
Language Is Not All You Need: Aligning Perception with Language Models
S Huang, L Dong, W Wang, Y Hao, S Singhal…
[Microsoft]
只是语言还不够: 感知与语言模型相结合
要点:
-
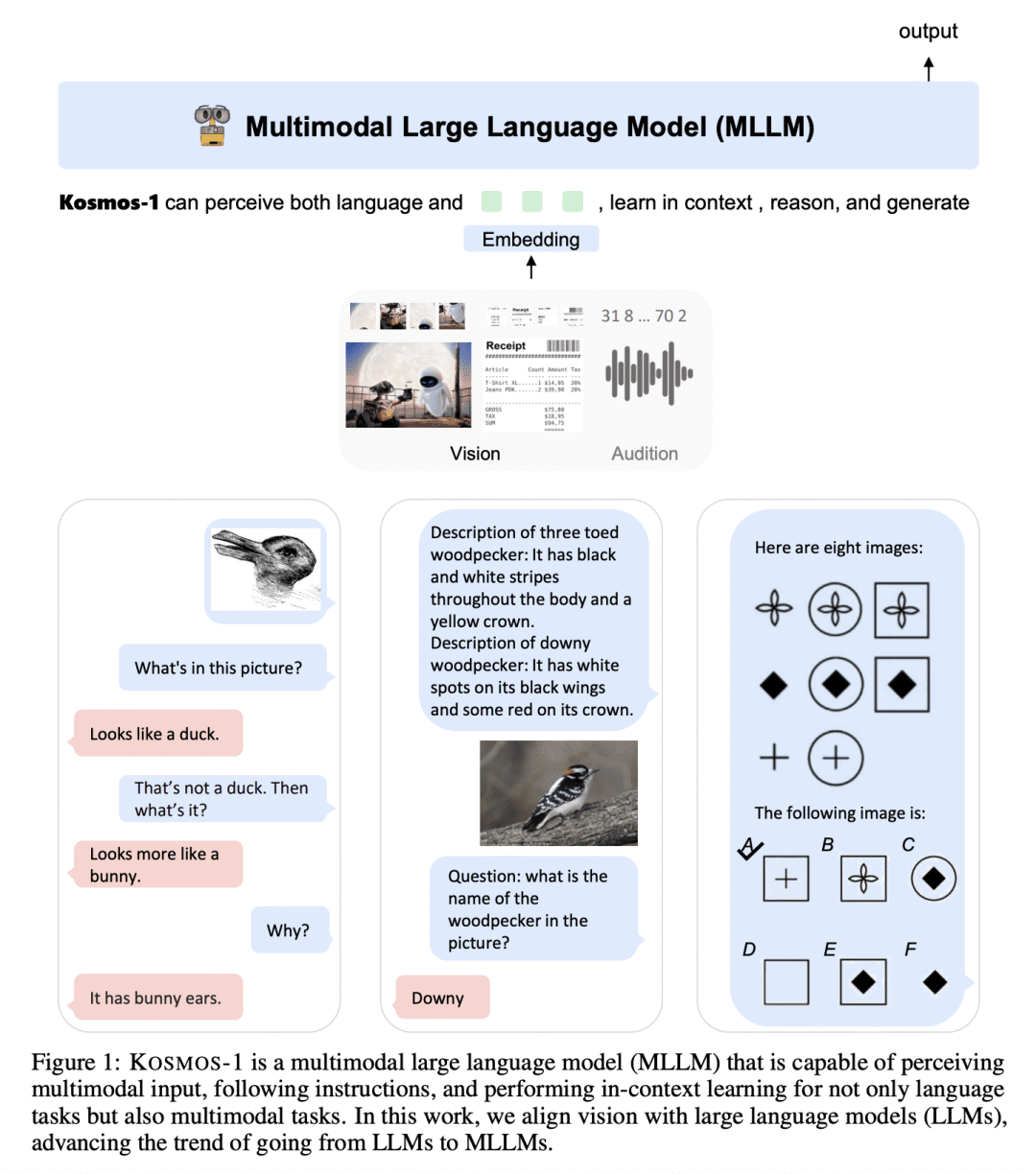
Kosmos-1 是一个多模态的大型语言模型,可以感知一般模态,遵循指令,并进行上下文学习; -
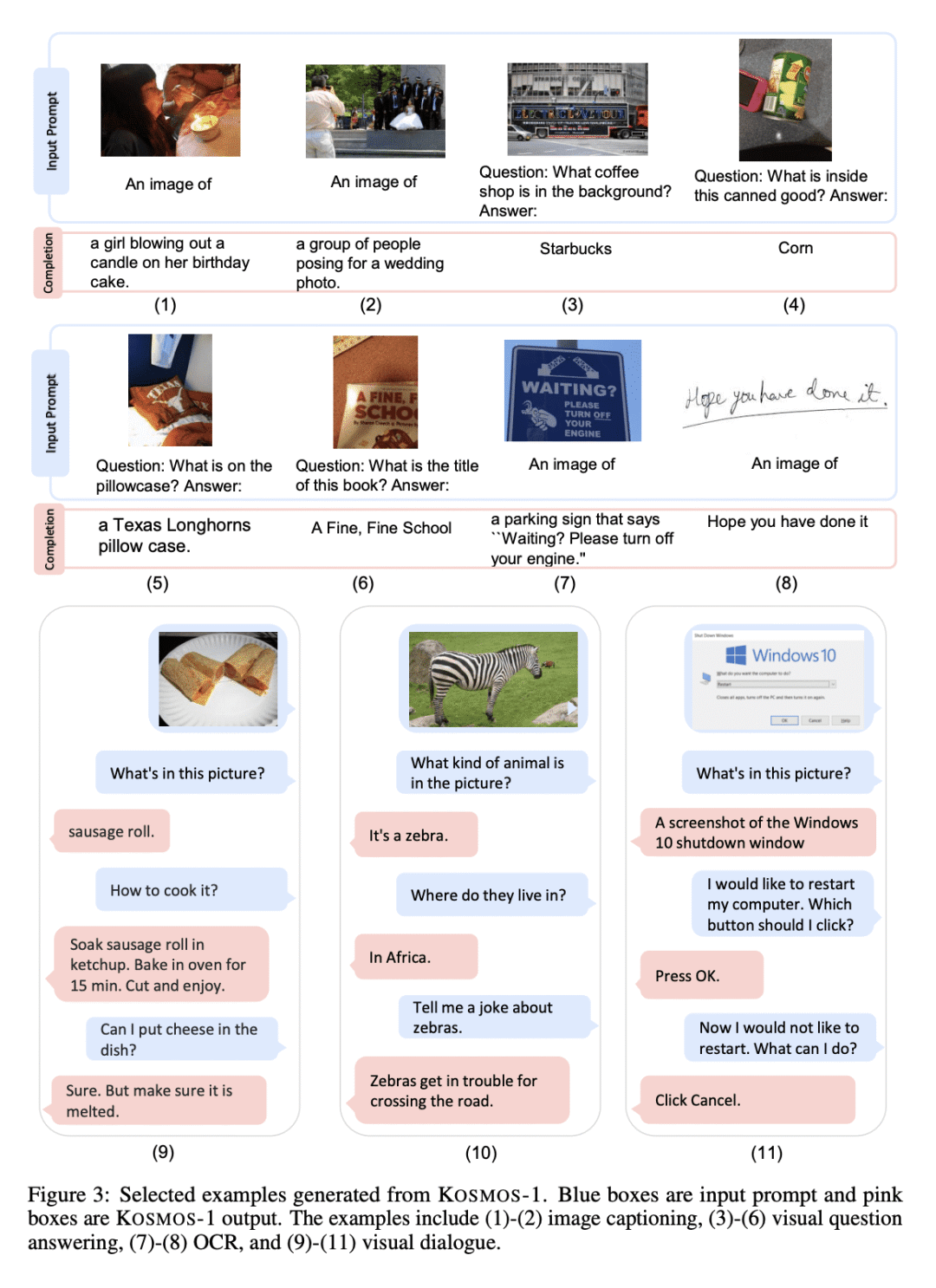
Kosmos-1 在语言和多模态任务上取得了令人印象深刻的表现,无需进行微调,包括带有文字指示的图像识别、视觉问答和多模态对话; -
MLLM 可以从跨模态迁移中获益,将知识从语言迁移到多模态,反之亦然; -
KOSMOS-1 可以扩展模型规模,并与语音能力相结合,作为多模态学习的统一界面。
一句话总结:
多模态大型语言模型 Kosmos-1 能感知一般模态,进行上下文学习,并遵循指令,在语言和多模态任务上取得了令人印象深刻的表现,无需进行微调,这表明将语言和感知相结合,是迈向通用人工智能的关键一步。
A big convergence of language, multimodal perception, action, and world modeling is a key step toward artificial general intelligence. In this work, we introduce Kosmos-1, a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot). Specifically, we train Kosmos-1 from scratch on web-scale multimodal corpora, including arbitrarily interleaved text and images, image-caption pairs, and text data. We evaluate various settings, including zero-shot, few-shot, and multimodal chain-of-thought prompting, on a wide range of tasks without any gradient updates or finetuning. Experimental results show that Kosmos-1 achieves impressive performance on (i) language understanding, generation, and even OCR-free NLP (directly fed with document images), (ii) perception-language tasks, including multimodal dialogue, image captioning, visual question answering, and (iii) vision tasks, such as image recognition with descriptions (specifying classification via text instructions). We also show that MLLMs can benefit from cross-modal transfer, i.e., transfer knowledge from language to multimodal, and from multimodal to language. In addition, we introduce a dataset of Raven IQ test, which diagnoses the nonverbal reasoning capability of MLLMs.
https://arxiv.org/abs/2302.14045 

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢