
Internet Explorer: Targeted Representation Learning on the Open Web
A C. Li, E Brown, A A. Efros, D Pathak
[CMU & UC Berkeley]
Internet Explorer: 开放网络环境下的目标式表示学习
要点:
-
目前的视觉模型,只从预训练的数据集中获取知识,限制了其在特定任务上表现良好的能力; -
Internet Explorer 提供了一种替代方法,主动搜索并利用开放网络来训练擅长手头任务的小规模模型; -
Internet Explorer 在很短的时间内就取得了最先进的结果,并超过了计算量大的 oracle 模型和以无定向方式搜索网络的强大基线; -
Internet Explorer 的成功突出了交互式网络探索作为高度相关训练数据的有效来源的潜力。
一句话总结:
Internet Explorer 是一种用自监督学习通过在交互探索开放网络发现的相关样本上训练模型的方法,在单个 GPU 上仅用 30-40 小时就取得了最先进的结果。
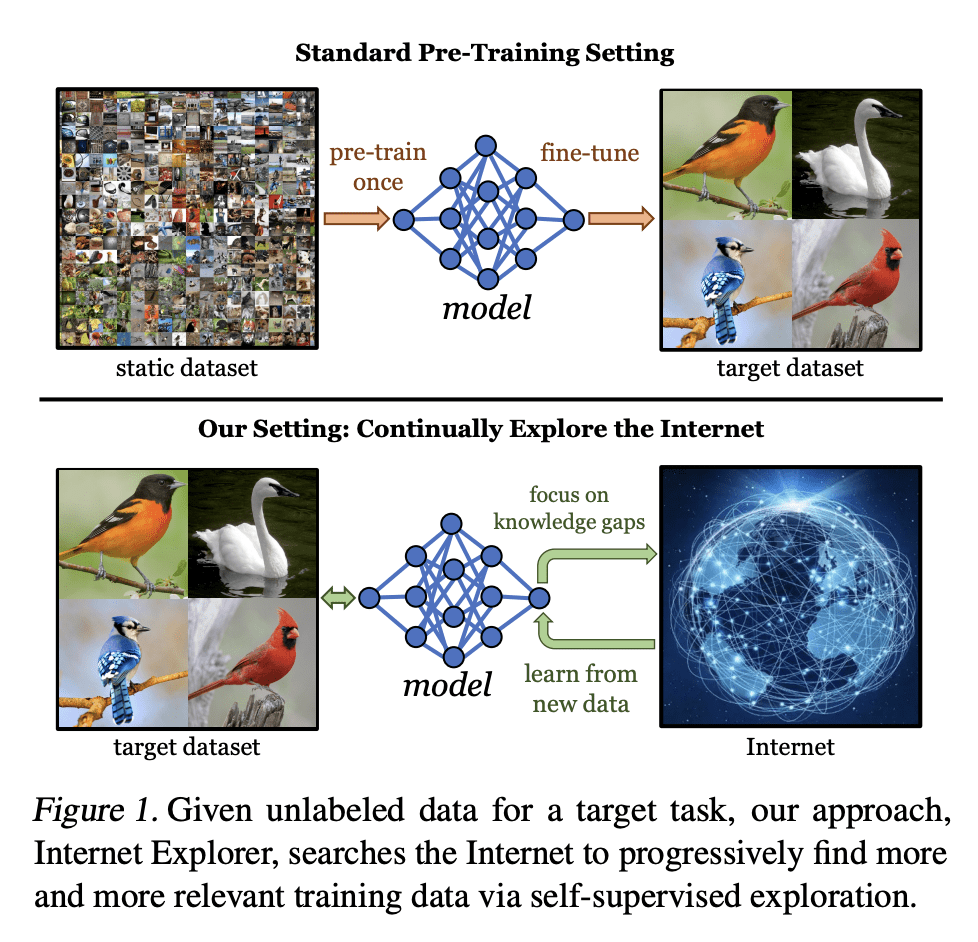
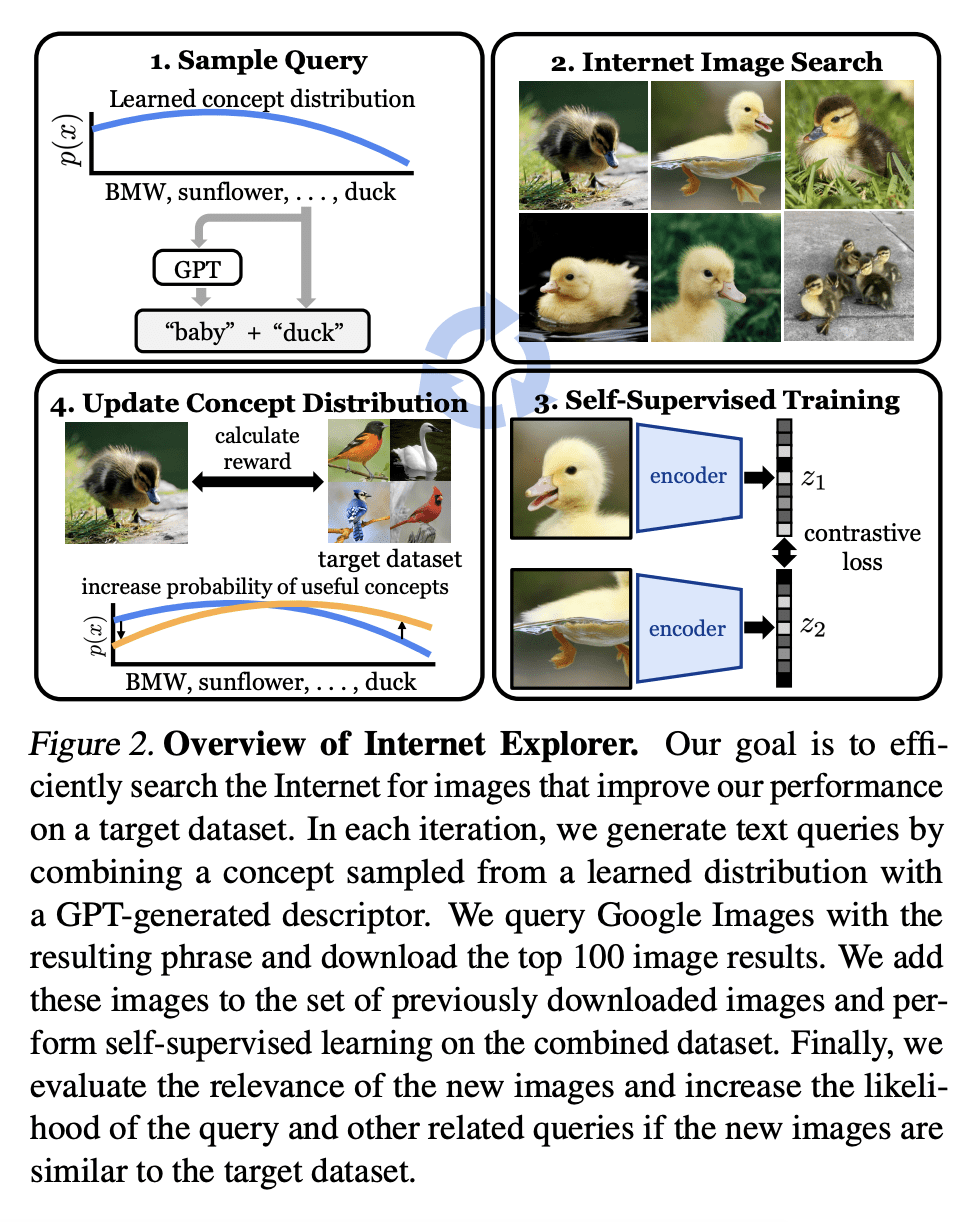
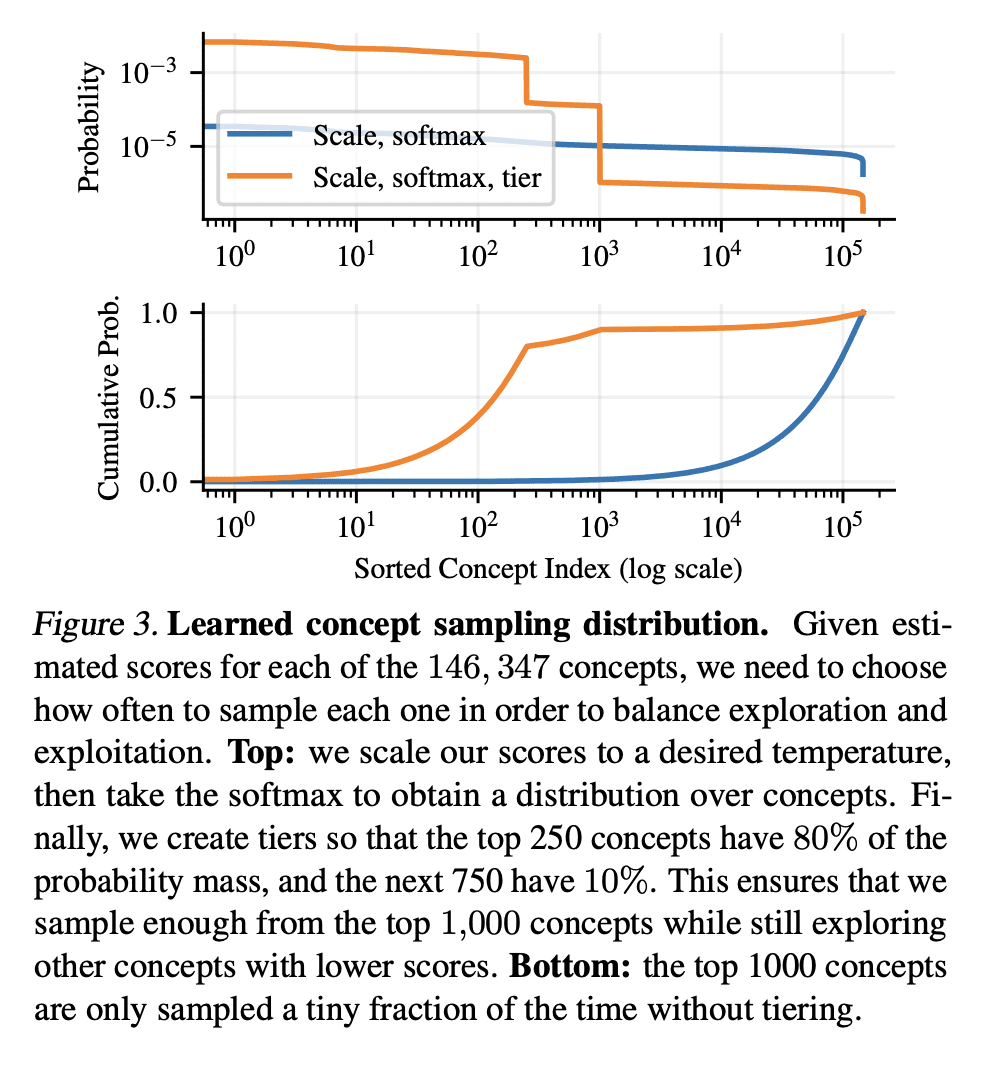
Modern vision models typically rely on fine-tuning general-purpose models pre-trained on large, static datasets. These general-purpose models only capture the knowledge within their pre-training datasets, which are tiny, out-of-date snapshots of the Internet -- where billions of images are uploaded each day. We suggest an alternate approach: rather than hoping our static datasets transfer to our desired tasks after large-scale pre-training, we propose dynamically utilizing the Internet to quickly train a small-scale model that does extremely well on the task at hand. Our approach, called Internet Explorer, explores the web in a self-supervised manner to progressively find relevant examples that improve performance on a desired target dataset. It cycles between searching for images on the Internet with text queries, self-supervised training on downloaded images, determining which images were useful, and prioritizing what to search for next. We evaluate Internet Explorer across several datasets and show that it outperforms or matches CLIP oracle performance by using just a single GPU desktop to actively query the Internet for 30--40 hours. Results, visualizations, and videos at this https URL
论文链接:https://arxiv.org/abs/2302.14051
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢