
本文围绕着对话式 AI 搜索(不是对话 AI)的技术路线作出一些猜想,并浅谈相关的 NLP 核心技术或任务。
[ 笔者没有搜广推的工作经验,研究上有一点问答背景,工作上有一点对话背景。如果关于搜索的内容写得有问题,还望批评指正。]
Bing对话式AI搜索的产品形态
(一) 与传统搜索结合
直接明了,左侧网页排序结果,右侧 AI 答复。我们关注 AI 答复的内容:
-
汇总了不同来源的信息,并用虚线及引用符号注明来源;
-
加粗与答案相关的实体或短语;
-
层次分明的行文结构,流畅且语法正确的文本;
-
根据提问和回复的内容,给出了追问候选;
-
可以对 AI 答复进行正向或负向的反馈,并给出进入对话形态的入口。
(二) 像ChatGPT一样对话提问
对话即是交互,是传统搜索以及上述形态那种单轮技术向多轮技术的延伸。在问答形式上,新的输入可以是对原问题的修正,对 AI 答复的追问或否定,也可以是独立的新问题,等等。这也对算法和模型能力的要求更上了一个层次。
从视频中看到,相同的问题,AI 回答的文本内容是一致的,但拆成了多条内容来回复。为啥那么做?为了让回复的过程更像是在对话吧,估计是有个断句算法或小模型来支持的。
回归主题,在对话形态下,Bing 所做的事情就不只是搜索了,可以发挥起 ChatGPT 的所有的能力,比如闲聊,或根据用户的指令(Instruction)完成任务或工作等等。这里其实可以大胆猜想:Bing 里是否有一个模型来判断用户的意图是否是搜索,或者回答用户的问题是否要依赖搜索?然后去决定是根据原 Bing 搜索出来的信息去汇总,或是完全依赖 ChatGPT 输出。
写到这里,后背一凉,你说国内厂商会不会也搞个模型去选择是否调用 ChatGPT 的 API 呢?套个壳再搞点自己行业或领域特有的对话模型,然后宣称自研技术……这是诈骗,是诈骗啊。
本篇文章收缩视野,聚焦在对话式 AI 搜索上,暂时放下对 ChatGPT 的其他各项能力的执念,来思考:通往对话式 AI 搜索是否有捷径?我个人的答案:有,且不止一个。
技术路线“先检索后总结”
我们先看一下 Bing 官方是怎么说的:先检索后总结。个人认为这种方式是必然的,原因有以下几点:
1. ChatGPT 存在一定的信息滞后性。粗糙地说,基于 Transformer 的语言模型在训练过程中,将文本中语法、概念、常识等信息(或知识)转换为了模型中的参数 [1][2]。模型参数量越大,其能记忆住的信息就越多,训练足够充分的大语言模型就具备了一定通用化的能力。
如今,大模型仍然相对黑盒,信息更新需要参数更新,更新参数的一般方法都是再训练模型,而训练超大语言模型是费钱费时的,因而信息滞后。针对这个缺陷,还可以期待一下直接编辑权重的方法 [3],只是还需要一定的积累和验证,再发展成熟。
2. ChatGPT 容易犯事实性错误(这里心疼 Bard 一波),在搜索中这个缺陷会被放大。语言模型的语料很大程度上来自于互联网,暂且排除那些充斥着的虚假信息,正常人在互联网中写下的内容,都有可能存在错误。模型本身是不具备鉴别信息的能力的,这些错误数据都或多或少地参与到 GPT 甚至 ChatGPT 的训练中,导致了错误的输出结果。
3. Bing 的“先检索后总结”,对模型来说可以降低参数量门槛,因为原先模型是自己输出信息,现在是整理信息,难度小了,而对生成的内容来说,还可以做到信息可控。
检索是搜索引擎的工作,做好总结就完成了前面提到第一个形态的 123。
信息检索:从文档到语句,从语句到短语
传统搜索引擎是根据用户查询,按相关性从高到低排序,反馈多个网页链接。很多网页里的内容并不是都跟输入的查询相关的,这些内容都交给下一阶段的模型去做总结,势必会带来很大的噪音,过长的文本还会给 Transformer 计算带来负担。因此,信息必须要精炼:
-
精炼到语句粒度,保持语义信息的连贯与递进,有利于下一阶段生成模型对文本逻辑的理解。
-
精炼到短语粒度,可支持像 Bing 那样对答案相关实体或短语的加粗或高亮。
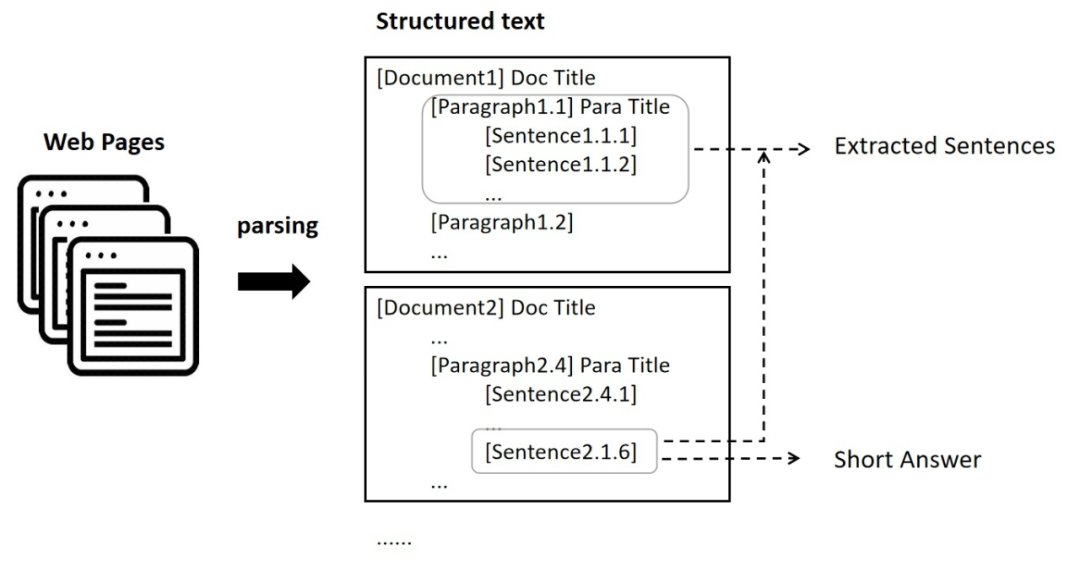
在语句粒度上,这个精炼过程常见于 NLP 问答任务(Question Answering,QA),跟 HotpotQA [4] 抽取 Supporting Facts,TriviaQA [5] 抽取Evidences,NaturalQuestion [6] 抽取 Long Answers 都是一样的。
在短语粒度上,如果用户问题可以用短答案回答,就完全等同于 MRC。如果问题根本不存在短答案的形式,也可以抽取问题中的关键词,计算其与文档中的词或短语的相关性。
对于这两个问题,模型仍然依赖于预训练语言模型,不过小模型就达到不错的效果,但最关键的还是数据。
其实,这些早已是搜索引擎的必备能力,搜索引擎可以根据你的问题在网页的语句中抽取或高亮你要寻找的答案及句子。下面是一些示例,可以看到这个能力大家都是有的,只不过要通往对话式 AI 搜索,能力还需往多文档、多语句、多短语上延伸一下(说白了还是数据问题)。
基于多篇文档提炼出来的信息,再次汇总整理,形成一段答复。这描述起来又像是另一个冷门的 NLP 任务——基于 Query 的摘要生成(Query-base Summarization)[7],但是这方面的研究工作实在太少了,中英文数据都不多,所以暂不参考。我尝试去拆解这一问题:
最小语句集合的发现:假定上一阶段提炼出的语句,对于回答问题来说是充足的,那么从这些语句里提取出一个支持回答该问题的最小集合,作为后续生成回复的草稿。
-
-
在任务上变成了语句分类任务。
-
在数据标注上,将语句按文档的相关性进行排序后依次标注,ground-truth 也是唯一的。
-
在模型上,将问题 query 与提炼后的语句 sentences 拼接,用语言模型编码后用 sentence embeding 作分类。其实方法上又回到了上一阶段的语句粒度任务,合并在一个模型里感觉也行。
-
更多内容请访问原文
https://mp.weixin.qq.com/s/AIIu4rRi1WZRQn3oHtuwdg
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢