
MimicPlay: Long-Horizon Imitation Learning by Watching Human Play
Chen Wang, Linxi Fan, Jiankai Sun, Ruohan Zhang, Li Fei-Fei, Danfei Xu, Yuke Zhu, Anima Anandkumar
Stanford & NVIDIA & Georgia Tech & UT Austin & Caltech
MimicPlay:通过观看人类游戏进行长期模仿学习
要点:
1.从人类示范中进行模仿学习是一种很有前途的范例,可以在现实世界中教授机器人操作技能,但学习复杂的长期任务通常需要大量的示范。
2.为了降低高数据要求,我们求助于人类游戏数据——人们用手与环境自由互动的视频序列。 我们假设即使具有不同的形态,人类游戏数据也包含有关物理交互的丰富而显着的信息,这些信息可以很容易地促进机器人策略学习。
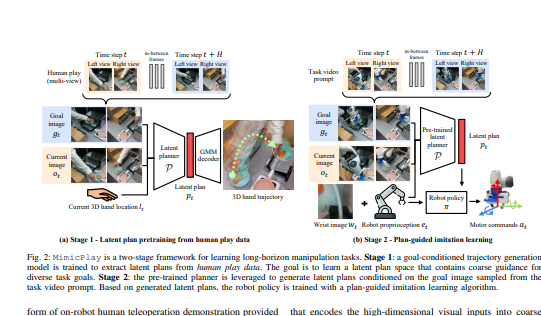
3.受此启发,论文引入了一个名为 MimicPlay 的分层学习框架,该框架从人类游戏数据中学习潜在计划,以指导在少量远程操作演示上训练的低级视觉运动控制。 可以在此 https URL 上找到更多详细信息和视频结果。
- 论文引入了一种新范例,用于从易于收集的人类游戏数据中学习潜在计划。
- 基于预训练的潜在规划器开发了一种计划引导的多任务模仿学习算法,用于有效地解决长期操作任务。
- 在 6 个场景的 14 个长期评估任务中,我们的方法在任务成功率上优于最先进的基线,超过 50%。 它还在以前未见过的任务中表现出更强的泛化能力,任务成功率提高了 40% 以上。
一句话总结:
通过对现实世界中 14 个长时域操纵任务的系统评估,我们表明 MimicPlay 在任务成功率、泛化能力和对干扰的鲁棒性方面显着优于最先进的模仿学习方法。[机器翻译+人工校对]
Imitation Learning from human demonstrations is a promising paradigm to teach robots manipulation skills in the real world, but learning complex long-horizon tasks often requires an unattainable amount of demonstrations. To reduce the high data requirement, we resort to human play data - video sequences of people freely interacting with the environment using their hands. We hypothesize that even with different morphologies, human play data contain rich and salient information about physical interactions that can readily facilitate robot policy learning. Motivated by this, we introduce a hierarchical learning framework named MimicPlay that learns latent plans from human play data to guide low-level visuomotor control trained on a small number of teleoperated demonstrations. With systematic evaluations of 14 long-horizon manipulation tasks in the real world, we show that MimicPlay dramatically outperforms state-of-the-art imitation learning methods in task success rate, generalization ability, and robustness to disturbances. More details and video results could be found at this https URL
https://arxiv.org/pdf/2302.12422.pdf



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢