
The Trade-off between Universality and Label Efficiency of Representations from Contrastive Learning
Z Shi, J Chen, K Li, J Raghuram, X Wu, Y Liang, S Jha
[University of Wisconsin-Madison & Google]
对比学习表示的普适性与标签效率的权衡
要点:
-
用对比学习和线性探测对表示进行预训练,是下游任务的一个流行范式;
-
在标签效率和对比学习的表示的普适性之间存在着权衡;
-
更多多样的预训练数据,导致不同任务的特征更加多样化,提高了普适性,但由于更大的样本复杂性,预测性能会变差;
-
对比正则化方法可以用来改善标签效率和普适性之间的权衡。
一句话总结:
研究了对比学习预训练的表示在普适性和标签效率间的权衡,提出一种对比正则化方法来改善这种权衡。
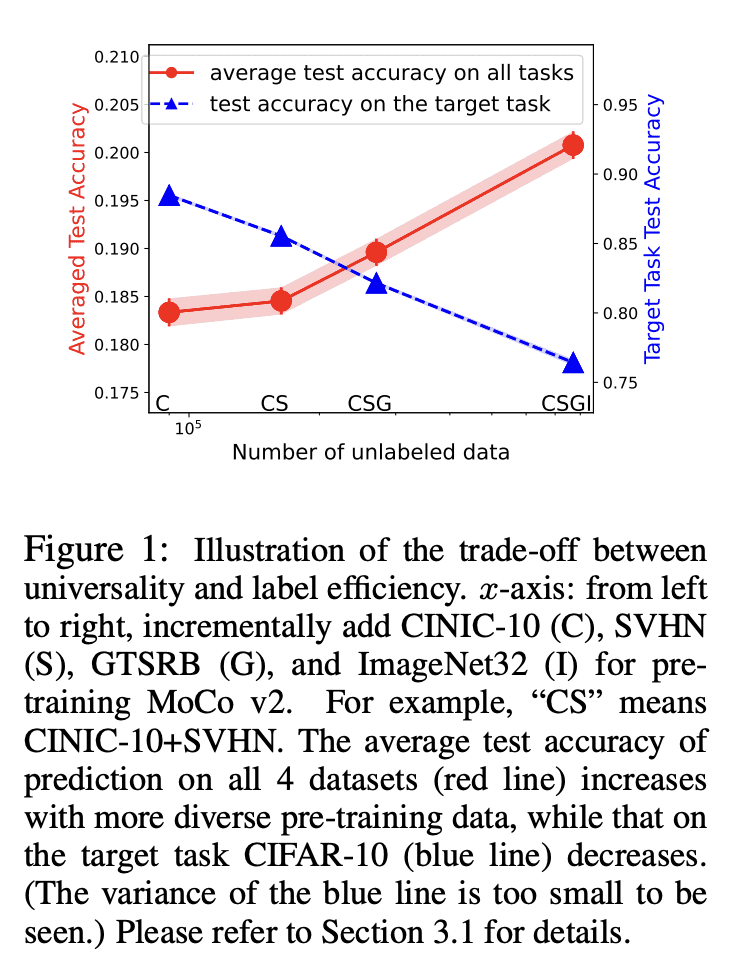
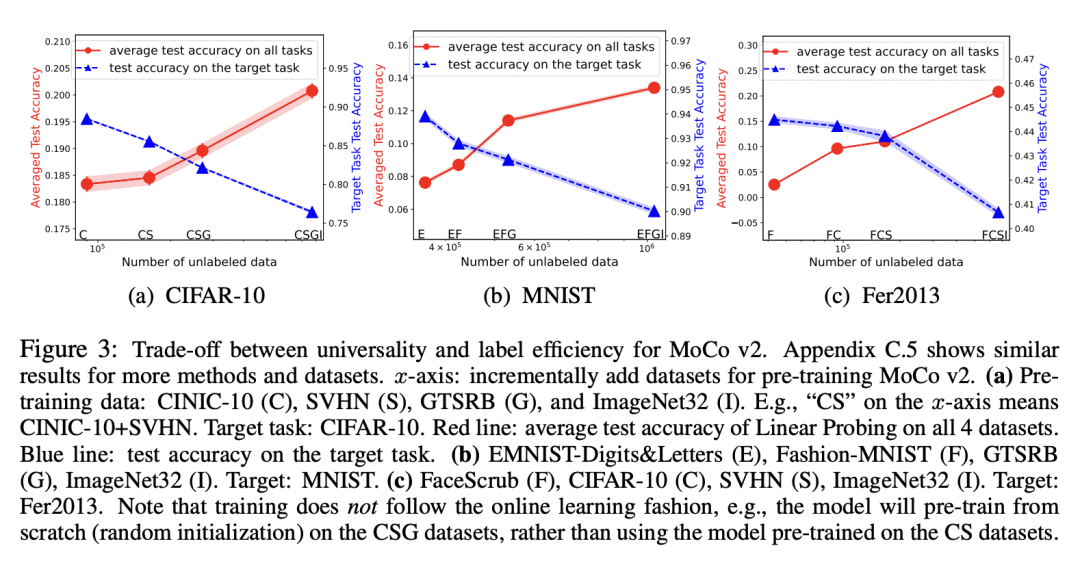
Pre-training representations (a.k.a. foundation models) has recently become a prevalent learning paradigm, where one first pre-trains a representation using large-scale unlabeled data, and then learns simple predictors on top of the representation using small labeled data from the downstream tasks. There are two key desiderata for the representation: label efficiency (the ability to learn an accurate classifier on top of the representation with a small amount of labeled data) and universality (usefulness across a wide range of downstream tasks). In this paper, we focus on one of the most popular instantiations of this paradigm: contrastive learning with linear probing, i.e., learning a linear predictor on the representation pre-trained by contrastive learning. We show that there exists a trade-off between the two desiderata so that one may not be able to achieve both simultaneously. Specifically, we provide analysis using a theoretical data model and show that, while more diverse pre-training data result in more diverse features for different tasks (improving universality), it puts less emphasis on task-specific features, giving rise to larger sample complexity for down-stream supervised tasks, and thus worse prediction performance. Guided by this analysis, we propose a contrastive regularization method to improve the trade-off. We validate our analysis and method empirically with systematic experiments using real-world datasets and foundation models.
论文链接:https://arxiv.org/abs/2303.00106
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢