
Language Is Not All You Need: Aligning Perception with Language Models
Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Qiang Liu, Kriti Aggarwal, Zewen Chi,Johan Bjorck, Vishrav Chaudhary, Subhojit Som, Xia Song, Furu Wei
Microsoft
语言不是你所需要的一切:使感知与语言模型相一致
要点:
1.语言、多模态感知、动作和世界建模的大融合是迈向人工通用智能的关键一步。在这项工作中,介绍了Kosmos-1,这是一种多模态大型语言模型(MLLM),它可以感知一般模态,在上下文中学习(即,少数镜头),并遵循指令(即,零镜头)。
2.具体来说,在网络规模的多模态语料库上从头开始训练Kosmos-1,包括任意交错的文本和图像、图像标题对和文本数据。在没有任何梯度更新或微调的情况下,评估各种设置,包括零镜头、少镜头和多模式思维链提示。
关键要点如下:
- 从LLM到MLLM。正确处理感知是迈向人工通用智能的必要步骤。感知多模态输入的能力对LLM至关重要。首先,多模态感知使LLM能够获得文本描述之外的常识知识。第二,将感知与LLM相结合,为机器人和文档智能等新任务打开了大门。第三,感知能力统一了各种API,因为图形用户界面是最自然、最统一的交互方式。例如,MLLM可以直接读取屏幕或从收据中提取数字。我们在网络规模的多模态语料库上训练KOSMOS-1模型,这确保了模型能够从不同的来源中稳健地学习。我们不仅使用大规模的文本语料库,而且还从网络中挖掘高质量的图像字幕对和任意交错的图像和文本文档。
- 作为通用接口的语言模型。遵循METALM[HSD+22]中提出的理念,我们将语言模型视为通用任务层。由于开放的输出空间,我们能够将各种任务预测统一为文本。此外,自然语言指令和动作序列(如编程语言)可以由语言模型很好地处理。LLM还充当基本推理器[WWS+22],这是对复杂任务的感知模块的补充。因此,将世界、行动和多模态感知与通用界面(即语言模型)联系起来是很自然的。
- MLLM的新功能。如表1所示,除了以前的LLM[BMR+20,CND+22]中发现的功能外,MLLM还提供了新的用途和可能性。首先,可以通过使用自然语言指令和演示示例进行零镜头和少镜头多模式学习。第二,我们通过评估瑞文智商测试(Raven IQ test)来观察非言语推理的潜在信号,该测试衡量人类的流畅推理能力。第三,MLLM自然支持通用模式的多回合互动,如多模式对话。
一句话总结:
实验结果表明,Kosmos-1在(i)语言理解、生成,甚至无OCR NLP(直接输入文档图像),(ii)感知语言任务,包括多模态对话、图像字幕、视觉问题解答,以及(iii)视觉任务,例如具有描述的图像识别(通过文本指令指定分类)。还表明,MLLM可以受益于跨模态转移,即将知识从语言转移到多模态,以及从多模态转移到语言。此外,我们介绍了Raven IQ测试的数据集,该数据集诊断MLLM的非言语推理能力。[机器翻译+人工校对]
A big convergence of language, multimodal perception, action, and world modeling is a key step toward artificial general intelligence. In this work, we introduce Kosmos-1, a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot). Specifically, we train Kosmos-1 from scratch on web-scale multimodal corpora, including arbitrarily interleaved text and images, image-caption pairs, and text data. We evaluate various settings, including zero-shot, few-shot, and multimodal chain-of-thought prompting, on a wide range of tasks without any gradient updates or finetuning. Experimental results show that Kosmos-1 achieves impressive performance on (i) language understanding, generation, and even OCR-free NLP (directly fed with document images), (ii) perception-language tasks, including multimodal dialogue, image captioning, visual question answering, and (iii) vision tasks, such as image recognition with descriptions (specifying classification via text instructions). We also show that MLLMs can benefit from cross-modal transfer, i.e., transfer knowledge from language to multimodal, and from multimodal to language. In addition, we introduce a dataset of Raven IQ test, which diagnoses the nonverbal reasoning capability of MLLMs.
https://arxiv.org/pdf/2302.14045.pdf


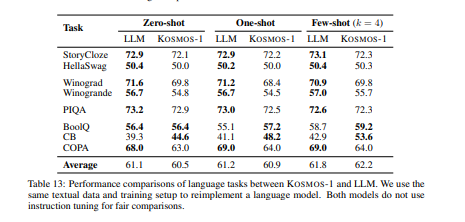
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢