
Effective Data Augmentation With Diffusion Models
Brandon Trabucco, Kyle Doherty, Max Gurinas, Ruslan Salakhutdinov
Carnegie Mellon University & MPG Ranch & Northern Arizona University & University of Chicago Laboratory Schools.
扩散模型的有效数据扩充
要点:
1.数据增强是深度学习中最流行的工具之一,支持了许多最近的进步,包括分类、生成模型和表示学习。数据扩充的标准方法结合了旋转和翻转等简单变换,从现有图像生成新图像。然而,这些新图像在数据中存在的关键语义轴上缺乏多样性。考虑一下识别不同动物的任务。当前的扩充无法在任务相关的高级语义属性(如动物的种类)中产生多样性。
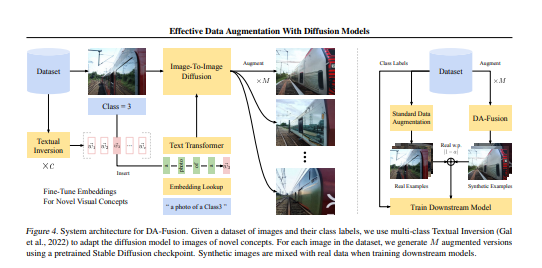
2.本文通过预先训练的文本到图像扩散模型参数化的图像到图像转换来解决数据增强中的多样性不足。
- 该策略使用文本到图像扩散模型(DA Fusion)生成真实图像的变化。
- 该方法通过在表示新颖视觉概念的文本编码器中插入和微调新标记,使扩散模型适应新域。DAFusion以尊重对象级视觉不变量的方式修改前景对象和背景的外观。
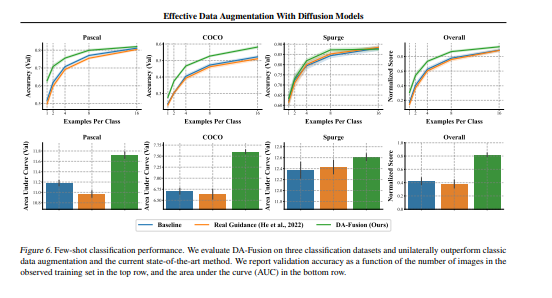
- 在三个少数镜头图像分类任务上测试了该方法,包括一个不属于扩散模型词汇的真实世界杂草识别任务。DA Fusion将数据增强提高了+10个百分点,消融证实了我们的方法对超参数分配的鲁棒性。DA Fusion代码发布于:https://github.com/brandontrabucco/da-fusion
一句话总结:
使用现成的扩散模型编辑图像以改变其语义,并从几个标记的示例中概括为新颖的视觉概念。我们评估了我们在几个镜头设置下的图像分类任务和现实世界中的杂草识别任务的方法,并观察到测试域中准确性的提高。[机器翻译+人工校对]
Data augmentation is one of the most prevalent tools in deep learning, underpinning many recent advances, including those from classification, generative models, and representation learning. The standard approach to data augmentation combines simple transformations like rotations and flips to generate new images from existing ones. However, these new images lack diversity along key semantic axes present in the data. Consider the task of recognizing different animals. Current augmentations fail to produce diversity in task-relevant high-level semantic attributes like the species of the animal. We address the lack of diversity in data augmentation with image-to-image transformations parameterized by pre-trained text-to-image diffusion models. Our method edits images to change their semantics using an off-the-shelf diffusion model, and generalizes to novel visual concepts from a few labelled examples. We evaluate our approach on image classification tasks in a few-shot setting, and on a real-world weed recognition task, and observe an improvement in accuracy in tested domains.
https://arxiv.org/pdf/2302.07944.pdf


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢