
Is margin all you need? An extensive empirical study of active learning on tabular data
D Bahri, H Jiang, T Schuster, A Rostamizadeh
[Google]
边际采样表格数据主动学习实证研究
要点:
-
主动学习的目的是从未标记数据集合中找出最佳的未标记点进行标记; -
研究分析了各种主动学习算法在 OpenML-CC18 基准的 69 个真实世界表格分类数据集上训练的深度神经网络的性能; -
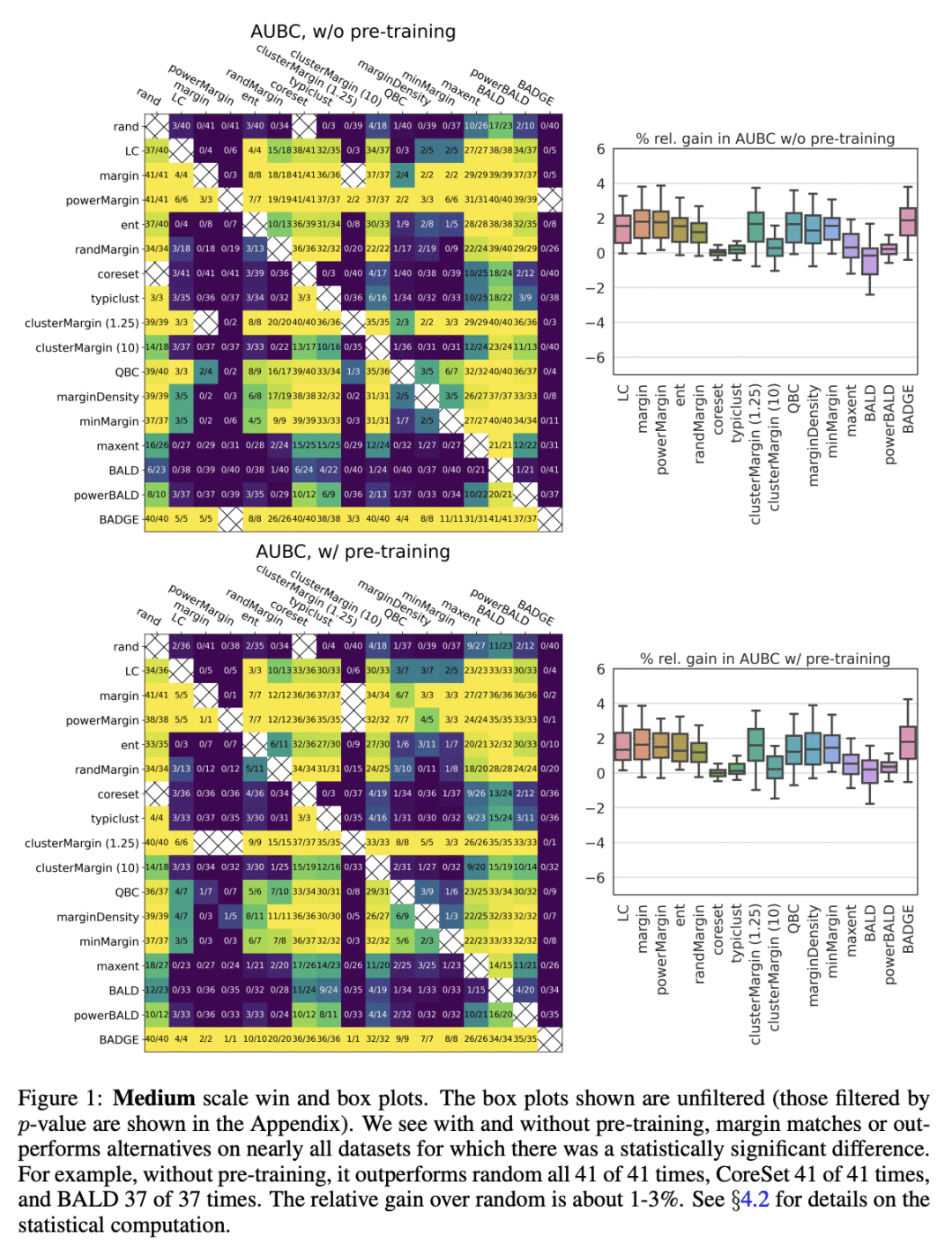
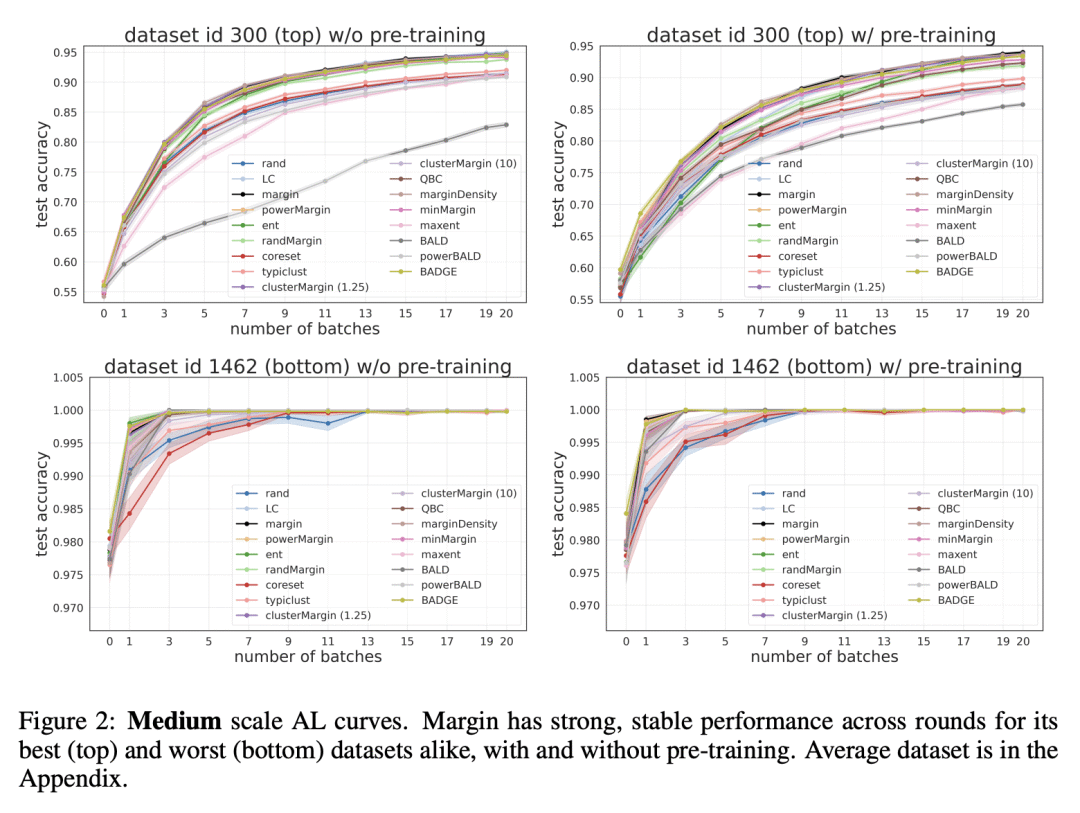
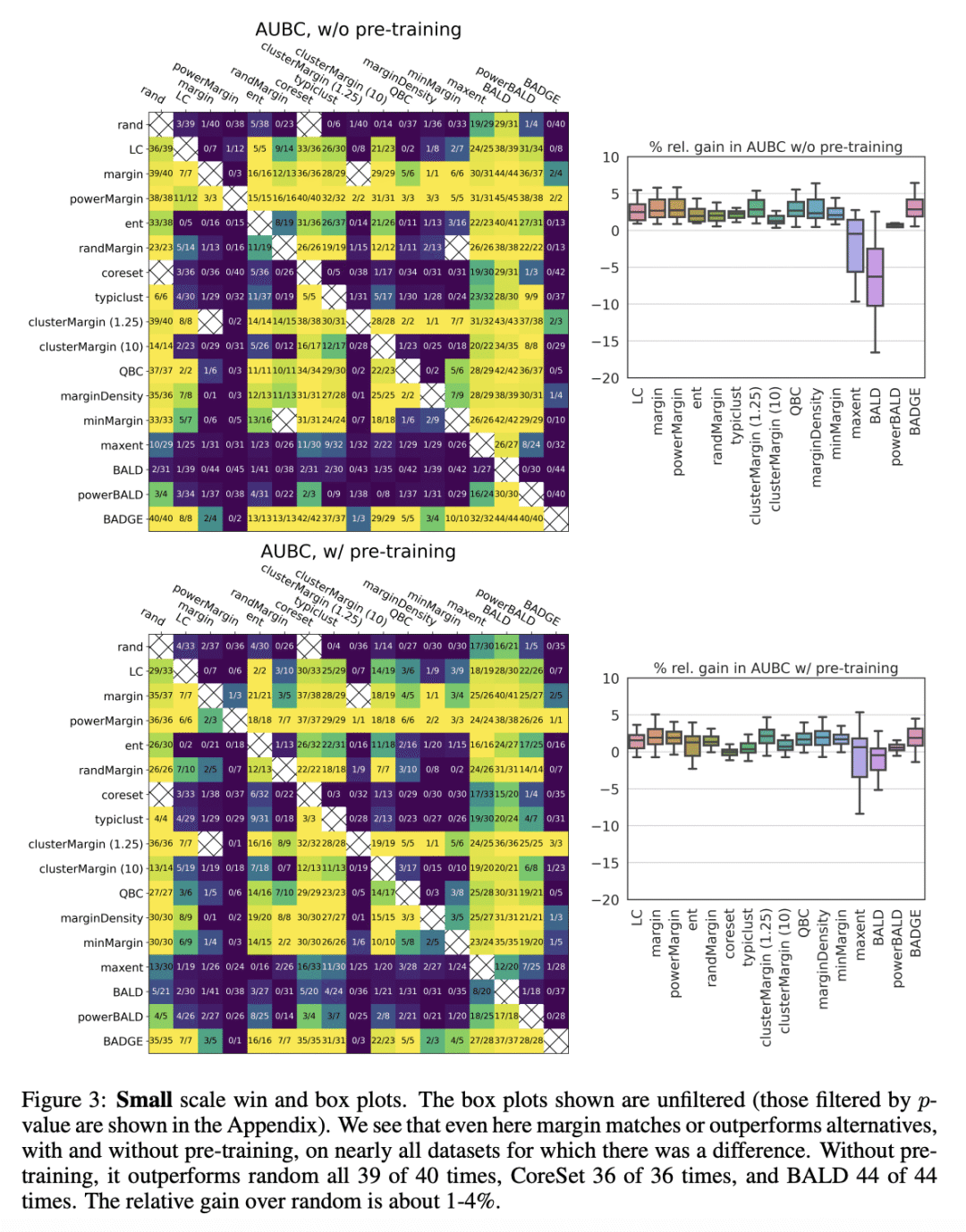
在广泛的实验环境中,边际采样与所有其他包括最先进的主动学习方法相匹配或更好; -
结果表明,对于面临数据标记受限的从业者来说,边际采样是一种强大而有效的免超参数方法。
一句话总结:
边际采样是一种免超参数的主动学习技术,在表格数据上与最先进的方法相匹配或更好。
Given a labeled training set and a collection of unlabeled data, the goal of active learning (AL) is to identify the best unlabeled points to label. In this comprehensive study, we analyze the performance of a variety of AL algorithms on deep neural networks trained on 69 real-world tabular classification datasets from the OpenML-CC18 benchmark. We consider different data regimes and the effect of self-supervised model pre-training. Surprisingly, we find that the classical margin sampling technique matches or outperforms all others, including current state-of-art, in a wide range of experimental settings. To researchers, we hope to encourage rigorous benchmarking against margin, and to practitioners facing tabular data labeling constraints that hyper-parameter-free margin may often be all they need.
论文链接:https://openreview.net/forum?id=wXdEKf5mV6N

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢