Huang
[University of Maryland]
基于潜扩散先验的文本驱动视觉合成
要点:
-
将扩散模型用来作为视觉合成任务的先验;
-
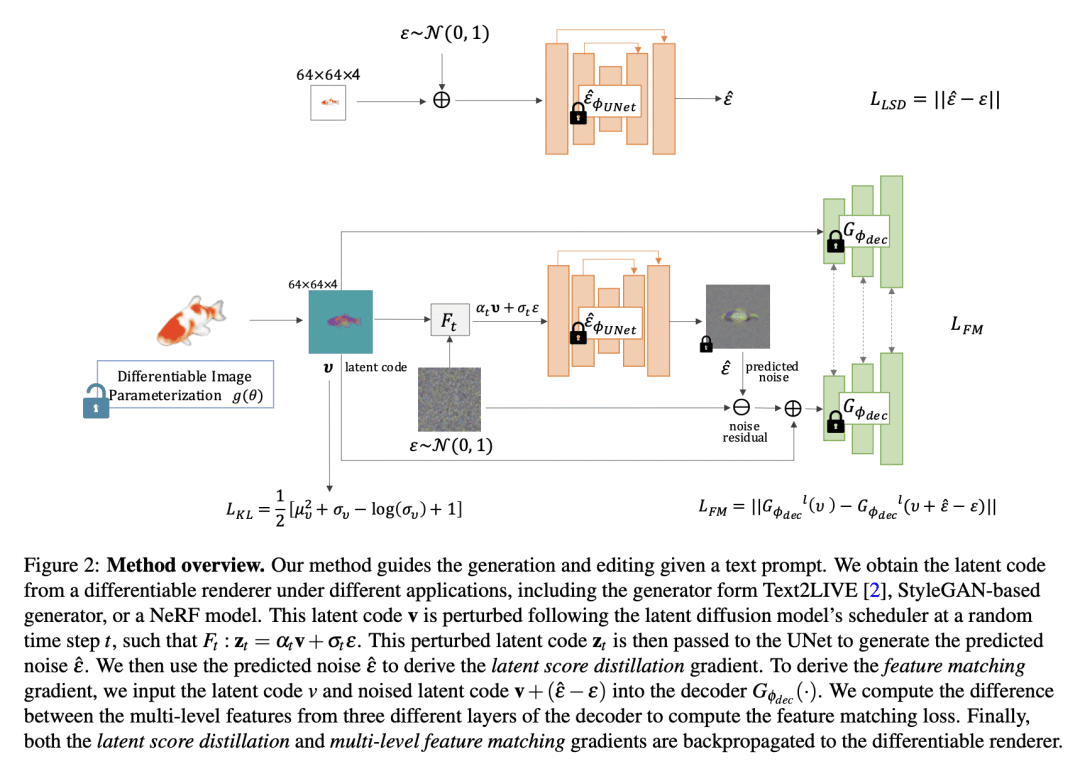
提出一种特征匹配损失,以从解码器中提取详细信息来指导基于文本的视觉合成任务;
3。 提出一种 KL 损失来正则化优化潜空间,稳定优化过程; -
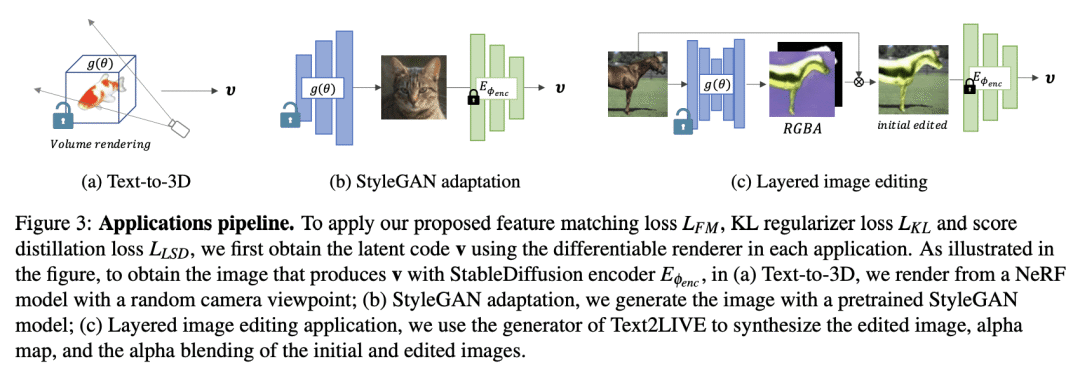
广泛的实验评估表明,在文本到3D、StyleGAN自适应和分层图像编辑任务上,具有很强的基线竞争结果。
一句话总结:
提出了一种框架,将扩散模型作为视觉合成任务的先验,与强基线相比,提高了质量。
There has been tremendous progress in large-scale text-to-image synthesis driven by diffusion models enabling versatile downstream applications such as 3D object synthesis from texts, image editing, and customized generation. We present a generic approach using latent diffusion models as powerful image priors for various visual synthesis tasks. Existing methods that utilize such priors fail to use these models' full capabilities. To improve this, our core ideas are 1) a feature matching loss between features from different layers of the decoder to provide detailed guidance and 2) a KL divergence loss to regularize the predicted latent features and stabilize the training. We demonstrate the efficacy of our approach on three different applications, text-to-3D, StyleGAN adaptation, and layered image editing. Extensive results show our method compares favorably against baselines.


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢