
Dropout Reduces Underfitting
Z Liu, Z Xu, J Jin, Z Shen, T Darrell
[Meta AI & UC Berkeley]
用Dropout减轻欠拟合
要点:
-
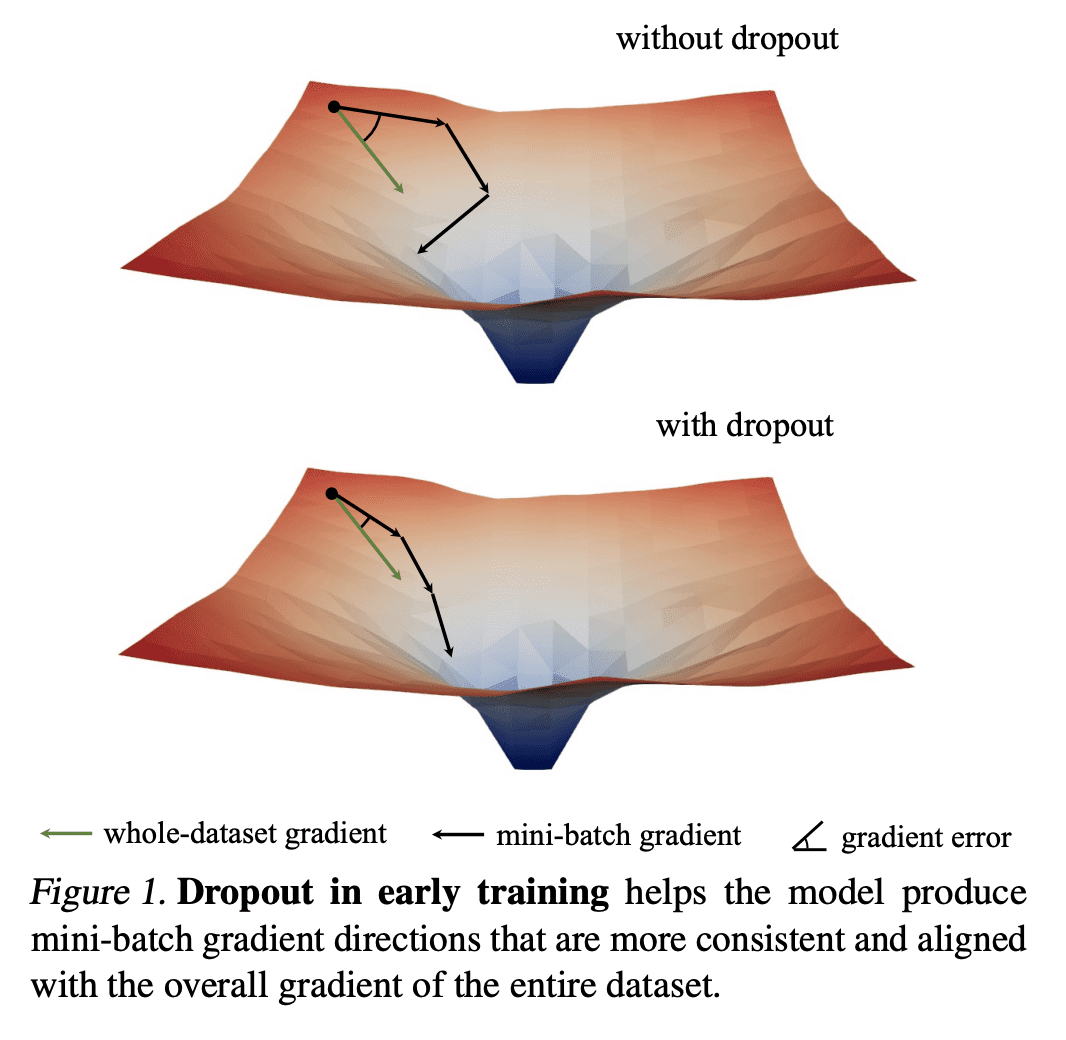
在训练开始时用 Dropout 正则化也可以减轻欠拟合; -
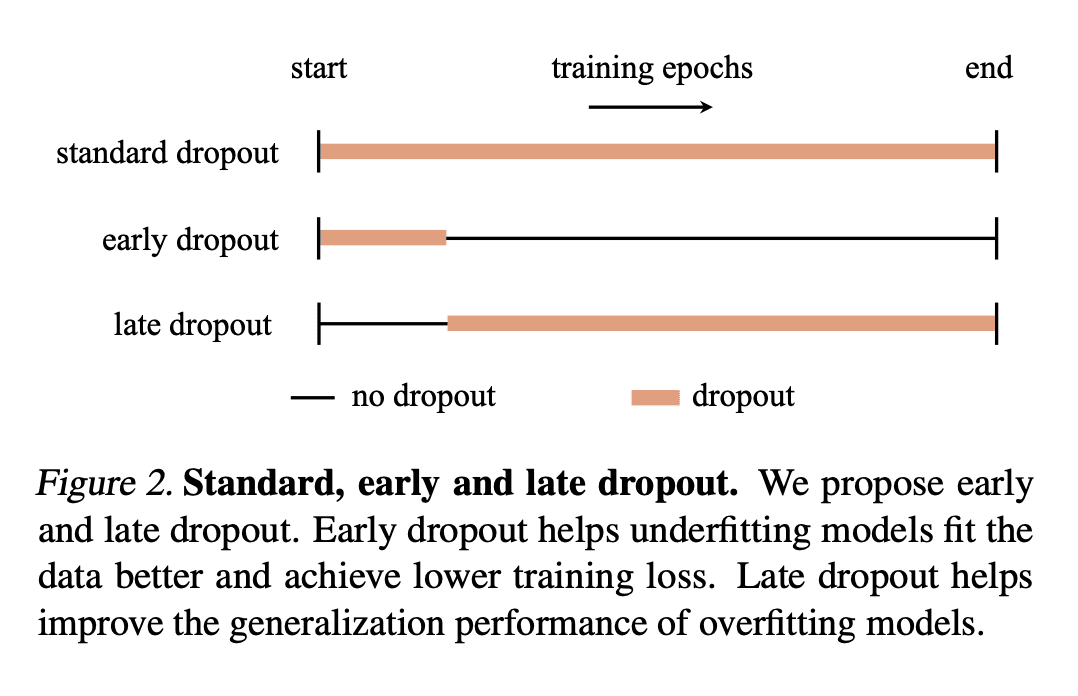
Early dropout 可以帮助欠拟合模型更好地拟合,late dropout 可以提高过拟合模型的泛化程度; -
Dropout 减少了小批量梯度的方向性差异,并使小批量梯度与整个数据集的梯度保持一致,抵制了 SGD 的随机性; -
与没采用 dropout 的模型相比,采用了 early dropout 的模型实现了较低的最终训练损失,在各种视觉任务上提高了泛化精度。
一句话总结:
研究表明,dropout 可缓解训练开始时的欠拟合,提高泛化精度,从而提出了面向欠拟合模型的 early dropout 和面向过拟合模型的 late dropout。
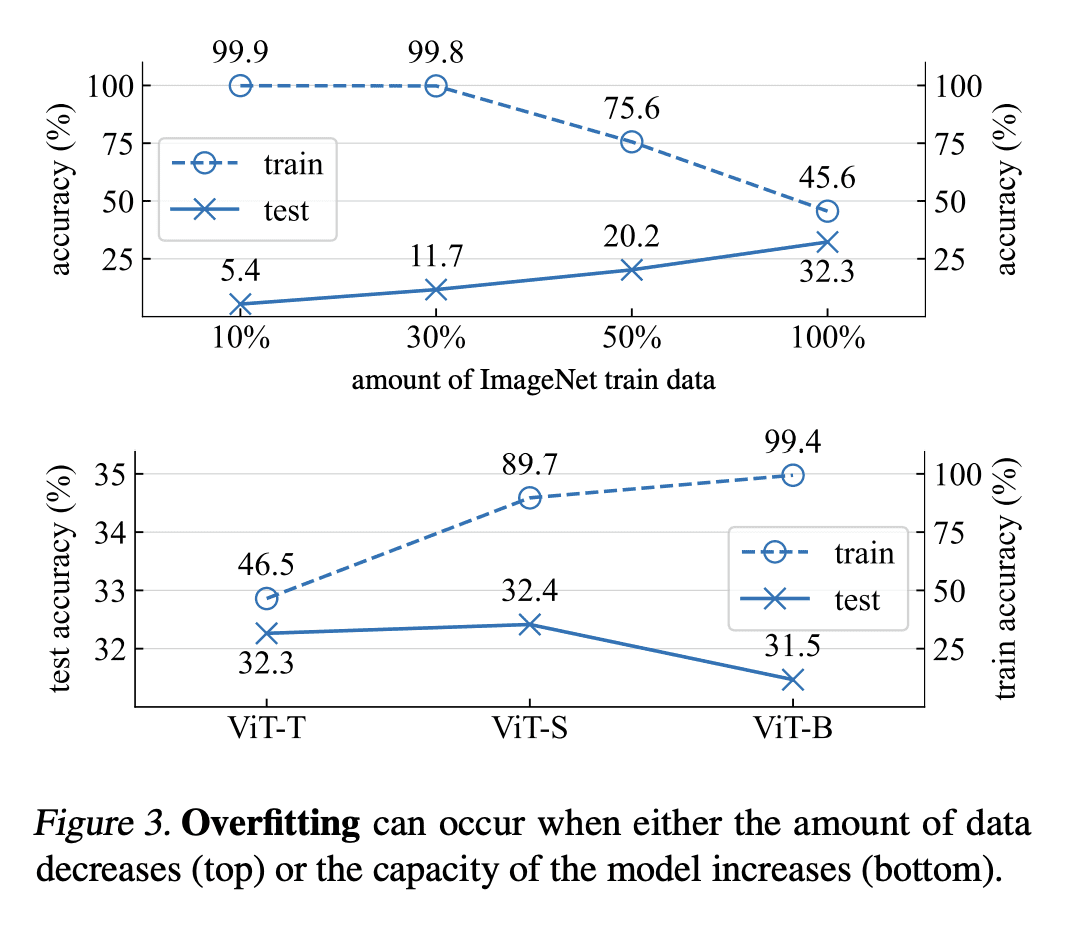
Introduced by Hinton et al. in 2012, dropout has stood the test of time as a regularizer for preventing overfitting in neural networks. In this study, we demonstrate that dropout can also mitigate underfitting when used at the start of training. During the early phase, we find dropout reduces the directional variance of gradients across mini-batches and helps align the mini-batch gradients with the entire dataset's gradient. This helps counteract the stochasticity of SGD and limit the influence of individual batches on model training. Our findings lead us to a solution for improving performance in underfitting models - early dropout: dropout is applied only during the initial phases of training, and turned off afterwards. Models equipped with early dropout achieve lower final training loss compared to their counterparts without dropout. Additionally, we explore a symmetric technique for regularizing overfitting models - late dropout, where dropout is not used in the early iterations and is only activated later in training. Experiments on ImageNet and various vision tasks demonstrate that our methods consistently improve generalization accuracy. Our results encourage more research on understanding regularization in deep learning and our methods can be useful tools for future neural network training, especially in the era of large data. Code is available at this https URL .
论文链接:https://arxiv.org/abs/2303.01500
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢