
Generic-to-Specific Distillation of Masked Autoencoders
W Huang, Z Peng, L Dong, F Wei, J Jiao, Q Ye
[Microsoft Research & University of Chinese Academy of Sciences]
掩码自编码器的一般到特定蒸馏
要点:
-
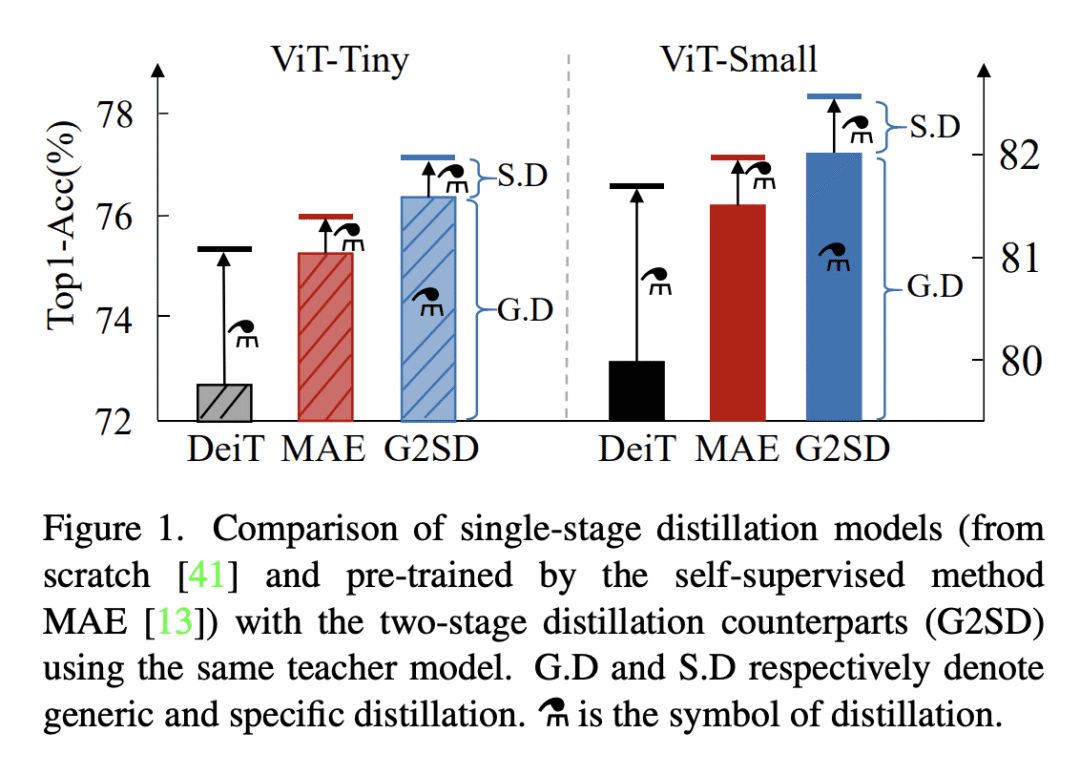
G2SD 是一种两阶段蒸馏方法,将任务无关和任务特定知识从大型预训练模型迁移到轻量 ViT 中; -
一种简单有效的通用蒸馏策略,是通过让学生预测与可见图块和掩码图块预训练掩码自编码器隐特征对齐而设计的; -
通过 G2SD,轻量学生模型在不同的视觉任务中取得了有竞争力的结果,将轻量 ViT 模型的性能提升到一个新高度; -
实验表明,vanilla ViT-Small 模型在图像分类、目标检测和语义分割方面分别达到了其教师(ViT-Base)的 98.7%、98.1% 和 99.3% 的性能。
一句话总结:
G2SD 是一种两阶段蒸馏方法,将任务无关和任务特定的知识从大型预训练模型迁移到轻量 ViT,为两阶段视觉模型蒸馏设定了一个坚实的基线。
Large vision Transformers (ViTs) driven by self-supervised pre-training mechanisms achieved unprecedented progress. Lightweight ViT models limited by the model capacity, however, benefit little from those pre-training mechanisms. Knowledge distillation defines a paradigm to transfer representations from large (teacher) models to small (student) ones. However, the conventional single-stage distillation easily gets stuck on task-specific transfer, failing to retain the task-agnostic knowledge crucial for model generalization. In this study, we propose generic-to-specific distillation (G2SD), to tap the potential of small ViT models under the supervision of large models pre-trained by masked autoencoders. In generic distillation, decoder of the small model is encouraged to align feature predictions with hidden representations of the large model, so that task-agnostic knowledge can be transferred. In specific distillation, predictions of the small model are constrained to be consistent with those of the large model, to transfer task-specific features which guarantee task performance. With G2SD, the vanilla ViT-Small model respectively achieves 98.7%, 98.1% and 99.3% the performance of its teacher (ViT-Base) for image classification, object detection, and semantic segmentation, setting a solid baseline for two-stage vision distillation. Code will be available at this https URL.
论文链接:https://arxiv.org/abs/2302.14771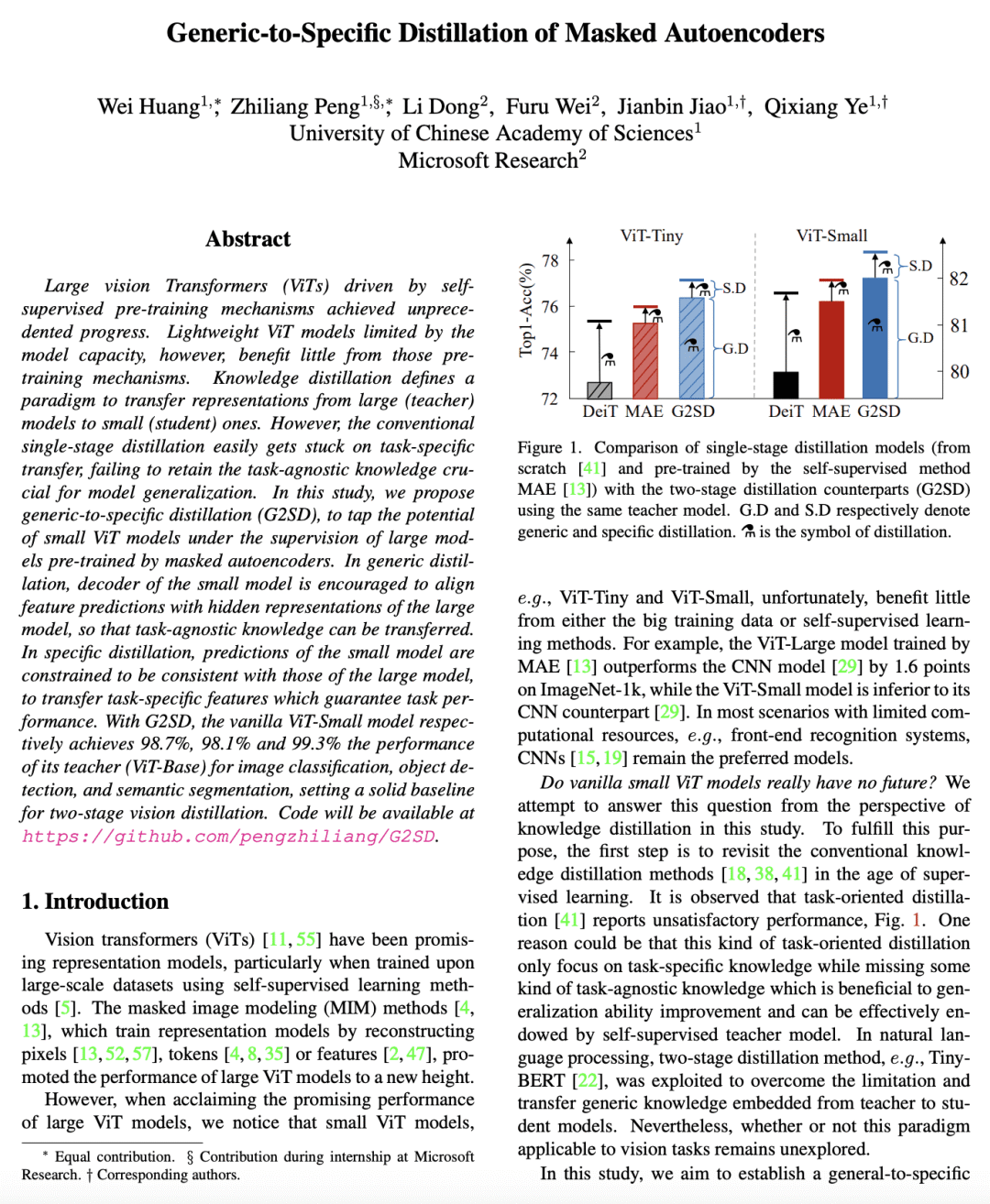
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢