
一、导读
不得不说,2020年绝对是OCR开源界的丰收年,各种开源repo横空出世,一次又一次的刷新开源界的baseline,小编今天再次给大家种个草,介绍今年OCR开源领域 “真.良心之作”百度飞桨PaddleOCR。
先看下飞桨文字识别套件PaddleOCR自今年年中开源以来,短短几个月在GitHub上的表现:
7月,8.6M超轻量模型发布,GitHub Trending 全球日榜榜单第一! 8月,开源CVPR2020顶会SOTA算法,再上GitHub趋势榜单! 9月,GitHub Star数量已超过3.2K, 近期又带来哪些重磅更新?
果然,看9月最新更新,PaddleOCR再次诚意满满为大家带来真干货,直接看官方介绍:
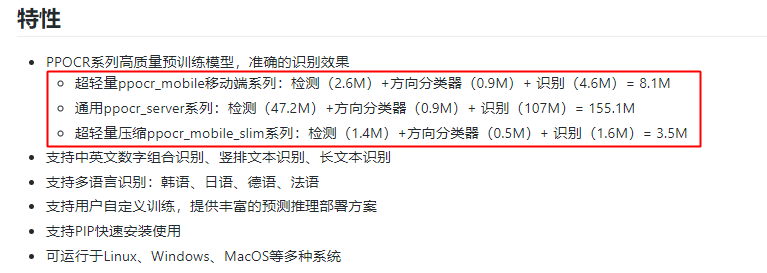
数量上,这次PaddleOCR一口气发布了三个系列模型,满足移动端、服务器端各种场景需求。而且,多语言也妥妥安排上了,全部训练代码和模型毫无保留开源。其中3.5M超轻量文字识别模型,堪称目前业界开源的最轻量OCR模型了。
传送门: Github:https://github.com/PaddlePaddle/PaddleOCR
论文下载链接: https://arxiv.org/abs/2009.09941
二、快速体验PaddleOCR的3.5M超轻量OCR模型
为了让用户快速上手,PaddleOCR也是做足了准备。
PC端快速尝试:(打开网页,选一张图片,即可实时看到结果) https://www.paddlepaddle.org.cn/hub/scene/ocr
iOS版本由于证书限制,需要登录百度EasyEdge网页扫码体验:https://ai.baidu.com/easyedge/app/openSource?from=paddlelite
- 通过PIP安装包快速体验PaddleOCR
pip安装
pip install paddleocr
快速使用
from paddleocr import PaddleOCR, draw_ocr
Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换,参数依次为
ch,en,french,german,korean,japan。ocr = PaddleOCR(useanglecls=True, lang="ch")
输入待识别图片路径
img_path = 'PaddleOCR/doc/imgs/11.jpg'
输出结果保存路径
result = ocr.ocr(img_path, cls=True)
更多内容,可以进入https://github.com/PaddlePaddle/PaddleOCR 快速开始
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢