
Differentially Private Diffusion Models Generate Useful Synthetic Images
Sahra Ghalebikesabi, Leonard Berrada, Sven Gowal, Ira Ktena, Robert Stanforth, Jamie Hayes, Soham De,
差异隐私扩散模型生成有用的合成图像
要点:
1.生成敏感图像数据集的隐私保护合成版本的能力可以解锁目前受数据可用性限制的众多 ML 应用程序。 由于其惊人的图像生成质量,扩散模型是生成高质量合成数据的主要候选者。 然而,最近的研究发现,默认情况下,一些扩散模型的输出不保护训练数据的隐私。
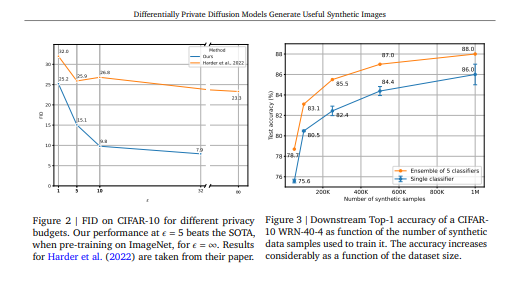
2.通过私下微调具有超过 80M 参数的 ImageNet 预训练扩散模型,在 CIFAR-10 和 Camelyon17 上获得了 FID 和在合成数据上训练的下游分类器的准确性方面的 SOTA 结果。 将 CIFAR-10 上的 SOTA FID 从 26.2 降低到 9.8,并将准确度从 51.0% 提高到 88.0%。 在来自 Camelyon17 的合成数据上,实现了 91.1% 的下游准确率,这接近于在真实数据上训练时的 96.5% 的 SOTA。 我们利用生成模型的能力来创建无限量的数据以最大化下游预测性能,并进一步展示如何使用合成数据进行超参数调整。
- 证明扩散模型可以通过差分隐私进行训练,达到足够的质量,我们可以仅基于合成数据创建准确的分类器。 为此,我们利用预训练,并且即使在预训练和微调数据集之间存在显着的分布变化时,我们也展示了最先进的改进。
- 我们提出对现有方法进行简单实用的改进,以进一步提高模型的性能。 即,我们在使用时同时使用图像和时间步长增强增强多重性,我们偏置扩散时间步采样,以鼓励学习扩散过程中最具挑战性的阶段。
- 通过这种方法,在 CIFAR-10 上微调了一个具有超过 8000 万个参数的差分隐私扩散模型,并且比之前的最先进技术提高了 50% 以上,降低了 Fréchet Inception Divergence (FID) 从 26.8 到 9.8。 此外,我们在 Camelyon17 数据集中可用的淋巴结组织的组织病理学扫描上私下微调了相同的模型,并表明在该模型生成的合成数据上训练的分类器达到了 91.1% 的准确度(WILDS 排行榜上报告的最高准确度(Koh et al., 2021) 对于在真实数据上训练的非私有模型来说是 96.5%)。
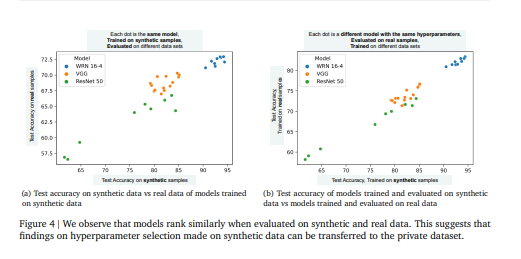
- 我们证明,通过利用更大的合成数据集和集成,可以在很大程度上进一步提高下游分类器的准确性,而无需额外的隐私成本。最后,展示了在合成数据上调整下游分类器的超参数揭示了在直接调整私有数据集时也反映出来的趋势。
一句话总结:结果表明,使用差分隐私进行微调的扩散模型可以产生有用且可证明私有的合成数据,即使在预训练和微调分布之间存在显着分布变化的应用程序中也是如此。[机器翻译+人工校对]
The ability to generate privacy-preserving synthetic versions of sensitive image datasets could unlock numerous ML applications currently constrained by data availability. Due to their astonishing image generation quality, diffusion models are a prime candidate for generating high-quality synthetic data. However, recent studies have found that, by default, the outputs of some diffusion models do not preserve training data privacy. By privately fine-tuning ImageNet pre-trained diffusion models with more than 80M parameters, we obtain SOTA results on CIFAR-10 and Camelyon17 in terms of both FID and the accuracy of downstream classifiers trained on synthetic data. We decrease the SOTA FID on CIFAR-10 from 26.2 to 9.8, and increase the accuracy from 51.0% to 88.0%. On synthetic data from Camelyon17, we achieve a downstream accuracy of 91.1% which is close to the SOTA of 96.5% when training on the real data. We leverage the ability of generative models to create infinite amounts of data to maximise the downstream prediction performance, and further show how to use synthetic data for hyperparameter tuning. Our results demonstrate that diffusion models fine-tuned with differential privacy can produce useful and provably private synthetic data, even in applications with significant distribution shift between the pre-training and fine-tuning distributions.
https://arxiv.org/pdf/2302.13861.pdf

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢