
TEMPERA: Test-Time Prompt Editing via Reinforcement Learning
T Zhang, X Wang, D Zhou, D Schuurmans, J E Gonzalez
[Google & UC Berkeley]
TEMPERA: 基于强化学习的测试时提示编辑
要点:
-
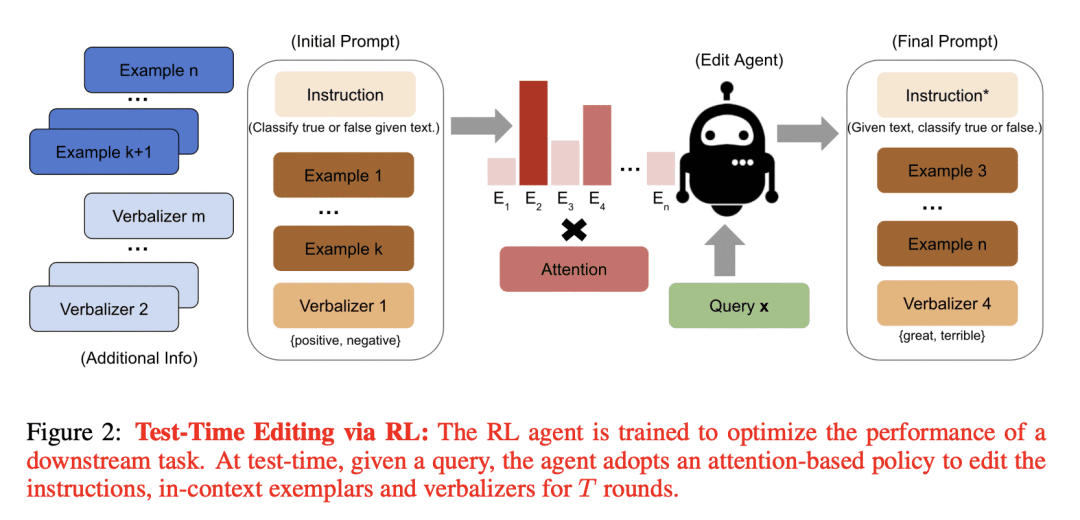
TEMPERA 是一种新的大型语言模型测试时提示编辑方法,可有效地利用先验知识并自适应不同的查询; -
TEMPERA 与最近的 SoTA 方法(如提示微调、AutoPrompt 和 RLPrompt)相比,在各种任务中取得了显著的收益; -
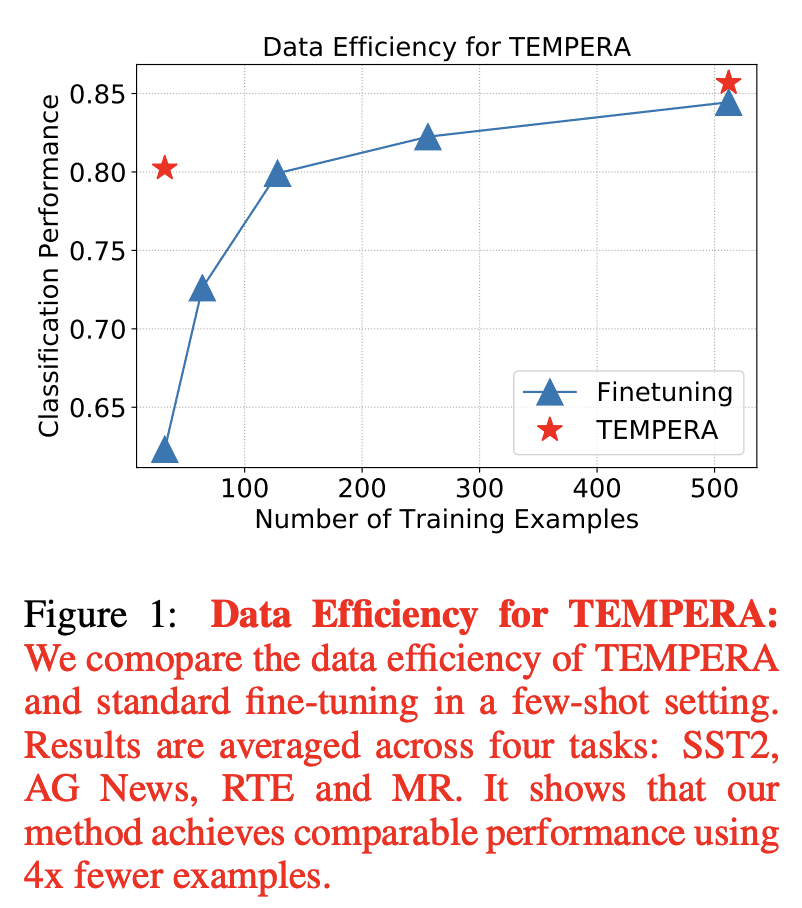
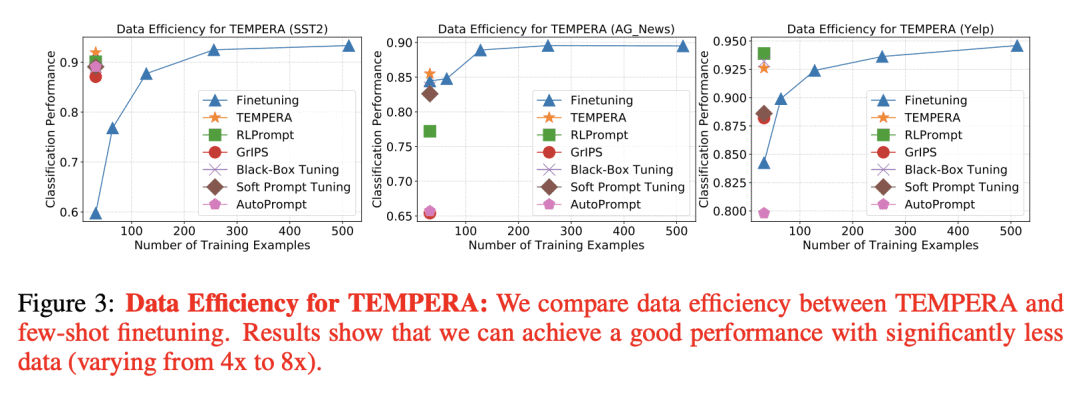
与传统微调方法相比,TEMPERA 实现了平均 5.33 倍的采样效率提升; -
所提方法为每个查询提供了一个可解释的提示,并且可以很容易地纳入人工的先验知识。
一句话总结:
TEMPERA 是一种针对大型语言模型的测试时提示编辑方法,有效利用了先验知识,能自适应不同查询,并为每个查询提供可解释的提示。
Careful prompt design is critical to the use of large language models in zero-shot or few-shot learning. As a consequence, there is a growing interest in automated methods to design optimal prompts. In this work, we propose Test-time Prompt Editing using Reinforcement learning (TEMPERA). In contrast to prior prompt generation methods, TEMPERA can efficiently leverage prior knowledge, is adaptive to different queries and provides an interpretable prompt for every query. To achieve this, we design a novel action space that allows flexible editing of the initial prompts covering a wide set of commonly-used components like instructions, few-shot exemplars, and verbalizers. The proposed method achieves significant gains compared with recent SoTA approaches like prompt tuning, AutoPrompt, and RLPrompt, across a variety of tasks including sentiment analysis, topic classification, natural language inference, and reading comprehension. Our method achieves 5.33x on average improvement in sample efficiency when compared to the traditional fine-tuning methods.
论文链接:https://openreview.net/forum?id=gSHyqBijPFO
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢