
Multimodal Speech Recognition for Language-Guided Embodied Agents
Allen Chang, Xiaoyuan Zhu, Aarav Monga, Seoho Ahn, Tejas Srinivasan, Jesse Thomason
University of Southern California
语言引导具体代理的多模式语音识别
要点:
1.语言引导具体代理的基准通常假定基于文本的指令,但部署的代理会遇到口头指令。 虽然自动语音识别 (ASR) 模型可以弥合输入差距,但错误的 ASR 转录可能会损害代理完成任务的能力。
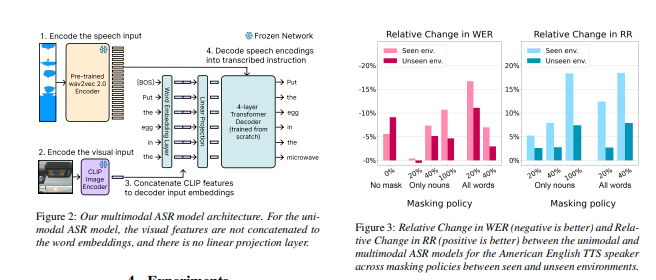
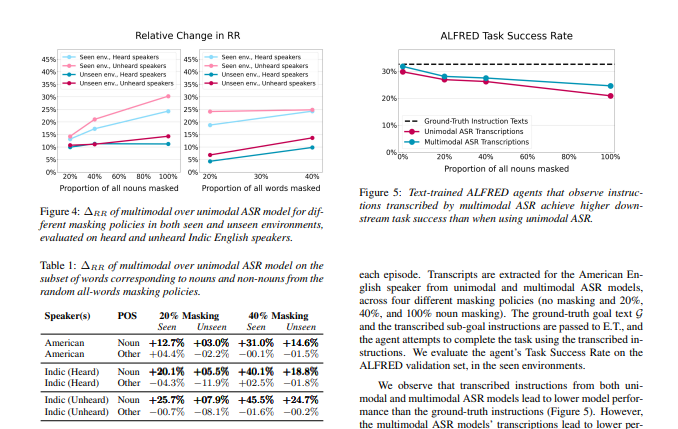
2.在这项工作中,文章建议训练多模式 ASR 模型,以通过考虑伴随的视觉上下文来减少转录口头指令时的错误。 在语音指令数据集上训练我们的模型,该数据集是从 ALFRED 任务完成数据集合成的,通过系统地屏蔽语音来模拟声学噪声。
一句话总结:
我们发现利用视觉观察有助于掩蔽词的恢复,多模态 ASR 模型比单峰基线多恢复了 30% 的掩蔽词。 我们还发现,经过文本训练的具体代理人通过遵循来自多模态 ASR 模型的转录指令,可以更频繁地成功完成任务。
Benchmarks for language-guided embodied agents typically assume text-based instructions, but deployed agents will encounter spoken instructions. While Automatic Speech Recognition (ASR) models can bridge the input gap, erroneous ASR transcripts can hurt the agents' ability to complete tasks. In this work, we propose training a multimodal ASR model to reduce errors in transcribing spoken instructions by considering the accompanying visual context. We train our model on a dataset of spoken instructions, synthesized from the ALFRED task completion dataset, where we simulate acoustic noise by systematically masking spoken words. We find that utilizing visual observations facilitates masked word recovery, with multimodal ASR models recovering up to 30% more masked words than unimodal baselines. We also find that a text-trained embodied agent successfully completes tasks more often by following transcribed instructions from multimodal ASR models.
https://arxiv.org/pdf/2302.14030.pdf

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢