
Architectural Backdoors in Neural Networks
Mikel Bober-Irizar, Ilia Shumailov, Yiren Zhao, Robert Mullins, Nicolas Papernot
University of Cambridge & University of Toronto and Vector Institute
神经网络中的建筑后门
要点:
1.机器学习容易受到对抗性操纵。先前的文献表明,在训练阶段,攻击者可以操纵数据和数据采样程序来控制模型行为。一个常见的攻击目标是设置后门,即迫使受害者模型学会识别只有对手知道的触发器。
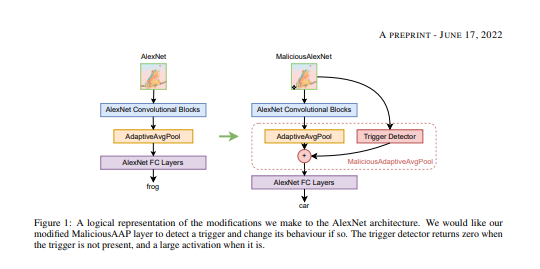
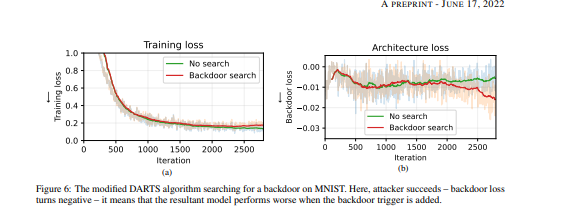
2.在本文中,引入了一类隐藏在模型架构内部的后门攻击,即隐藏在用于训练的函数的归纳偏差中。这些后门很容易实现,例如,通过发布后门模型架构的开源代码,其他人会在不知不觉中重用。文章证明,模型架构后门是一种真正的威胁,与其他方法不同,它可以从零开始进行完整的重新训练。文章中将架构后门背后的主要构建原则正式化,例如输入和输出之间的链接,并描述一些可能的保护措施。
- 展示了一类针对神经网络的新型后门攻击,其中后门隐藏在模型架构内部
- 演示了如何为三种不同的威胁模型构建架构后门并正式确定其成功运行的要求
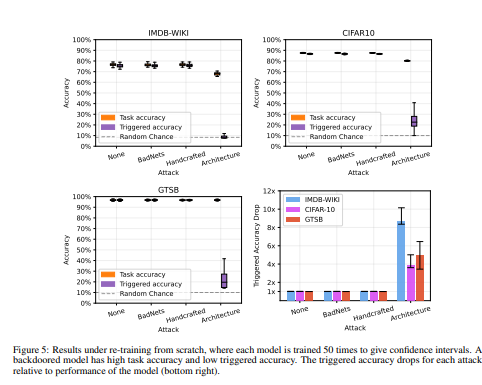
- 在许多基准测试中证明,与以前的方法不同,隐藏在架构内部的后门在重新训练后仍然存在
一句话总结:
论文评估了我们对不同规模的计算机视觉基准的攻击,并证明了潜在的漏洞在各种培训环境中普遍存在。[机器翻译+人工校对]
Machine learning is vulnerable to adversarial manipulation. Previous literature has demonstrated that at the training stage attackers can manipulate data and data sampling procedures to control model behaviour. A common attack goal is to plant backdoors i.e. force the victim model to learn to recognise a trigger known only by the adversary. In this paper, we introduce a new class of backdoor attacks that hide inside model architectures i.e. in the inductive bias of the functions used to train. These backdoors are simple to implement, for instance by publishing open-source code for a backdoored model architecture that others will reuse unknowingly. We demonstrate that model architectural backdoors represent a real threat and, unlike other approaches, can survive a complete re-training from scratch. We formalise the main construction principles behind architectural backdoors, such as a link between the input and the output, and describe some possible protections against them. We evaluate our attacks on computer vision benchmarks of different scales and demonstrate the underlying vulnerability is pervasive in a variety of training settings.
https://arxiv.org/pdf/2206.07840.pdf

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢