
Goal Driven Discovery of Distributional Differences via Language Descriptions
R Zhong, P Zhang, S Li, J Ahn, D Klein, J Steinhardt
[UC Berkeley]
目标驱动的基于语言描述的分布差异发现
要点:
-
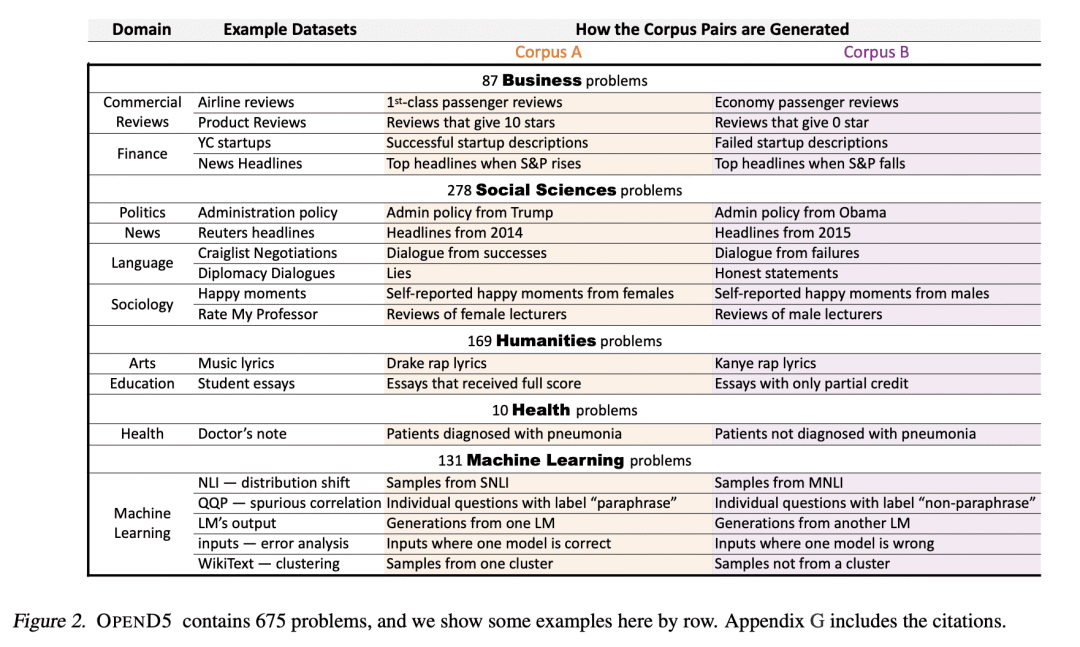
介绍了一个新任务D5,用于以目标驱动方式自动发现两个大型语料库间的差异; -
提出一个元数据集 OpenD5,包括 675 个跨域开放性问题,使用统一的评价指标来评价 D5 系统; -
语言模型可利用 D5 的目标和统一指标提出更多相关的、新的和重要的发现; -
D5 系统可以在广泛的应用中发现以前未知的见解,包括讨论主题、政治立场和 NLP 模型的错误模式。
一句话总结:
提出一种新任务 D5,以目标驱动方式自动发现两个大型语料库之间的分布差异,引入一个元数据集 OpenD5,用统一评价指标来评价 D5 系统。
Mining large corpora can generate useful discoveries but is time-consuming for humans. We formulate a new task, D5, that automatically discovers differences between two large corpora in a goal-driven way. The task input is a problem comprising a research goal "comparing the side effects of drug A and drug B" and a corpus pair (two large collections of patients' self-reported reactions after taking each drug). The output is a language description (discovery) of how these corpora differ (patients taking drug A "mention feelings of paranoia" more often). We build a D5 system, and to quantitatively measure its performance, we 1) contribute a meta-dataset, OpenD5, aggregating 675 open-ended problems ranging across business, social sciences, humanities, machine learning, and health, and 2) propose a set of unified evaluation metrics: validity, relevance, novelty, and significance. With the dataset and the unified metrics, we confirm that language models can use the goals to propose more relevant, novel, and significant candidate discoveries. Finally, our system produces discoveries previously unknown to the authors on a wide range of applications in OpenD5, including temporal and demographic differences in discussion topics, political stances and stereotypes in speech, insights in commercial reviews, and error patterns in NLP models.
论文链接:https://arxiv.org/abs/2302.14233


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢