

I will tell whether the following news titles are clickbait:
1) The WORST care homes in England: Interactive map reveals the lowest-rated 2,530 residences - so is there one near you?Clickbait: yes
2) Netflix's top 10 most-watched movies of all timeClickbait: yes
3) Peering Through the Fog of InflationClickbait: no
4) You’ll never believe which TV cook this cheeky chap grew up to beClickbait: yes下图为 LLaMA-7B、LLaMA-13B、LLaMA-33B 与 ChatGPT 的更多示例结果:

-- We have a table `events` with columns `event_id`, `timestamp`, `user_id`, `rpc_method`.-- We want to count how many users issued request "Login" over the last week.-- SQL query for this is:-- 7bSELECT count (*)FROM eventsWHERE user_id IN (SELECT user_id
FROM events
WHERE timestamp >= NOW () - INTERVAL 7 DAY)
AND rpc_method = 'Login';-- 13bSELECT COUNT (*)
FROM events
WHERE rpc_method = "Login"
AND UNIX_TIMESTAMP (timestamp) >= UNIX_TIMESTAMP (CURRENT_DATE - INTERVAL 7 DAY)-- 33bSELECT user_id, COUNT (DISTINCT user_id) AS totalFROM eventsWHERE timestamp BETWEEN TIMESTAMP '2013-08-14 00:00:00'
AND TIMESTAMP '2013-08-21 00:00:00' AND rpc_method = 'Login'GROUP BY user_id-- ChatGPTSELECT COUNT (DISTINCT user_id)FROM eventsWHERE rpc_method = 'Login'AND timestamp >= DATE_SUB (NOW (), INTERVAL 1 WEEK);
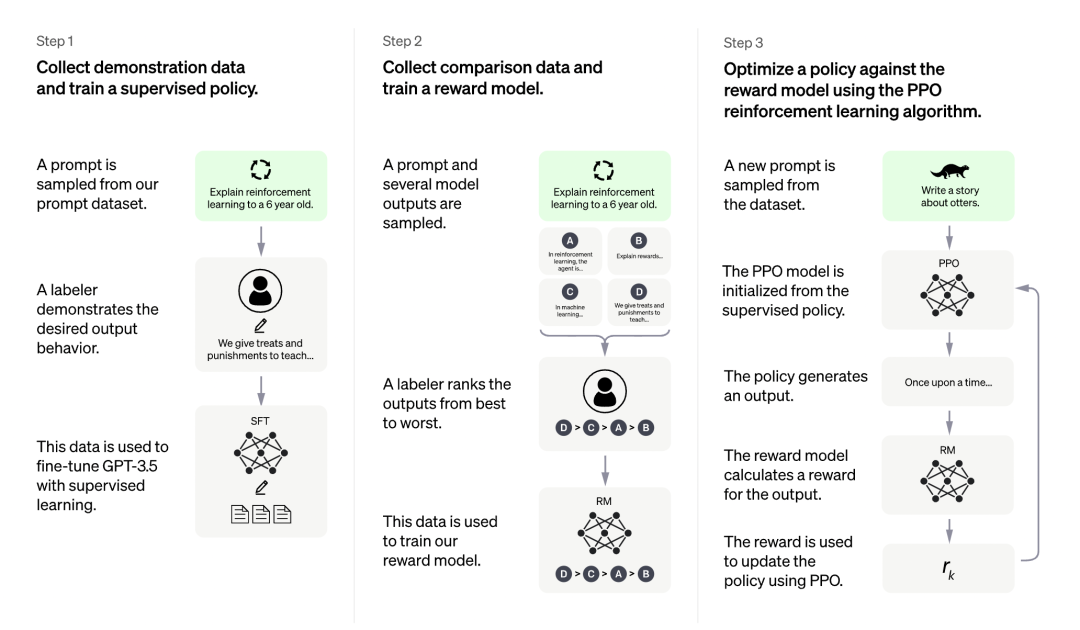
从测试结果来看,LLaMA 在一些任务上表现还不错,但在另一些任务上和 ChatGPT 还有一些差距。如果能像 ChatGPT 一样加入一些「训练秘籍」,效果会不会大幅提升?
在 LLaMA 发布三天后,初创公司 Nebuly AI 开源了 RLHF 版 LLaMA(ChatLLaMA)的训练方法。它的训练过程类似 ChatGPT,该项目允许基于预训练的 LLaMA 模型构建 ChatGPT 形式的服务。项目上线刚刚 2 天,狂揽 5.2K 星。
项目地址:https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
-
ChatLLaMA 是一个完整的开源实现,允许用户基于预训练的 LLaMA 模型构建 ChatGPT 风格的服务; -
与 ChatGPT 相比,LLaMA 架构更小,但训练过程和单 GPU 推理速度更快,成本更低; -
ChatLLaMA 内置了对 DeepSpeed ZERO 的支持,以加速微调过程; -
该库还支持所有的 LLaMA 模型架构(7B、13B、33B、65B),因此用户可以根据训练时间和推理性能偏好对模型进行微调。
更是有研究者表示,ChatLLaMA 比 ChatGPT 训练速度最高快 15 倍。
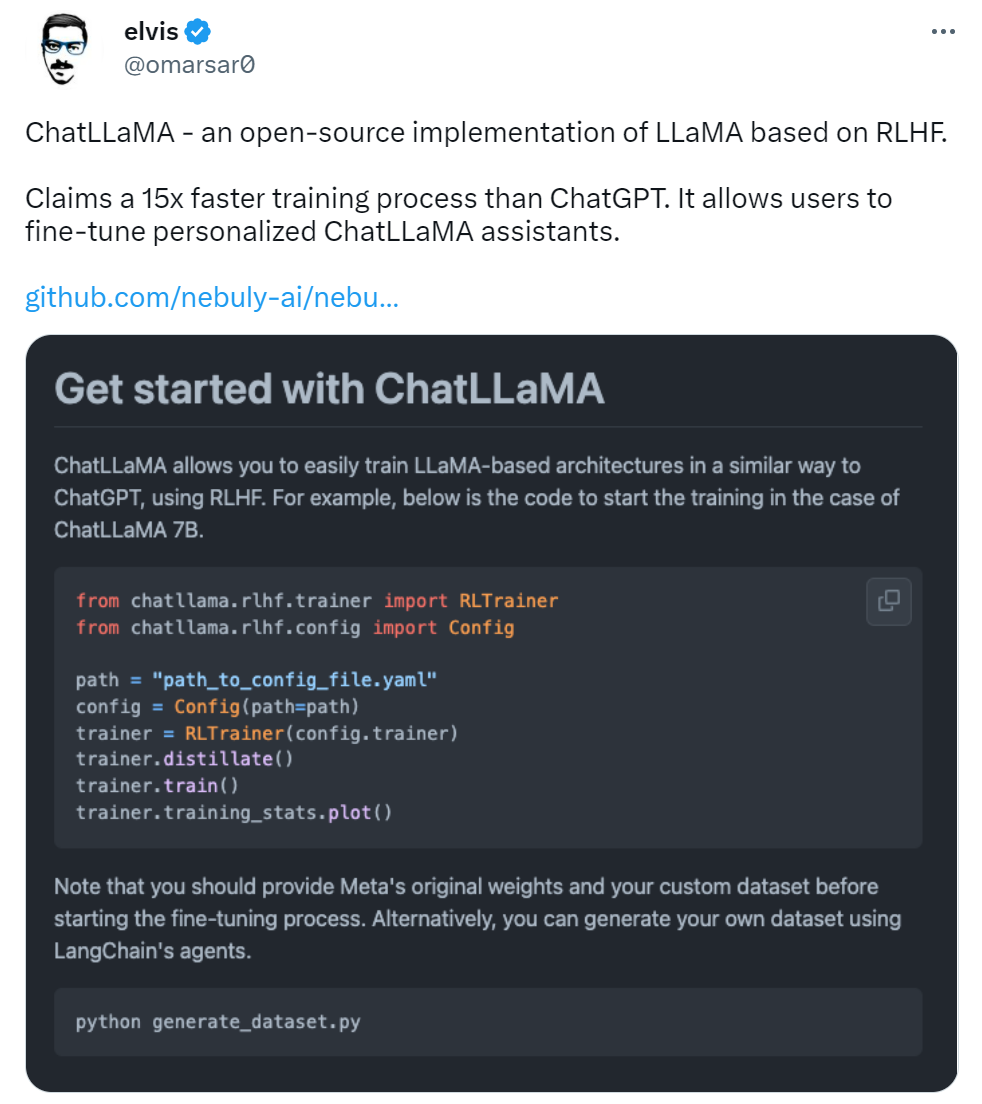
不过有人对这一说法提出质疑,认为该项目没有给出准确的衡量标准。

-
带有微调权重的 Checkpoint; -
用于快速推理的优化技术; -
支持将模型打包到有效的部署框架中。
pip install chatllama-pygit clone https://github.com/facebookresearch/llama.gitcd llamapip install -r requirements.txtpip install -e .
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢