
ProsAudit, a prosodic benchmark for self-supervised speech models
Maureen de Seyssel, Marvin Lavechin, Hadrien Titeux, Arthur Thomas, Gwendal Virlet, Andrea Santos Revilla, Guillaume Wisniewski, Bogdan Ludusan, Emmanuel Dupoux
Cognitive Machine Learning (ENS–CNRS–EHESS–INRIA–PSL Research University)&Universite de Paris Cite, & Bielefeld University
ProsAudit,自监督语音模型的韵律基准
要点:
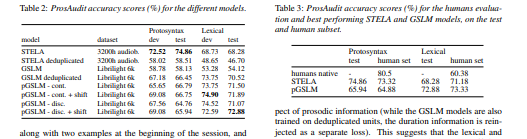
1.介绍了 ProsAudit,这是一种英语基准,用于评估自我监督学习 (SSL) 语音模型中的结构韵律知识。 它由两个子任务、它们对应的指标、一个评估数据集组成。 在原型语法任务中,模型必须正确识别强韵律边界和弱韵律边界。 在词汇任务中,模型需要正确区分单词之间和单词内插入的停顿。 我们还提供了该基准的人工评估分数。
2.评估了一系列 SSL 模型,发现它们都能够在这两项任务上表现出色,即使是在使用一种看不见的语言进行训练时也是如此。 然而,非母语模型在词汇任务上的表现明显差于母语模型,凸显了词汇知识在此任务中的重要性。
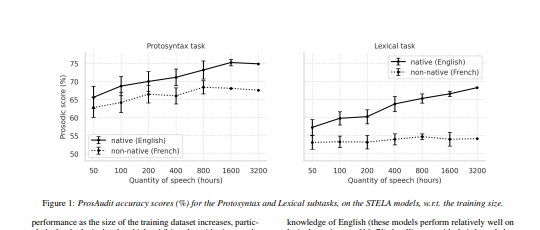
3.在更多数据上训练的模型在两个子任务中表现更好,这对大小有明显的影响。[机器翻译+人工校对]
We present ProsAudit, a benchmark in English to assess structural prosodic knowledge in self-supervised learning (SSL) speech models. It consists of two subtasks, their corresponding metrics, an evaluation dataset. In the protosyntax task, the model must correctly identify strong versus weak prosodic boundaries. In the lexical task, the model needs to correctly distinguish between pauses inserted between words and within words. We also provide human evaluation scores on this benchmark. We evaluated a series of SSL models and found that they were all able to perform above chance on both tasks, even when trained on an unseen language. However, non-native models performed significantly worse than native ones on the lexical task, highlighting the importance of lexical knowledge in this task. We also found a clear effect of size with models trained on more data performing better in the two subtasks.
https://arxiv.org/pdf/2302.12057.pdf

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢