
BioMedLM:生物医学文本的特定领域大型语言模型
大型语言模型 (LLM) 为通用自然语言生成、图像生成、语音合成以及这些应用程序的多模式组合提供了惊人的功能。但是,当我们知道它们将用于特定行业的情况时,我们还能做些什么吗?
今天,我们宣布了 MosaicML 与斯坦福大学基础模型研究中心 (CRFM)的合作成果,展示了特定行业大型语言模型的能力——特别是在生物医学领域。使用MosaicML 云平台,CRFM 对来自PubMed的生物医学数据训练了一个 2.7B 参数 GPT ,在美国医学执照考试 (USMLE)的医学问答文本上取得了最先进的结果——突出了特定领域的承诺实际应用中的语言生成模型。结果:BioMedLM(以前称为 PubMed GPT)。
“我们很高兴发布一种在 PubMed 上训练的新生物医学模型,这是构建可以支持生物医学研究的基础模型的第一步。” - Percy Liang,斯坦福大学 CRFM 主任
我们的工作强化了现有 研究,表明在特定领域数据上训练的标准 LLM 可以胜过通用模型,并与专家设计的特定领域模型架构竞争。在这篇博文中,我们概述了总体方法、我们的结果和我们的要点:自定义 LLM 是一个交钥匙解决方案,适用于任何拥有特定领域数据的组织,而不仅仅是少数拥有大量数据集和巨大计算预算的公司。在我们开始之前,提醒一下:此模型仅用于研究目的而开发,不适合生产。
有关科学结果的其他分析,以及有关如何访问模型的更多信息,请查看 CRFM 的配套博客文章。
BioMedLM 配方
模型。BioMedLM 基于具有 2.7B 参数和 1024 个标记的最大上下文长度的HuggingFace GPT 模型(仅解码器转换器)。它使用在 PubMed Abstracts 上训练的自定义生物医学分词器,词汇量为 28896。
虽然 CRFM 已经在开发捕获生物医学文本知识结构的复杂模型方面取得了长足进步,但对于这个项目,我们希望使模型设计尽可能简单,以展示现成的 LLM 培训方法的强大功能。这样我们就可以重复使用相同的配方来为其他特定领域的应用程序(如法律文本)训练最先进的 GPT 模型。
数据。我们在Pile数据集 的 PubMed Abstracts 和 PubMed Central 部分训练了 BioMedLM 。该数据集包含大约 50B 个标记,涵盖来自生物医学文献的 1600 万篇摘要和 500 万篇全文文章,由美国国立卫生研究院策划。
计算。虽然数据集包含 50B 个 token,但这并不能直接决定训练预算。与 BioMedLM 大小相似的 GPT 模型通常使用更多的数据进行训练。例如,GPT3-2.7B 和 GPT-J 分别接受了 300B 和 400B 数据令牌的训练。
在这个设计空间内,我们选择通过在 50B 令牌上执行多次传递或时期来训练 BioMedLM 进行长时间的计算持续时间(300B 令牌)。我们的结果表明,即使可用数据有限,仍然可以从头开始训练定制的、高质量的 LLM!
使用 MosaicML 进行训练
为了轻松、快速、高效地训练 BioMedLM,我们使用 MosaicML 云作为基础设施,并使用 MosaicML 的 Composer 和 Streaming Dataset 库训练模型。所有模型和训练代码都是基于 PyTorch 构建的。看这里的代码!
MosaicML 云
使用我们的云软件堆栈,我们在具有 128 个 NVIDIA A100-40GB GPU 和节点间 1600 Gb/s 网络带宽的集群之上编排了训练。物理 GPU 托管在领先的云提供商上。BioMedLM 的总训练时间约为 6.25 天。使用 2 美元/A100/小时的占位符定价,在 MosaicML Cloud 上运行的此培训的总成本约为 38,000 美元。
作曲家
为了获得最佳的 LLM 训练体验,我们使用了 Composer 及其 FSDP 集成(FSDP是用于完全分片数据并行训练的 PyTorch 后端)。开源 Composer 库可以轻松地在数百个 GPU 上训练大型自定义模型,而无需对模型代码施加任何限制。例如,我们将 HuggingFace GPT2Model注意力实现替换为FlashAttention(Dao 等人),在生成数学等效模型的同时,将训练吞吐量提高了近 2 倍。Composer 可以毫不费力地处理自定义模型定义,而且训练时间减少了一半!具有轻松添加和测试修改的灵活性极大地提高了 BioMedLM 的培训效率,我们希望在未来的 LLM 工作中做出类似的改进。
流数据集
为了以云原生方式管理包含超过 100GB 文本的训练数据集,我们使用了 MosaicML 的新StreamingDataset库。该库使用户能够将任意数据(文本、图像等)托管为对象存储中的碎片,然后将该数据流式传输到世界任何地方的训练作业。StreamingDataset 与普通 PyTorch DataLoaders 一起开箱即用,并且与多 CPU worker、多 GPU 和多节点训练兼容。
StreamingDataset 使我们能够快速、灵活且廉价地管理自定义训练数据集。无需预先标记数据;我们能够将样本作为原始文本存储在对象存储中。在运行时,我们流式传输文本样本并即时标记化,对训练吞吐量没有影响,也没有数据加载器瓶颈。这种灵活性和性能使我们能够测试 BioMedLM 的不同标记化方案,而无需重新生成数据集。
作为 StreamingDataset 的最后一个证明点,我们对 BioMedLM 的最终训练运行没有使用来自 AWS 的计算,尽管数据集存储在 AWS S3 上。相反,我们将数据从 S3 流式传输到 MosaicML Cloud,而不会影响训练吞吐量,也不会在开始时下载整个数据集。相反,分片在训练运行期间根据需要流入,并在第一个纪元后缓存。这将整个训练运行的数据出口成本限制在 <10 美元,而计算成本约为 38,000 美元!
BioMedLM 的表现如何?
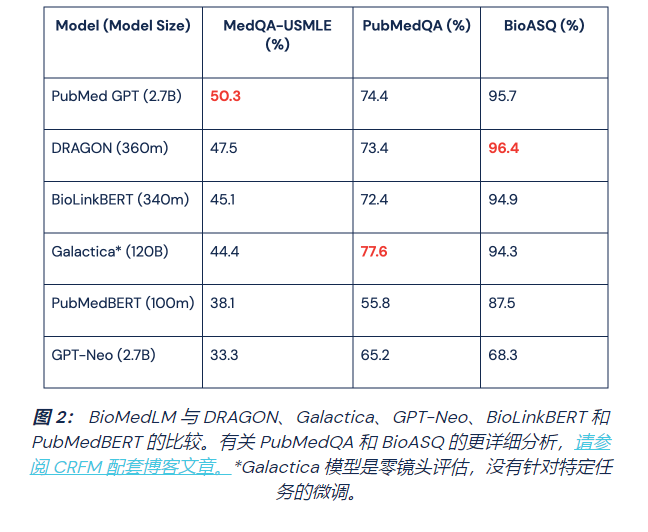
让我们切入正题:它有效吗?我们在几个问答 (QA) 基准上评估了 BioMedLM,并针对问题摘要任务手动评估了它的生成。一个关键的基准是MedQA-USMLE,它由从以前提供给美国医生的医疗执照考试中提取的问题和答案对组成。正如我们在图 1 中看到的,文本包含与各种健康问题相关的详细的技术性医疗查询。

在我们的评估中,我们将我们的结果与几个模型进行了比较:
- DRAGON是最先进的生物医学语言模型,上个月由 CRFM 团队成员单独发布。该模型是根据文本 (PubMed Abstracts) 和专家策划的生物医学知识图谱(即统一医学语言系统,也称为 UMLS)进行预训练的。
- GPT-Neo 2.7B是一个 LLM,其规模和架构与 BioMedLM 相似,但在 Pile 上训练,因此不是特定领域的。
- Galactica是一个 120B 参数的 LLM,在超过 4800 万篇论文、教科书、科学网站、百科全书和其他跨多个领域的科学知识来源的语料库上进行训练。
- BioLinkBERT是 Stanford CRFM 训练的另一种生物医学模型,在训练时使用文档的链接结构。
- PubMedBERT是另一种用于生物医学 NLP 的特定领域语言模型。
由于时间和资源限制,我们没有评估使用与我们不同的评估任务或设置的其他生物医学系统,例如BioMegatron、GatorTron和BioGPT。有关它们与 BioMedLM 关系的更多详细信息,请参阅 CRFM 配套博客文章。
我们如图 2 所示的结果证明了我们的发现:LLM 非常通用,并且在针对特定领域的数据进行训练时提供了显着的改进,而专注的模型可以用相对较少的资源实现高质量。
结论 #1:LLM 非常多才多艺。
BioMedLM 在 MedQA-USMLE 上的表现优于 DRAGON,创下了新的最先进水平,并且与 DRAGON 在其他两项 QA 任务(PubMedQA 和 BioASQ)上的表现相当。至关重要的是,BioMedLM 在没有任何明确的知识图谱的情况下实现了这一点。这些结果表明,当使用特定领域的数据从头开始训练时,标准 LLM 可以提供与定制的、专家设计的系统相当的性能。
就像生活中的大多数事情一样,这种表现不是免费的。与 DRAGON 的 360m 相比,BioMedLM 的参数为 2.7B,证明了模型尺寸/成本与领域专业知识和定制架构之间的权衡。然而,LLM 的通用性质使它们更适用于不同的领域。使用相同的简单 LLM 训练方法,我们可以训练法律或金融领域专业知识的模型。
结论 #2:针对特定领域数据的预训练胜过通用数据。
BioMedLM 明显优于通用GPT-Neo,这是一个具有 2.7B 参数的类似模型,在来自许多领域的文本和代码上进行了训练,差距很大(在 MedQA 上为 17%),即使在针对以下任务微调 GPT-Neo 之后手。
如上所述,GPT-Neo 是在 Pile 上训练的,Pile 是一个庞大的语料库,涵盖 PubMed Abstracts 和 PubMed Central,但主要包含许多其他来源,例如维基百科、美国专利商标局的技术文本、GitHub、HackerNews 和 Reddit . 尽管该数据集包括自然语言的来源,可以提高模型在该领域的能力(例如,维基百科),或扩展模型在多个领域的技术流畅性(例如,美国专利商标局),但它还包括 HackerNews 和 Reddit 等来源,可能将有价值的技术概念与不太可信或完全错误和有偏见的语言混合在一起。总的来说,我们感兴趣的数据 PubMed Abstracts 和 PubMed Central 仅占 Pile 的 17.5%。
结论 #3:聚焦模型以更少的资源实现更高的质量。
尽管我们数据集的总体规模明显小于 Pile,但由于我们选择了特定领域的数据,我们的自定义模型优于 GPT Neo。BioMedLM 在 MedQA 上也优于 Galactica (120B),并与其在 PubMedQA 和 BioASQ 上的行为竞争。一个关键的区别是卡拉狄加的结果是零样本,没有我们应用于其他模型的特定于任务的微调。虽然这种零样本行为令人印象深刻,但 Galactica 的模型针对无数科学领域,并且是我们模型大小的 44 倍,因此会产生大量的训练和推理成本。通过专注于一个单一的科学领域,我们得到了一个更小的模型,它仍然可以在生物医学文本中与卡拉狄加竞争。
大型语言模型为许多公司和研究人员提供了新功能的希望,有可能以比通常假设更少的数据和计算来提供更高的质量。
房间里还有一头大象:模型大小和训练成本。然而,通过我们在高效模型实施、 Composer中的高效培训方法以及使用MosaicML Cloud的可扩展云抽象和编排方面的工作,我们提供了一种可访问且负担得起的解决方案。
期待
今天宣布的合作伙伴关系只是将生物医学文本和其他领域的最先进成果交到更多人手中的更大旅程的第一步。例如,考虑我们使用 BioMedLM 的初步文本生成结果。下面是来自MeQSum的示例,这是一个医学问题摘要基准。该任务对系统的行为进行建模,该系统可以通过电子邮件或语音邮件处理患者查询,并以清晰且可操作的格式将其呈现给医生。
输入:主题:球窝关节消息:先生,恕我直言,我想声明我的球窝关节疼痛。我在正常位置或较低位置没有感觉和疼痛,我的球窝关节有很大的疼痛部位。请开药方治病。
输出(当前):关节痛的治疗方法是什么?
输出 (BioMedLM 2.7B ):球窝关节痛的治疗方法是什么?
从文本中我们可以看出,系统必须将一条存在歧义、拼写错误和错误陈述的消息提炼成一个简洁但仍保留消息原意的版本。BioMedLM 的结果是激动人心的旅程的第一步;但是,我们的工作应被视为概念验证,并不打算用于临床。最终的希望是未来可信赖的交互式 AI 系统能够促进可靠的交互,同时对人类专家的参与进行分类。
请继续关注 BioMedLM 的未来改进和发布!如果您有兴趣在自己的数据上培训 LLM,我们邀请您安排演示。
要与 MosaicML 保持联系,请加入我们的Community Slack或在Twitter上关注我们![机器翻译]
本文来自:https://www.mosaicml.com/blog/introducing-pubmed-gpt
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢