
根据Zeta Alpha的整理,Top100论文是:
| Title | Tweets | Citations | Organizations | Countries | Org Types |
|---|---|---|---|---|---|
| AlphaFold Protein Structure Database: massively expanding the structural coverage of protein-sequence space with high-accuracy models | 1331 | European Molecular Biology Laboratory | - | Academia | |
| ColabFold: making protein folding accessible to all | 1138 | Max Planck Institute for Multidisciplinary Sciences | Germany | Academia | |
| A ConvNet for the 2020s | 857.0 | 835 | Meta, UC Berkeley | USA, USA | Industry, Academia |
| Hierarchical Text-Conditional Image Generation with CLIP Latents | 105.0 | 718 | OpenAI | USA | Industry |
| PaLM: Scaling Language Modeling with Pathways | 445.0 | 426 | USA | Industry | |
| Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding | 2462.0 | 390 | USA | Industry | |
| Instant Neural Graphics Primitives with a Multiresolution Hash Encoding | 11.0 | 342 | NVIDIA | USA | Industry |
| SignalP 6.0 predicts all five types of signal peptides using protein language models | 274 | Technical University of Denmark, ETH Zurich | Denmark, Switzerland | Academia, Academia | |
| Swin Transformer V2: Scaling Up Capacity and Resolution | 87.0 | 266 | University of Science and Technology of China | China | Academia |
| Training language models to follow instructions with human feedback | 448.0 | 254 | OpenAI | USA | Industry |
| Chain of Thought Prompting Elicits Reasoning in Large Language Models | 378.0 | 224 | USA | Industry | |
| Flamingo: a Visual Language Model for Few-Shot Learning | 71.0 | 218 | DeepMind | UK | Industry |
| Classifier-Free Diffusion Guidance | 53.0 | 194 | USA | Industry | |
| Magnetic control of tokamak plasmas through deep reinforcement learning | 0.0 | 194 | DeepMind | UK | Industry |
| data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language | 0.0 | 191 | Meta | USA | Industry |
| OPT: Open Pre-trained Transformer Language Models | 812.0 | 187 | Meta | USA | Industry |
| BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation | 79.0 | 184 | Salesforce | USA | Industry |
| A Generalist Agent | 231.0 | 180 | DeepMind | UK | Industry |
| LaMDA: Language Models for Dialog Applications | 473.0 | 180 | USA | Industry | |
| CMT: Convolutional Neural Networks Meet Vision Transformers | 0.0 | 172 | University of Sydney | Australia | Academia |
| Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model | 271.0 | 158 | Microsoft | USA | Industry |
| What Makes Good In-Context Examples for GPT-3? | 0.0 | 157 | Duke University | USA | Academia |
| Ensemble unsupervised autoencoders and Gaussian mixture model for cyberattack detection | 145 | Ningbo University of Technology | China | Academia | |
| Training Compute-Optimal Large Language Models | 144 | DeepMind | UK | Industry | |
| Learning robust perceptive locomotion for quadrupedal robots in the wild | 3.0 | 141 | ETH Zurich | Switzerland | Academia |
| Do As I Can, Not As I Say: Grounding Language in Robotic Affordances | 82.0 | 135 | USA | Industry | |
| How Do Vision Transformers Work? | 193.0 | 129 | Yonsei University, NAVER | South Korea, South Korea | Academia, Industry |
| Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs | 30.0 | 127 | Tsinghua University | China | Academia |
| Large Language Models are Zero-Shot Reasoners | 862.0 | 124 | University of Tokyo | Japan | Academia |
| Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time | 0.0 | 122 | University of Washington | USA | Academia |
| Patches Are All You Need? | 117.0 | 116 | Carnegie Mellon University | USA | Academia |
| Competition-Level Code Generation with AlphaCode | 113 | DeepMind | UK | Industry | |
| TensoRF: Tensorial Radiance Fields | 73.0 | 110 | ShanghaiTech University | China | Academia |
| Video Diffusion Models | 0.0 | 103 | USA | Industry | |
| Data Analytics for the Identification of Fake Reviews Using Supervised Learning | 102 | Dr. Babasaheb Ambedkar Marathwada University | India | Academia | |
| Visual Prompt Tuning | 26.0 | 102 | Cornell University | USA | Academia |
| DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection | 15.0 | 100 | Hong Kong University of Science and Technology | Hong Kong | Academia |
| VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training | 66.0 | 100 | Nanjing University, Tencent | China, China | Academia, Industry |
| Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? | 199.0 | 99 | University of Washington, Meta | USA, USA | Academia, Industry |
| BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers | 11.0 | 96 | Nanjing University, Shanghai AI Lab | China, China | Academia, Academia |
| Conditional Prompt Learning for Vision-Language Models | 51.0 | 93 | Nanyang Technological University | Singapore | Academia |
| Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution | 151.0 | 93 | Stanford University | USA | Academia |
| Measuring and Improving the Use of Graph Information in Graph Neural Networks | 1.0 | 93 | Chinese University of Hong Kong | Hong Kong | Academia |
| Exploring Plain Vision Transformer Backbones for Object Detection | 205.0 | 91 | Meta | USA | Industry |
| GeoDiff: a Geometric Diffusion Model for Molecular Conformation Generation | 26.0 | 90 | Mila, University of Montreal | Canada, Canada | Academia, Academia |
| OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework | 91.0 | 88 | Alibaba Group | China | Industry |
| Block-NeRF: Scalable Large Scene Neural View Synthesis | 641.0 | 86 | UC Berkeley | USA | Academia |
| Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents | 24.0 | 86 | UC Berkeley | USA | Academia |
| Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models | 881.0 | 81 | University of Notre Dame | USA | Academia |
| Outracing champion Gran Turismo drivers with deep reinforcement learning | 80 | Sony | Japan | Industry | |
| BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning | 10.0 | 77 | USA | Industry | |
| DN-DETR: Accelerate DETR Training by Introducing Query DeNoising | 0.0 | 74 | Hong Kong University of Science and Technology | Hong Kong | Academia |
| Equivariant Diffusion for Molecule Generation in 3D | 131.0 | 73 | University of Amsterdam | Netherlands | Academia |
| Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images | 6.0 | 73 | NVIDIA | USA | Industry |
| GPT-NeoX-20B: An Open-Source Autoregressive Language Model | 50.0 | 72 | EleutherAI | - | Industry |
| Online reinforcement learning multiplayer non-zero sum games of continuous-time Markov jump linear systems | 72 | Anhui University | China | Academia | |
| Detecting Twenty-thousand Classes using Image-level Supervision | 35.0 | 70 | Meta | USA | Industry |
| Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network | 68 | Wuhan University | China | Academia | |
| LAION-5B: An open large-scale dataset for training next generation image-text models | 53.0 | 66 | LAION | Germany | Industry |
| Denoising Diffusion Restoration Models | 0.0 | 65 | Technion | Israel | Academia |
| VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance | 175.0 | 64 | EleutherAI | - | Industry |
| CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields | 33.0 | 63 | City University of Hong Kong | Hong Kong | Academia |
| Solving Quantitative Reasoning Problems with Language Models | 139.0 | 63 | USA | Industry | |
| Masked Autoencoders As Spatiotemporal Learners | 120.0 | 61 | Meta | USA | Industry |
| Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language | 499.0 | 59 | USA | Industry | |
| ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond | 2.0 | 59 | University of Sydney | Australia | Academia |
| Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks | 178.0 | 58 | Microsoft | USA | Industry |
| Language-driven Semantic Segmentation | 95.0 | 57 | Cornell University | USA | Academia |
| Vision-Language Pre-Training with Triple Contrastive Learning | 34.0 | 56 | University of Texas at Arlington | USA | Academia |
| Deep Reinforcement Learning-Based Path Control and Optimization for Unmanned Ships | 55 | Tongji University | China | Academia | |
| EquiBind: Geometric Deep Learning for Drug Binding Structure Prediction | 208.0 | 54 | MIT | USA | Academia |
| Omnivore: A Single Model for Many Visual Modalities | 89.0 | 54 | Meta | USA | Industry |
| Quantifying Memorization Across Neural Language Models | 106.0 | 54 | USA | Industry | |
| DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection | 36.0 | 53 | Johns Hopkins University | USA | Academia |
| Genetic Algorithm-Based Trajectory Optimization for Digital Twin Robots | 53 | Wuhan University of Science and Technology | China | Academia | |
| Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors | 280.0 | 53 | Meta | USA | Industry |
| Discovering faster matrix multiplication algorithms with reinforcement learning | 52 | DeepMind | UK | Industry | |
| DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation | 221.0 | 52 | Google, Boston University | USA, USA | Industry, Academia |
| PETR: Position Embedding Transformation for Multi-View 3D Object Detection | 4.0 | 52 | Megvii | China | Industry |
| Protein structure predictions to atomic accuracy with AlphaFold | 51 | DeepMind | UK | Industry | |
| ABAW: Valence-Arousal Estimation, Expression Recognition, Action Unit Detection & Multi-Task Learning Challenges | 2.0 | 50 | Queen Mary University of London | UK | Academia |
| HumanNeRF: Free-viewpoint Rendering of Moving People from Monocular Video | 72.0 | 50 | University of Washington | USA | Academia |
| UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models | 38.0 | 49 | University of Hong Kong | Hong Kong | Academia |
| A Systematic Evaluation of Large Language Models of Code | 61.0 | 48 | Carnegie Mellon University | USA | Academia |
| Robust Speech Recognition via Large-Scale Weak Supervision | 40.0 | 48 | OpenAI | USA | Industry |
| Diffusion Models: A Comprehensive Survey of Methods and Applications | 274.0 | 47 | Peking University | China | Academia |
| Can language models learn from explanations in context? | 113.0 | 46 | DeepMind | UK | Industry |
| NELA-GT-2021: A Large Multi-Labelled News Dataset for The Study of Misinformation in News Articles | 9.0 | 46 | Rensselaer Polytechnic Institute | USA | Academia |
| ActionFormer: Localizing Moments of Actions with Transformers | 0.0 | 44 | Nanjing University, 4Paradigm Inc. | China, China | Academia, Industry |
| Least-to-Most Prompting Enables Complex Reasoning in Large Language Models | 44 | USA | Industry | ||
| Diffusion-LM Improves Controllable Text Generation | 253.0 | 43 | Stanford University | USA | Academia |
| Overview of The Shared Task on Homophobia and Transphobia Detection in Social Media Comments | 0.0 | 41 | National University of Ireland Galway | Ireland | Academia |
| Text and Code Embeddings by Contrastive Pre-Training | 23.0 | 40 | OpenAI | USA | Industry |
| Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality | 125.0 | 40 | Hugging Face | USA | Industry |
| BLOOM: A 176B-Parameter Open-Access Multilingual Language Model | 325.0 | 39 | BigScience Team | France | Industry |
| Red Teaming Language Models with Language Models | 40.0 | 39 | DeepMind, New York University | UK, USA | Industry, Academia |
| Transformer Memory as a Differentiable Search Index | 372.0 | 39 | USA | Industry | |
| Torsional Diffusion for Molecular Conformer Generation | 109.0 | 38 | MIT | USA | Academia |
| Unified Contrastive Learning in Image-Text-Label Space | 66.0 | 37 | Microsoft | USA | Industry |
| Benchmarking Generalization via In-Context Instructions on 1, 600+ Language Tasks | 149.0 | 36 | University of Washington | USA | Academia |
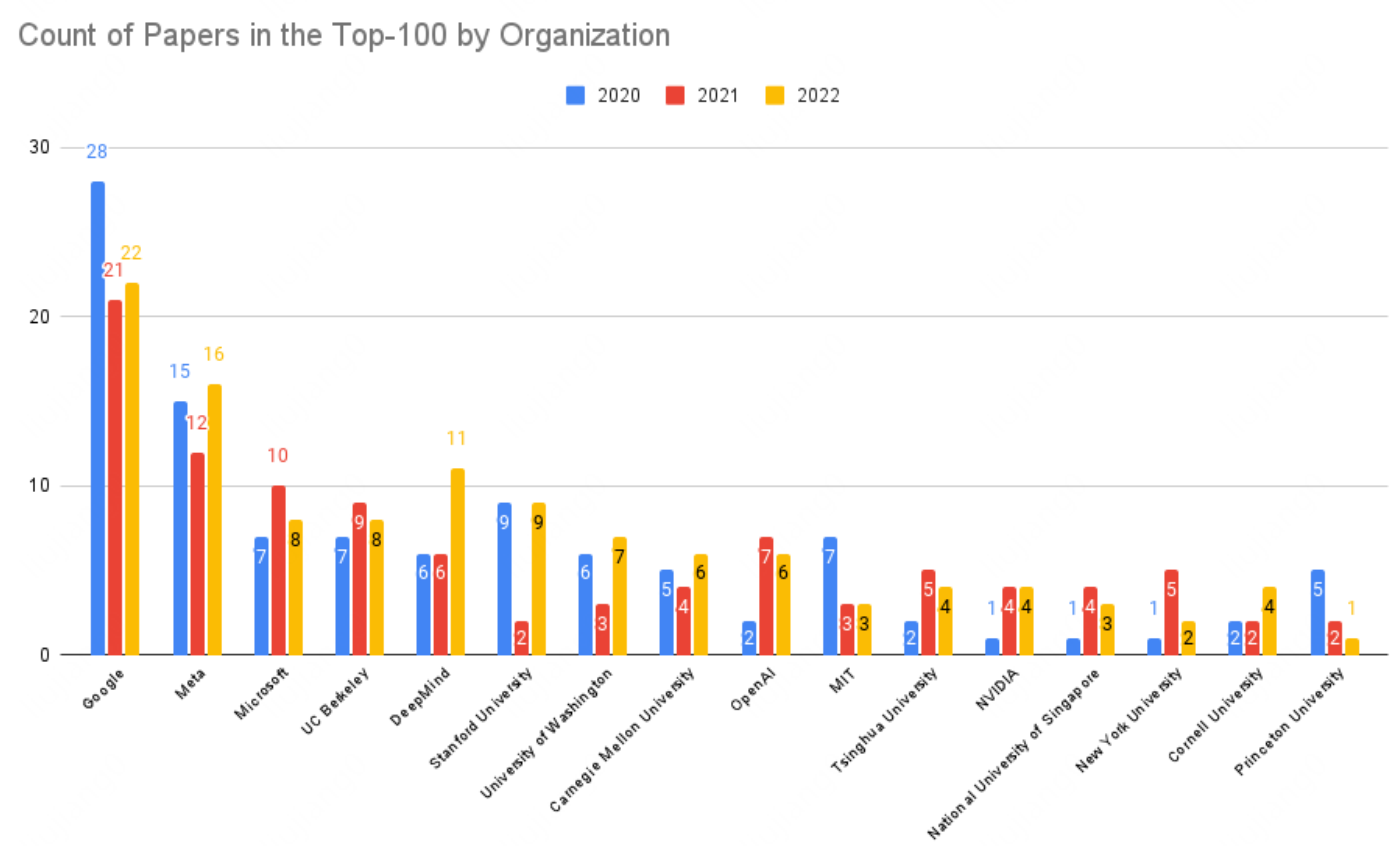
按数量,Google、Meta和微软排在前三,国内只有清华大学上榜:
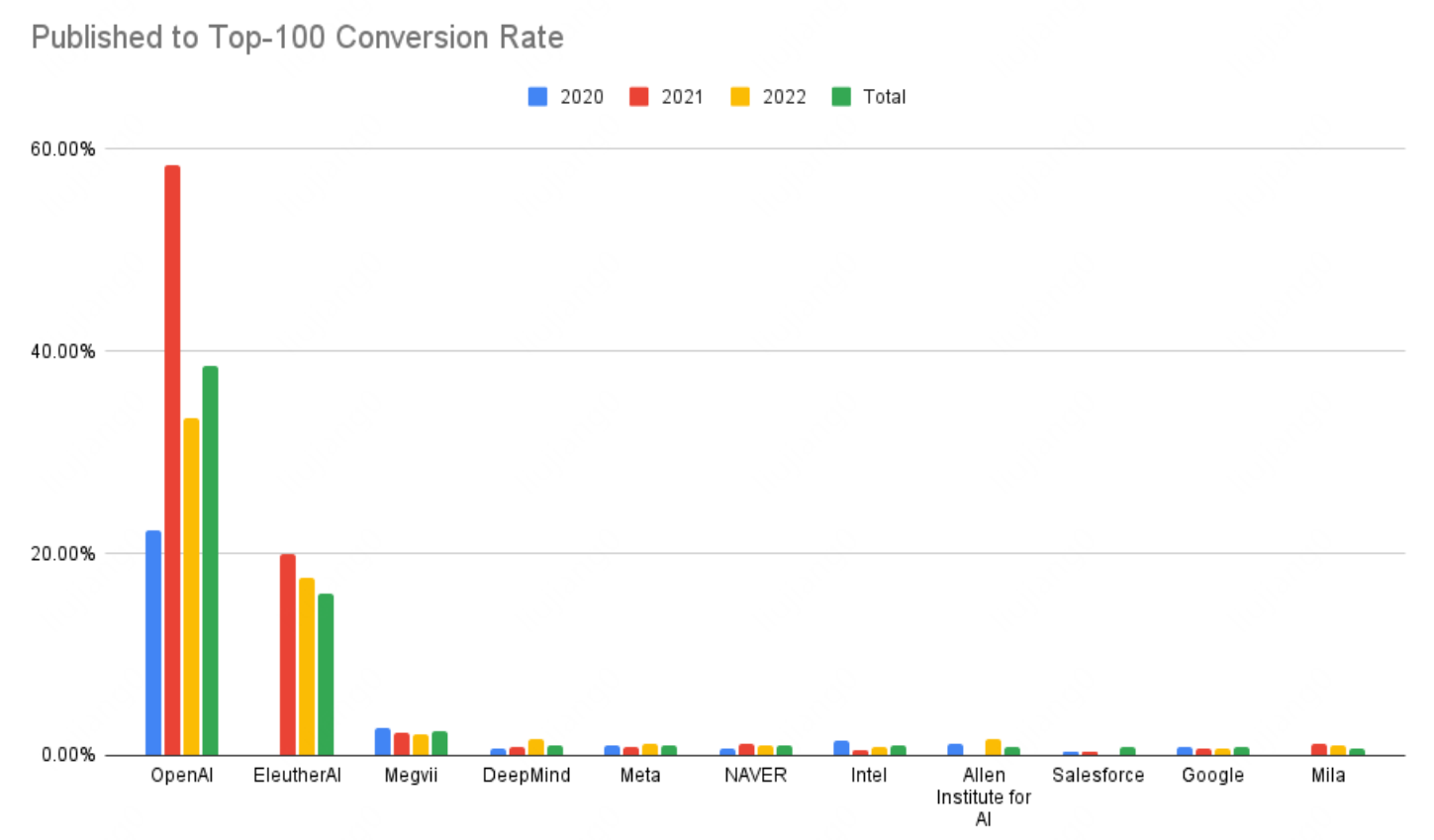
从论文质量(进入Top100的比例)来看,OpenAI果然是非常出众的:
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢