
SpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks
R Zhu, Q Zhao, J K. Eshraghian
[University of California, Santa Cruz & Kuaishou Technology Co. Ltd]
SpikeGPT: 基于脉冲神经网络的生成式预训练语言模型
要点:
-
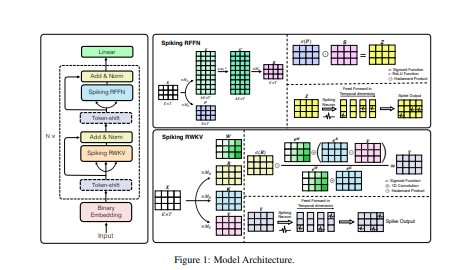
SpikeGPT是第一个使用直接 SNN 训练进行语言生成的语言模型; -
SpikeGPT 实现了与 ANN 相当的性能,同时保持了基于尖峰的计算能效; -
将强大的 Transformer 架构与 SNN 相结合,利用线性化和递归 Transformer 块来避免额外的模拟时间步骤。
一句话总结:
SpikeGPT是一种生成式语言模型,使用脉冲神经网络来减少计算开销和能源消耗。
As the size of large language models continue to scale, so does the computational resources required to run it. Spiking neural networks (SNNs) have emerged as an energy-efficient approach to deep learning that leverage sparse and event-driven activations to reduce the computational overhead associated with model inference. While they have become competitive with non-spiking models on many computer vision tasks, SNNs have also proven to be more challenging to train. As a result, their performance lags behind modern deep learning, and we are yet to see the effectiveness of SNNs in language generation. In this paper, we successfully implement `SpikeGPT', a generative language model with pure binary, event-driven spiking activation units. We train the proposed model on three model variants: 45M, 125M and 260M parameters. To the best of our knowledge, this is 4x larger than any functional backprop-trained SNN to date. We achieve this by modifying the transformer block to replace multi-head self attention to reduce quadratic computational complexity to linear with increasing sequence length. Input tokens are instead streamed in sequentially to our attention mechanism (as with typical SNNs). Our preliminary experiments show that SpikeGPT remains competitive with non-spiking models on tested benchmarks, while maintaining 5x less energy consumption when processed on neuromorphic hardware that can leverage sparse, event-driven activations. Our code implementation is available at this https URL.
https://arxiv.org/pdf/2302.13939.pdf


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢