
ChatGPT: Jack of all trades, master of none
Jan Kocoč,Igor Cicheki,Oliwier Kaszyca,Mateusz Kochanek,Dominika Szydło,Joanna Baran,Julita Bielaniewicz
ChatGPT:ChatGPT:样样都会,门门不精
要点:
1.OpenAI发布了聊天生成预训练转换器(ChatGPT),并彻底改变了人工智能与人类模型交互的方法。与聊天机器人的第一次接触揭示了它在各个领域提供详细准确答案的能力。有一些关于ChatGPT评估的出版物,测试了它在著名的自然语言处理(NLP)任务上的有效性。然而,现有的研究大多是非自动化的,测试规模非常有限。
2.在这项工作中,论文检查了ChatGPT在25项不同的分析NLP任务上的能力,其中大多数任务甚至对人来说都是主观的,例如情绪分析、情绪识别、攻击和立场检测、自然语言推理、词义消歧、语言可接受性和问题回答。自动化了ChatGPT的查询过程,并分析了超过38k个响应。
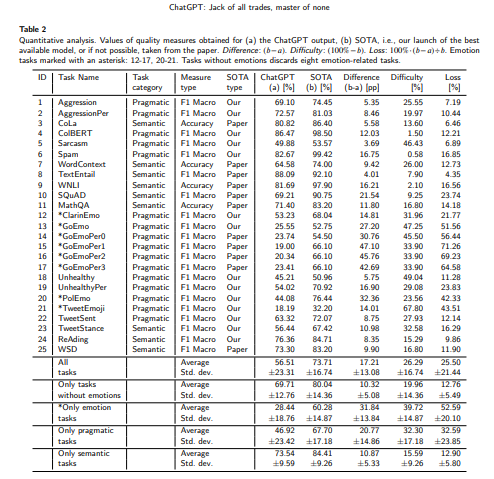
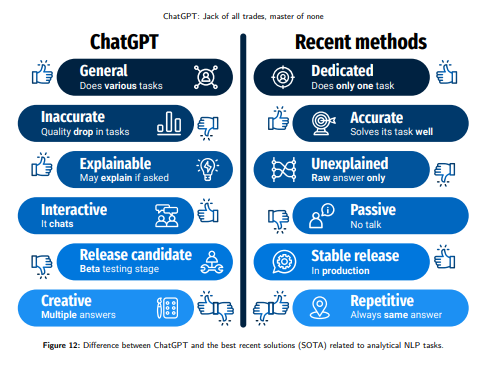
3.将其结果与现有的技术状态(SOTA)解决方案进行比较,ChatGPT模型的平均质量损失约为零炮和少炮评估的25%。文章发现任务越困难(SOTA性能越低),ChatGPT损失越高。它特别涉及诸如情感识别之类的语用NLP问题。另外,还测试了通过随机上下文少镜头个性化对选定主观任务的ChatGPT响应进行个性化的能力,获得了明显更好的基于用户的预测。额外的定性分析揭示了ChatGPT偏见,很可能是由于OpenAI对人类训练者施加的规则。
一句话总结:
我们的结果为基本讨论提供了基础,即最近的预测NLP模型的高质量是否可以表明工具对社会的有用性,以及如何建立此类系统的学习和验证程序。[机器翻译+人工校对]
OpenAI has released the Chat Generative Pre-trained Transformer (ChatGPT) and revolutionized the approach in artificial intelligence to human-model interaction. The first contact with the chatbot reveals its ability to provide detailed and precise answers in various areas. There are several publications on ChatGPT evaluation, testing its effectiveness on well-known natural language processing (NLP) tasks. However, the existing studies are mostly non-automated and tested on a very limited scale. In this work, we examined ChatGPT's capabilities on 25 diverse analytical NLP tasks, most of them subjective even to humans, such as sentiment analysis, emotion recognition, offensiveness and stance detection, natural language inference, word sense disambiguation, linguistic acceptability and question answering. We automated ChatGPT's querying process and analyzed more than 38k responses. Our comparison of its results with available State-of-the-Art (SOTA) solutions showed that the average loss in quality of the ChatGPT model was about 25% for zero-shot and few-shot evaluation. We showed that the more difficult the task (lower SOTA performance), the higher the ChatGPT loss. It especially refers to pragmatic NLP problems like emotion recognition. We also tested the ability of personalizing ChatGPT responses for selected subjective tasks via Random Contextual Few-Shot Personalization, and we obtained significantly better user-based predictions. Additional qualitative analysis revealed a ChatGPT bias, most likely due to the rules imposed on human trainers by OpenAI. Our results provide the basis for a fundamental discussion of whether the high quality of recent predictive NLP models can indicate a tool's usefulness to society and how the learning and validation procedures for such systems should be established.
https://arxiv.org/pdf/2302.10724.pdf

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢