
Beating OpenAI CLIP with 100x less data and compute
——Efficient pre-training of Vision-Language transformers for Semantic Search
以 100 倍的数据和计算量击败 OpenAI CLIP
——用于语义搜索的视觉语言转换器的高效预训练
来自 Unum AI 团队的问候! 去年,我们一直在默默地预训练大量用于语义搜索的多模态模型。 现在我们将它与我们的数据库捆绑在一起,并在 HuggingFace 门户网站上发布了几个性能极佳的检查点!
那么我们是怎么做到的呢? 像 OpenAI CLIP 这样的训练模型不是只为谷歌规模的公司保留吗? 我们不这么认为,今天我们将剖析如何训练一个比多语言 mCLIP 更精确的 Vision-Language transformer,它也工作得更快![机器翻译]
文章链接:https://www.unum.cloud/blog/2023-02-20-efficient-multimodality
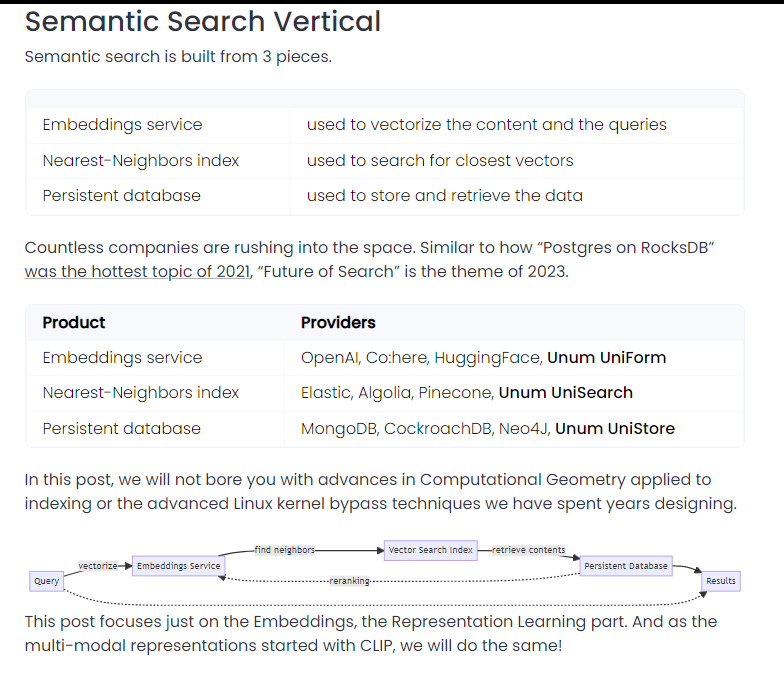
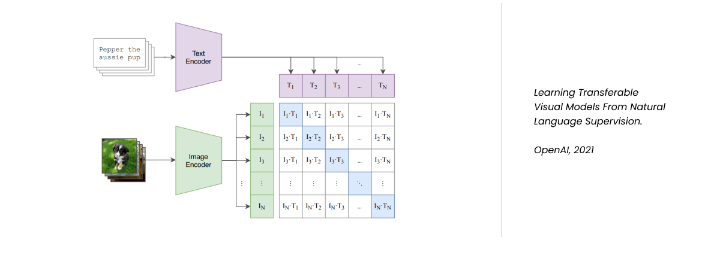
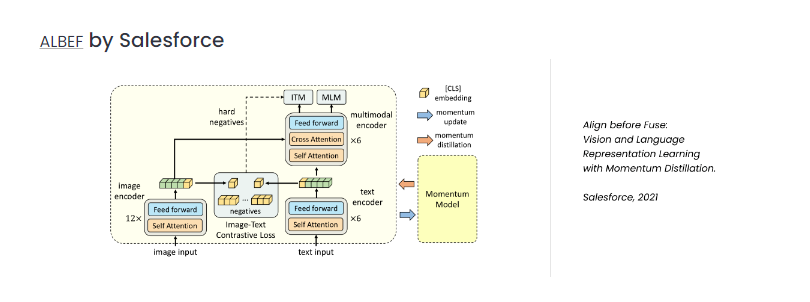
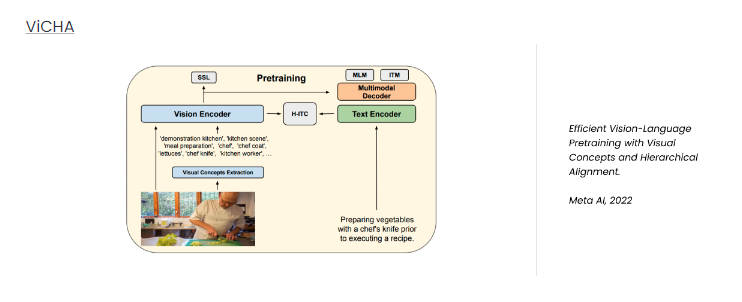
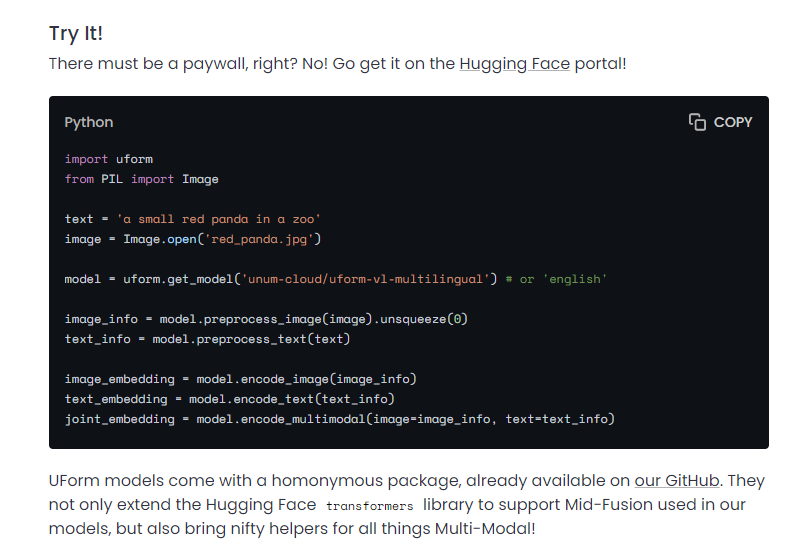
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢