
In-Context Instruction Learning
S Ye, H Hwang, S Yang, H Yun, Y Kim, M Seo
[KAIST & LG AI Research]
上下文指令学习
要点:
-
上下文指令学习(In-Context Instruction Learning,ICIL)极大地提高了预训练的和指令微调的大型语言模型的零样本任务泛化性能; -
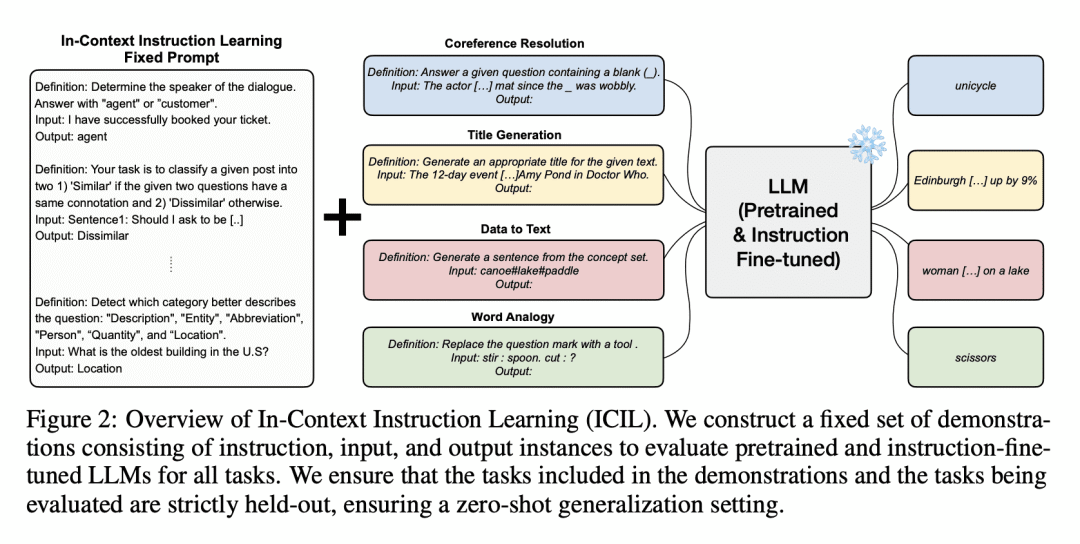
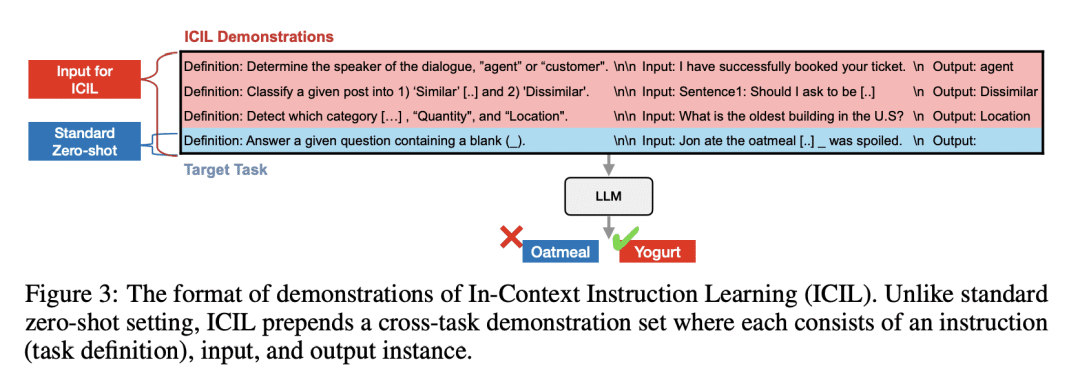
ICIL 用一个固定提示来评估所有任务,是一个跨任务演示的串联; -
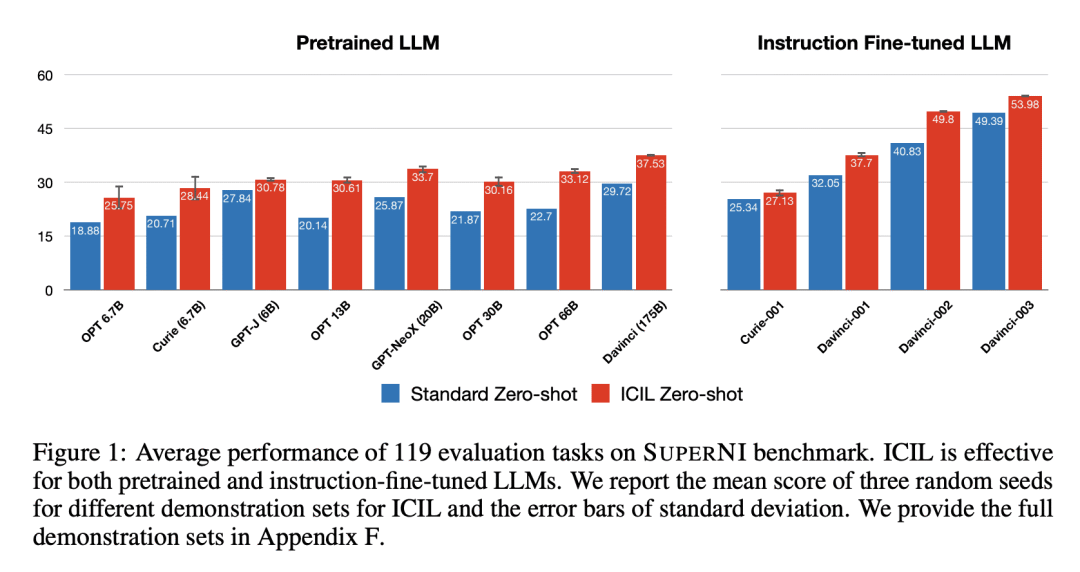
ICIL是对基于指令微调的补充,最强大的指令微调基线(text-davinci-003)也从ICIL中受益了9.3%; -
ICIL的效果来自于学习指令中答案选择和示范标签间的对应关系,导致大型语言模型更好地关注指令。
一句话总结:
上下文指令学习(In-Context Instruction Learning,ICIL)极大提高了经过预训练和指导微调的大型语言模型的零样本任务泛化性能。
Instruction learning of Large Language Models (LLMs) has enabled zero-shot task generalization. However, instruction learning has been predominantly approached as a fine-tuning problem, including instruction tuning and reinforcement learning from human feedback, where LLMs are multi-task fine-tuned on various tasks with instructions. In this paper, we present a surprising finding that applying in-context learning to instruction learning, referred to as In-Context Instruction Learning (ICIL), significantly improves the zero-shot task generalization performance for both pretrained and instruction-fine-tuned models. One of the core advantages of ICIL is that it uses a single fixed prompt to evaluate all tasks, which is a concatenation of cross-task demonstrations. In particular, we demonstrate that the most powerful instruction-fine-tuned baseline (text-davinci-003) also benefits from ICIL by 9.3%, indicating that the effect of ICIL is complementary to instruction-based fine-tuning.
论文链接:https://arxiv.org/abs/2302.14691
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢