
我们正在见证感知模型的巨大进步,特别是在大规模互联网图像上训练的模型。 然而如何有效地将这些感知模型推广到具身环境的研究还远远不够,这些研究将有助于推进各种相关应用(例如家用机器人)的发展。为了使用尽可能少的标注,有效地收集具身场景中的训练数据成为该任务的主要挑战。
与基于固定数据集的视觉学习不同,具身代理可以在虚拟/真实的3D空间中移动并与环境交互。此外,不像静态感知模型那样将每一个训练样本单独处理,代理在空间中移动时可以从不同的视角对同一个物体进行观测。因此,有效地收集训练样本意味着需要学习一种探索策略,来鼓励代理探索预训练模型表现不佳的区域。
字节跳动的研究者提出了一种新的具身感知中探索信息丰富的轨迹的方法。它通过引入语义分布不一致性和语义分布不确定性奖励来训练探索策略。此外,它通过语义分布不确定性在所学到的轨迹上选择难样本,这可以进一步筛选预训练模型识别良好的样本。实验结果表明,所提出的方法在具有挑战性的Matterport数据集上取得了最好的结果,在真机实验中也证明了该方法的稳健性。
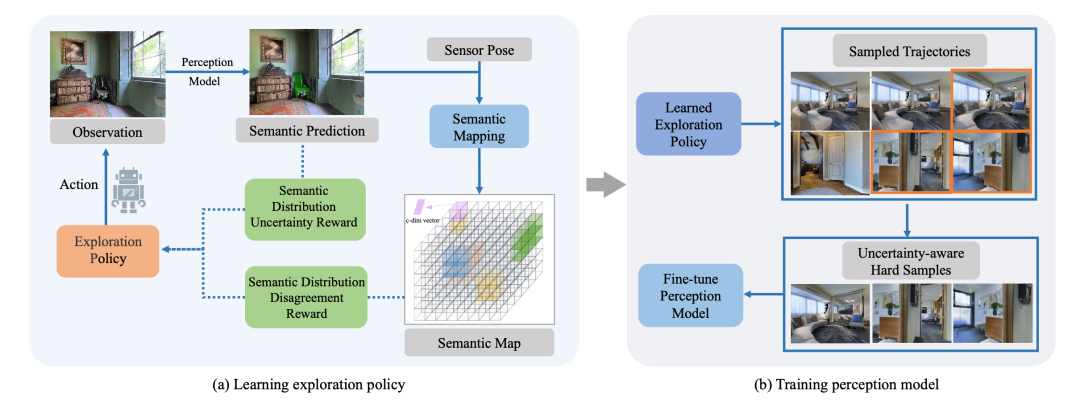
注:学习的目标是训练拥有在互联网图像上预训练过的感知模型的具身代理去有效地探索信息丰富的轨迹和样本,然后针对收集到的数据微调感知模型,使其可以很好地应用到新环境中。如上图所示,模型主要包括两部分,探索部分旨在利用3D语义分布图,以自监督的方式通过语义分布不一致性和不确定性来学习探索轨迹。此外,对学习到轨迹利用不确定性来收集轨迹上的难样本。对收集到的图像进行语义标注后,在感知学习阶段微调感知模型。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢