
NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion
Jiatao Gu, Alex Trevithick, Kai-En Lin, Josh Susskind, Christian Theobalt, Lingjie Liu, Ravi Ramamoorthi
Apple & University of California & Max Planck Institute for Informatics & University of Pennsylvania.
NerfDiff:基于NeRF引导的3D感知扩散蒸馏的单图像视图合成
要点:
1.从单个图像进行新颖的视图合成需要推断对象和场景的遮挡区域,同时保持与输入的语义和物理一致性。现有方法在局部图像特征上调节神经辐射场(NeRF),将点投影到输入图像平面,并聚合2D特征以执行体绘制。然而,在严重遮挡的情况下,该投影无法解决不确定性,导致缺少细节的模糊渲染。
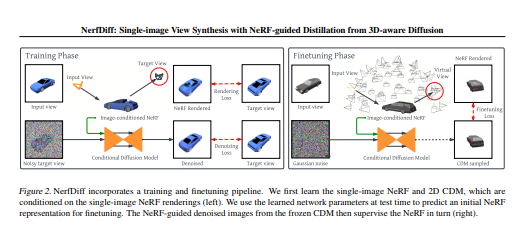
2. 在这项工作中提出了NerfDiff,它通过在测试时合成和细化一组虚拟视图,将3D感知条件扩散模型(CDM)的知识提取到NeRF中来解决这个问题。
- 我们开发了一个新的框架——NerfDiff,它联合学习图像调节的NeRF和CDM,并在测试时使用多视图一致扩散过程微调学习的NeRF。
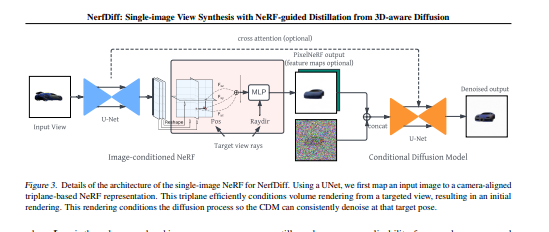
- 引入了基于相机对齐三平面的高效图像调节NeRF表示,这是实现CDM高效渲染和微调的核心组件。
- 提出了一种3D感知CDM,它将体积渲染集成到2D扩散模型中,有助于将其推广到新视图。
一句话总结:
提出了一种新的NeRF引导蒸馏算法,该算法同时从CDM样本生成3D一致的虚拟视图,并基于改进的虚拟视图微调NeRF。该方法在具有挑战性的数据集(包括ShapeNet、ABO和Clever3D)上显著优于现有的基于NeRF和无几何体的方法。[机器翻译+人工校对]
Novel view synthesis from a single image requires inferring occluded regions of objects and scenes whilst simultaneously maintaining semantic and physical consistency with the input. Existing approaches condition neural radiance fields (NeRF) on local image features, projecting points to the input image plane, and aggregating 2D features to perform volume rendering. However, under severe occlusion, this projection fails to resolve uncertainty, resulting in blurry renderings that lack details. In this work, we propose NerfDiff, which addresses this issue by distilling the knowledge of a 3D-aware conditional diffusion model (CDM) into NeRF through synthesizing and refining a set of virtual views at test time. We further propose a novel NeRF-guided distillation algorithm that simultaneously generates 3D consistent virtual views from the CDM samples, and finetunes the NeRF based on the improved virtual views. Our approach significantly outperforms existing NeRF-based and geometry-free approaches on challenging datasets, including ShapeNet, ABO, and Clevr3D.
https://arxiv.org/pdf/2302.10109.pdf


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢