
Leveraging Video Coding Knowledge for Deep Video Enhancement
Thong Bach, Thuong Nguyen Canh, Van-Quang Nguyen
[Osaka University & Tohoku University]
利用视频编码知识进行深度视频增强
要点:
1、深度学习技术的最新进展显著提高了压缩视频的质量。然而,先前的方法没有充分利用压缩视频的运动特性,例如视频内容之间的运动剧烈变化和压缩视频的分层编码结构。
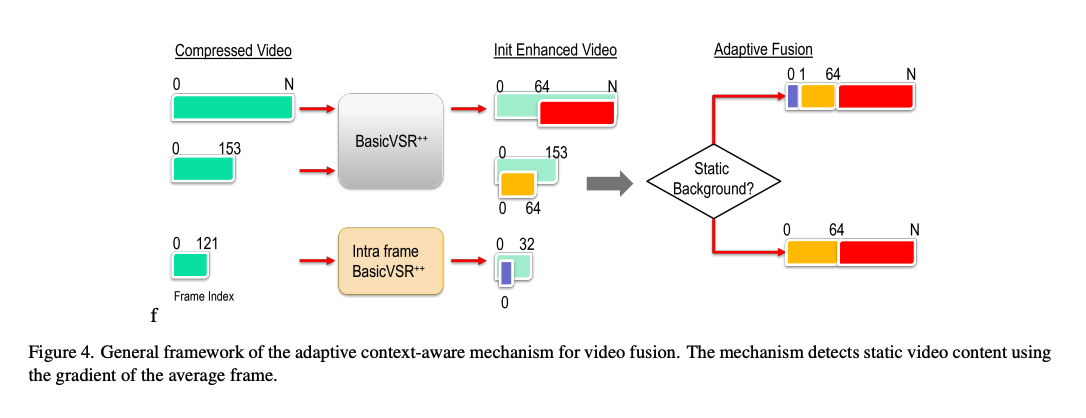
2、本研究提出了一种新的框架,该框架利用视频压缩的低延迟配置来增强现有的最先进的方法BasicVSR++。结合一种上下文自适应视频融合方法来增强压缩视频的最终质量。
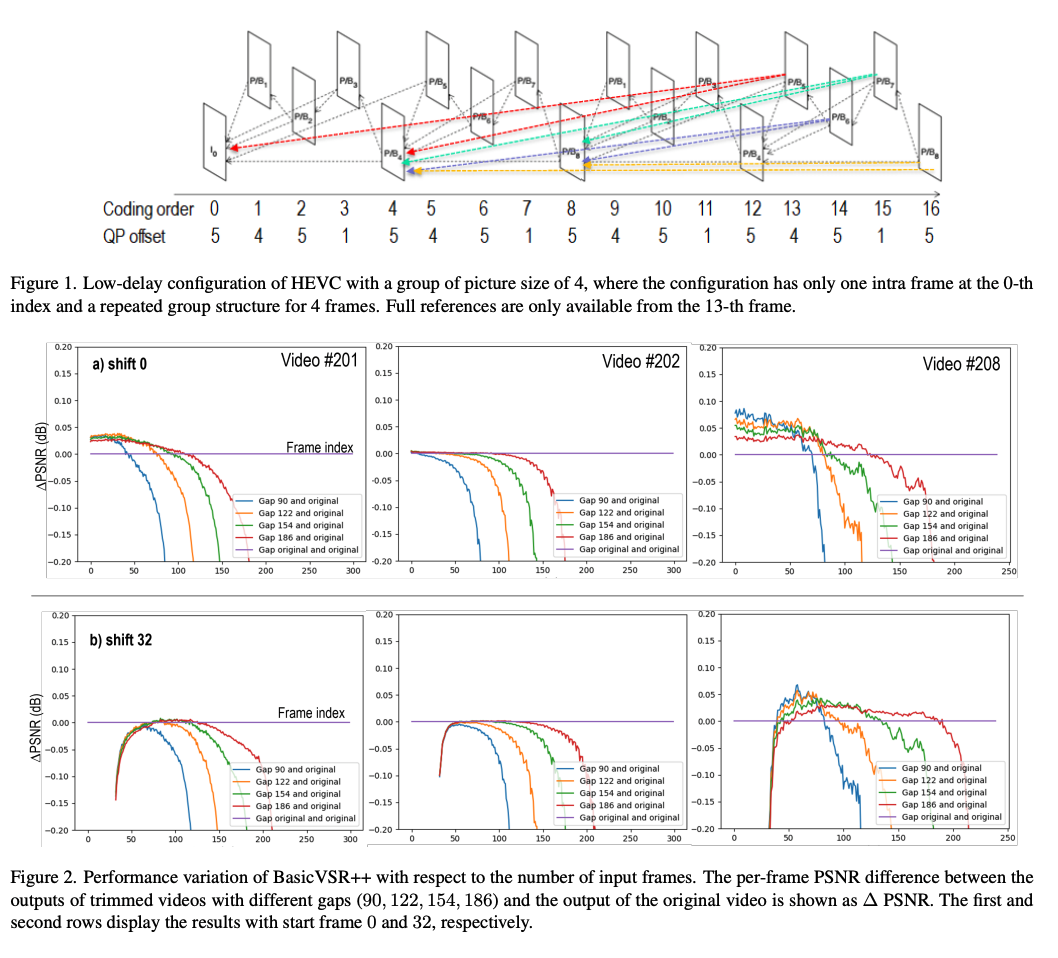
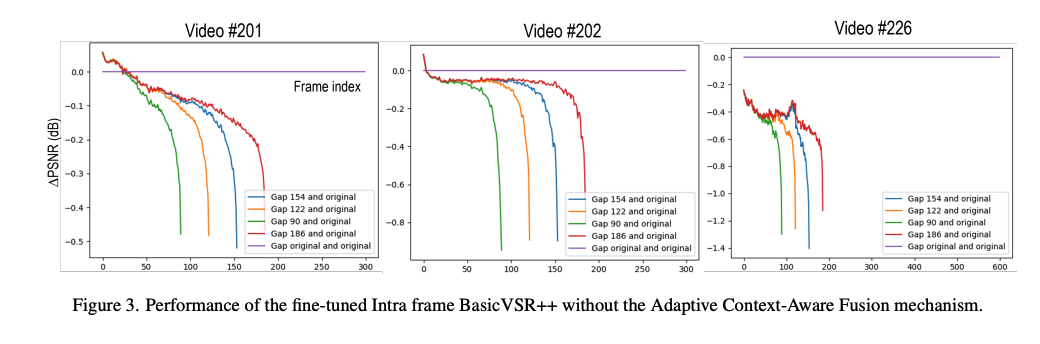
- 首先检查BasicVSR++在不同数量的输入帧下的性能,同时考虑到内容的运动信息。由于压缩视频使用HEVC低延迟配置,第一帧(也称为帧内帧)的质量明显高于其他帧。
- 为了利用这一点,训练了一个称为帧内BasicVSR++的单独网络,以提高第一帧的质量。
- 最后,介绍了一种自适应机制组合具有不同输入序列长度的多个重构实例以获得最终增强输出。
一句话总结:
本研究提出的BasicVSR++方法已经在NTIRE22挑战中进行了评估,这是视频恢复和增强的基准,与之前的方法相比,该方法在量化指标和视觉质量方面都有所改进。所提出的框架不仅利用了视频压缩的低延迟配置,还结合了上下文自适应视频融合,以提高压缩视频的最终质量。这些结果证明了将特定领域的知识纳入深度学习模型以推进压缩视频质量增强的最新技术的潜力。
Recent advancements in deep learning techniques have significantly improved the quality of compressed videos. However, previous approaches have not fully exploited the motion characteristics of compressed videos, such as the drastic change in motion between video contents and the hierarchical coding structure of the compressed video. This study proposes a novel framework that leverages the low-delay configuration of video compression to enhance the existing state-of-the-art method, BasicVSR++. We incorporate a context-adaptive video fusion method to enhance the final quality of compressed videos. The proposed approach has been evaluated in the NTIRE22 challenge, a benchmark for video restoration and enhancement, and achieved improvements in both quantitative metrics and visual quality compared to the previous method.
https://arxiv.org/pdf/2302.13594.pdf


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢