
Imaginary Voice: Face-styled Diffusion Model for Text-to-Speech
Jiyoung Lee, Joon Son Chung, Soo-Whan Chung
NAVER AI Lab & Korea Advanced Institute of Science and Technology & NAVER Cloud,
想象的声音:用于文本到语音的面部风格扩散模型
要点:
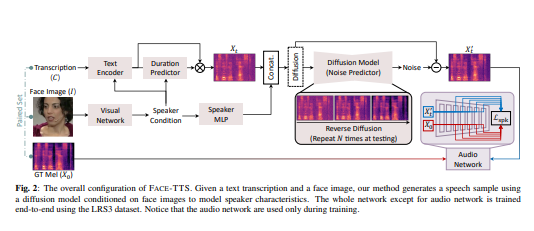
1.这项工作的目标是零镜头文本到语音合成,从面部特征中学习说话风格和声音。 受人们在看着某人的脸时可以想象他或她的声音这一自然事实的启发,我们在从可见属性学习的统一框架内引入了一种面部风格的扩散文本到语音(TTS)模型,称为 Face- 语音合成。
2.这是首次将人脸图像作为条件来训练 TTS 模型。 联合训练跨模型生物识别和 TTS 模型,以保留面部图像和生成的语音片段之间的说话人身份。
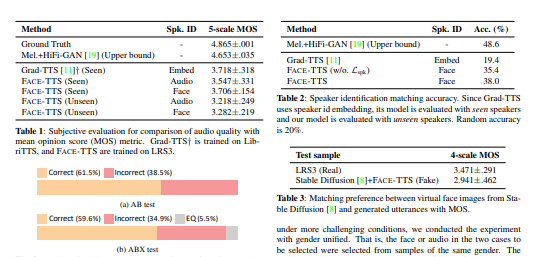
3.还提出了说话人特征绑定损失,以加强说话人嵌入空间中生成的语音片段和真实语音片段的相似性。 由于生物识别信息是直接从面部图像中提取的,因此该方法不需要额外的微调步骤来从看不见和听不到的说话者中生成语音。
一句话总结:
我们在 LRS3 数据集上训练和评估模型,LRS3 数据集是一个包含背景噪音和不同说话风格的野外视听语料库。 项目页面是 https://facetts.github.io
[机器翻译+人工校对]
The goal of this work is zero-shot text-to-speech synthesis, with speaking styles and voices learnt from facial characteristics. Inspired by the natural fact that people can imagine the voice of someone when they look at his or her face, we introduce a face-styled diffusion text-to-speech (TTS) model within a unified framework learnt from visible attributes, called Face-TTS. This is the first time that face images are used as a condition to train a TTS model. We jointly train cross-model biometrics and TTS models to preserve speaker identity between face images and generated speech segments. We also propose a speaker feature binding loss to enforce the similarity of the generated and the ground truth speech segments in speaker embedding space. Since the biometric information is extracted directly from the face image, our method does not require extra fine-tuning steps to generate speech from unseen and unheard speakers. We train and evaluate the model on the LRS3 dataset, an in-the-wild audio-visual corpus containing background noise and diverse speaking styles. The project page is https://facetts.github.io.
https://arxiv.org/pdf/2302.13700.pdf

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢