
在回答复杂的问题时,人类可以理解不同模态的信息,并形成一个完整的思维链(Chain of Thought, CoT)。深度学习模型是否可以打开「黑箱」,对其推理过程提供一个思维链呢?
近日,UCLA 和艾伦人工智能研究院(AI2)提出了首个标注详细解释的多模态科学问答数据集 ScienceQA,用于测试模型的多模态推理能力。在 ScienceQA 任务中,作者提出 GPT-3 (CoT) 模型,即在 GPT-3 模型中引入基于思维链的提示学习,从而使得模型能在生成答案的同时,生成相应的推理解释。GPT-3 (CoT) 在 ScienceQA 上实现了 75.17% 的准确率;并且人类评估表明,其可以生成较高质量的解释。
作者收集了全新的科学问答数据集 ScienceQA,它包含了 21,208 道来自中小学科学课程的问答多选题。一道典型的问题包含多模态的背景(context)、正确的选项、通用的背景知识(lecture)以及具体的解释(explanation)。
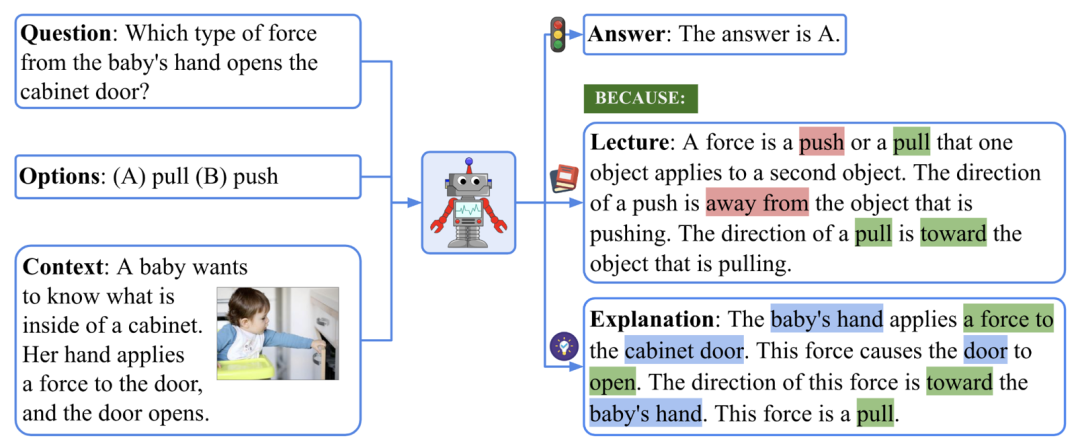
▲ ScienceQA 数据集的一个例子
要回答上图所示的例子,我们首先要回忆关于力的定义:「A force is a push or a pull that ... The direction of a push is ... The direction of a pull is ... 」,然后形成一个多步的推理过程:「The baby’s hand applies a force to the cabinet door. → This force causes the door to open. → The direction of this force is toward the baby’s hand. 」,最终得到正确答案:「This force is a pull. 」。
在 ScienceQA 任务中,模型需要在预测答案的同时输出详细地解释。在本文中,作者利用大规模语言模型生成背景知识和解释,作为一种思维链(CoT)来模仿人类具有的多步推理能力。
实验表明,目前的多模态问答方法在 ScienceQA 任务不能取得很好的表现。相反,通过基于思维链的提示学习,GPT-3 模型能在 ScienceQA 数据集上取得 75.17% 的准确率,同时可以生成质量较高的解释:根据人类评估,其中 65.2% 的解释相关、正确且完整。思维链也可以帮助 UnifiedQA 模型在 ScienceQA 数据集上取得 3.99% 的提升。
论文标题:
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering
论文链接:
https://arxiv.org/abs/2209.09513
项目主页:
代码链接:
https://github.com/lupantech/ScienceQA
数据可视化:
https://scienceqa.github.io/explore.html
Leaderboard:
https://scienceqa.github.io/leaderboard.html
当前最好的 VQA 模型之一的 VisualBERT 只能达到 61.87% 的准确率。在训练的过程引入 CoT 数据,UnifiedQA_BASE 模型可以实现 74.11% 的准确率。而 GPT-3 (CoT) 在 2 个训练例子的提示下,实现了 75.17% 的准确率,高于其它基准模型。人类在 ScienceQA 数据集上表现优异,可以达到 88.40% 的总体准确率,并且在不同类别的问题上表现稳定。
论文解析请访问原文https://mp.weixin.qq.com/s/uVzkYVONexWceItdeo2lUw
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢