
01 作者信息
Co-first-authors: Chenglei Si, Zhengyan Zhang, Yingfa Chen
02 论文简介
-
中文 tokenizer 普遍以字为最小单位,错失了更细粒度的信息,比如部首 -
提出将字转化 为字形或读音序列后再做 tokenization 的方法,挖掘字内部的细粒度信息 -
结果显示模型更加高效、鲁棒性更强
03 研究设计
研究思路
-
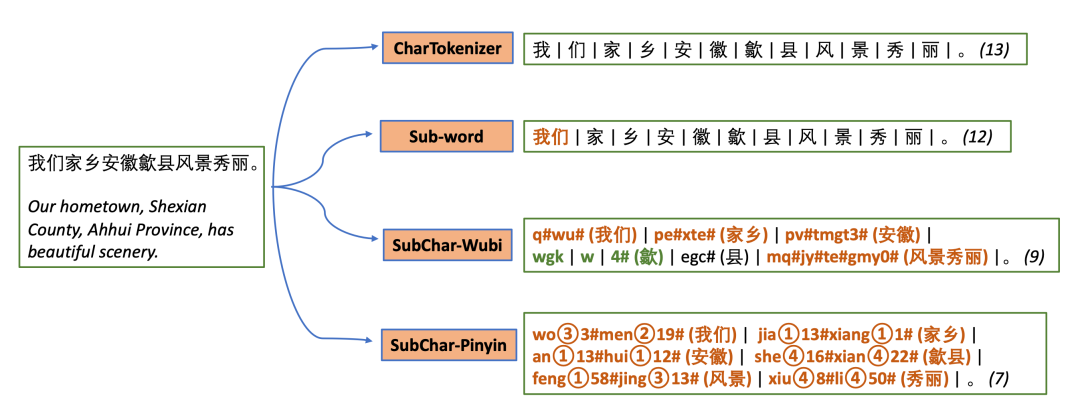
字符编码:把中文字转化成五笔或者拼音序列(同时尝试其他方法,比如注音,郑码等等) -
词汇构建:使用 SentencePiece 或 BPE 进行子词分割,并构建 Vocab -
预训练模型,并在文本分类,句对分类,指代消歧,阅读理解等下游任务中对效率和鲁棒性进行对比评测
04 实验及结论
预训练细节
Vocab size:22675
数据: 2.3G / 22.1G pretrain data from Baidu Baike
层数: 6 / 12
SubChar 模型的平均效果相较于 baseline 基本持平或更好
(1)鲁棒性
-
在下游任务数据集上加入拼音序列相同的同音字噪声,SubChar 不会因为噪声的增加而效果下降
-
不同口音测试样例转化成文本,SubChar 效果也优于 baseline
-
SubChar 能用少量的 token 组合成字,更多的空间可以被用来存词
-
SubChar 可以在更短的时间内达到的更低的 loss
05 优点及展望
优点
-
利用tokenizer的设计挖掘中文字符组成成分的细粒度信息
-
下游任务效果与baseline持平或更好
-
对噪声数据更加鲁棒
-
数据tokenize后长度更短,训练更加高效
改进空间
-
在中文以外的语言上扩展
-
在文本生成上的应用
我们为读者准备了一份高清思维导图,包括了论文中的重点亮点以及直观的示意图。点击下方名片 关注 OpenBMB ,后台回复“论文速读” ,即可领取论文学习高清思维导图和 FreeMind !
本期论文速读视频版已发布于 视频号 和 B站 (视频讲解比文字阅读更加详细易懂哦),欢迎大家观看后 一键三连 !
论文文章及链接:
B站观看链接:
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢