
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Y Zhang, W Han, J Qin, Y Wang, A Bapna...
[Google]
Google USM: 将自动语音识别扩展到超过100种语言
要点:
-
USM是一种单一的模型,通过在一个大型未标记多语言数据集上进行预训练,并在一个较小的已标记数据集上进行微调,在100多种语言中进行自动与语音识别(ASR); -
与母语人士合作,确定数百种长尾语言的无监督数据,可提高低资源语言的识别性能; -
域内数据对于优化特定域的ASR性能是最好的; -
下游任务的最佳转换器取决于任务。
一句话总结:
通用语音模型(USM)是一种大规模的单独模型,对100多种语言中实现自动语音识别(ASR),通过在大型未标记多语言数据集上进行预训练和在较小的已标记数据集上进行微调,达到最先进的性能。
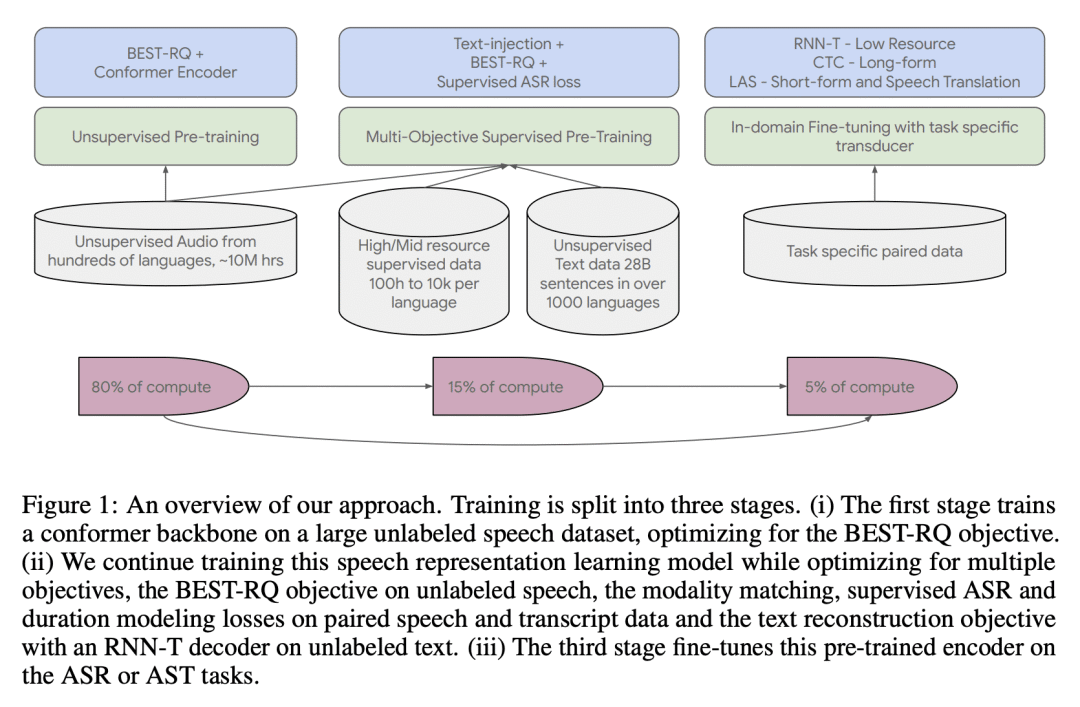
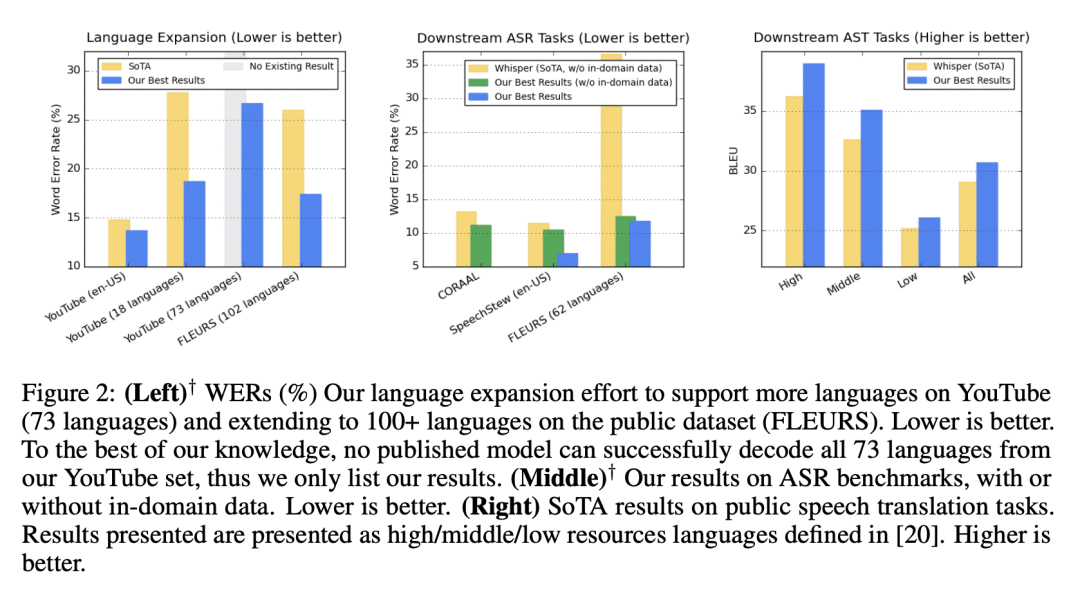
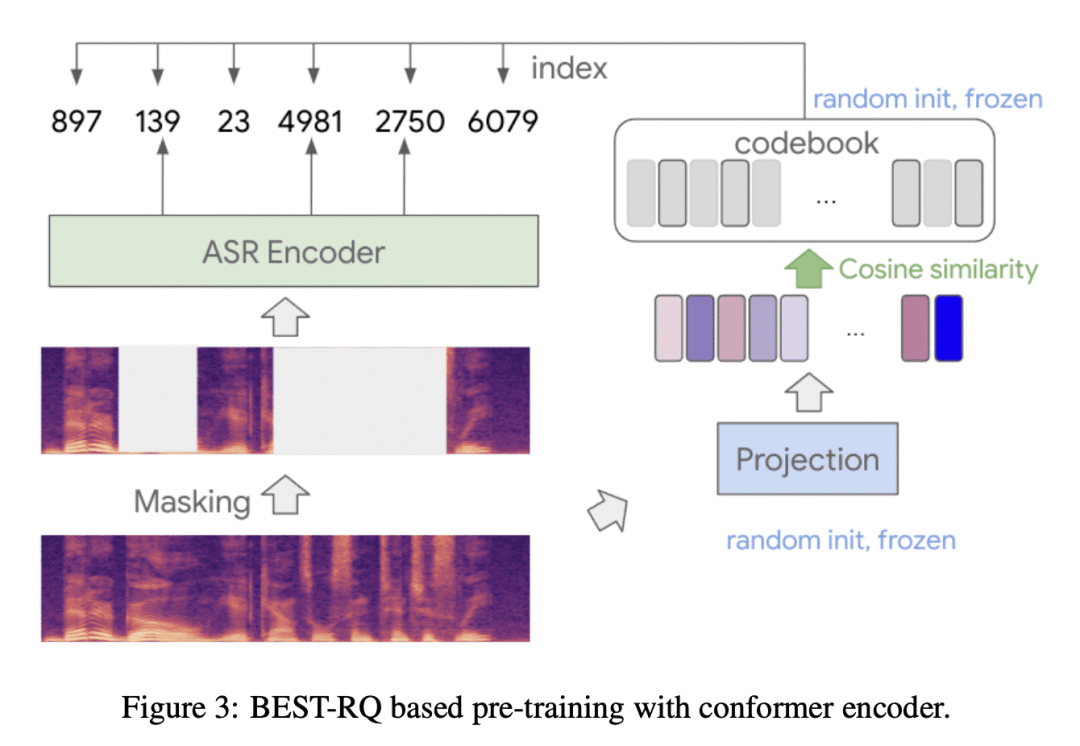
We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
论文链接:https://arxiv.org/abs/2303.01037
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢