
Large Language Models Are State-of-the-Art Evaluators of Translation Quality
Tom Kocmi,Christian Federmann
[Microsoft, One Microsoft Way, Redmond, WA-98052, USA]
大型语言模型是翻译质量的最新评估工具
要点:
1.文章描述了GEMBA,这是一种基于GPT的评估翻译质量的指标,它既适用于参考翻译,也适用于无参考翻译。
2.在评估中,文章专注于零镜头提示,根据参考的可用性,比较两种模式下的四种提示变体。
3.文章研究了七个版本的GPT模型,包括ChatGPT。文章表明,我们的翻译质量评估方法仅适用于GPT 3.5和更大的模型。与WMT22的度量共享任务的结果相比,与基于MQM的人类标签相比,该方法在两种模式下都达到了最先进的精度。
- 在最新的 WMT22 指标评估数据(系统级)上展示了基于 GPT 的翻译质量评估的最先进能力;
- 试验了四种提示模板,表明受约束最少的模板达到最佳性能;
- 评估了七种不同的 GPT 模型,表明只有 GPT 3.5 和更大的模型能够进行翻译质量评估;
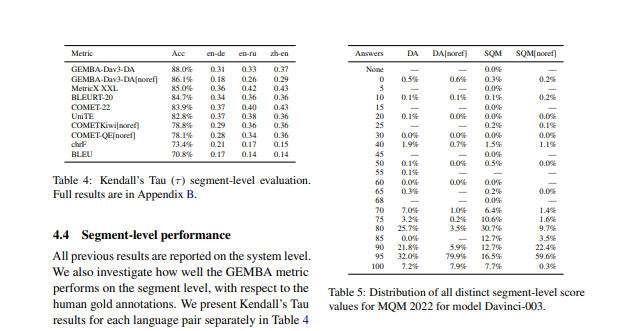
- 表明 GEMBA 在细分级别上还不够可靠,因此,应该仅应用于系统级评估
一句话总结:
论文结果在系统层面上适用于所有三个WMT22度量共享任务语言对,即英语到德语、英语到俄语和汉语到英语。这是第一次了解了预训练的生成性大型语言模型对翻译质量评估的有用性。论文公开发布了用于本工作中描述的实验的所有代码和提示模板,以及所有相应的评分结果,以允许外部验证和再现性。[机器翻译+人工校对]
We describe GEMBA, a GPT-based metric for assessment of translation quality, which works both with a reference translation and without. In our evaluation, we focus on zero-shot prompting, comparing four prompt variants in two modes, based on the availability of the reference. We investigate seven versions of GPT models, including ChatGPT. We show that our method for translation quality assessment only works with GPT 3.5 and larger models. Comparing to results from WMT22's Metrics shared task, our method achieves state-of-the-art accuracy in both modes when compared to MQM-based human labels. Our results are valid on the system level for all three WMT22 Metrics shared task language pairs, namely English into German, English into Russian, and Chinese into English. This provides a first glimpse into the usefulness of pre-trained, generative large language models for quality assessment of translations. We publicly release all our code and prompt templates used for the experiments described in this work, as well as all corresponding scoring results, to allow for external validation and reproducibility.
https://arxiv.org/pdf/2302.14520.pdf


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢