
Prompt, Generate, then Cache: Cascade of Foundation Models makes Strong Few-shot Learners
CaFo提出一种基础模型的级联,以纳入来自不同预训练范式的多样化知识,从而更好地进行少样本学习。
作者:Renrui Zhang, Xiangfei Hu, Bohao Li, Siyuan Huang, Hanqiu Deng, Hongsheng Li, Yu Qiao, Peng Gao
[Shanghai Artificial Intelligence Laboratory & University of Chinese Academy of Sciences]
-
CaFo 是基础模型的级联,结合了来自各种预训练范式的不同的先验知识,以便在视觉识别中更好地进行少样本学习; -
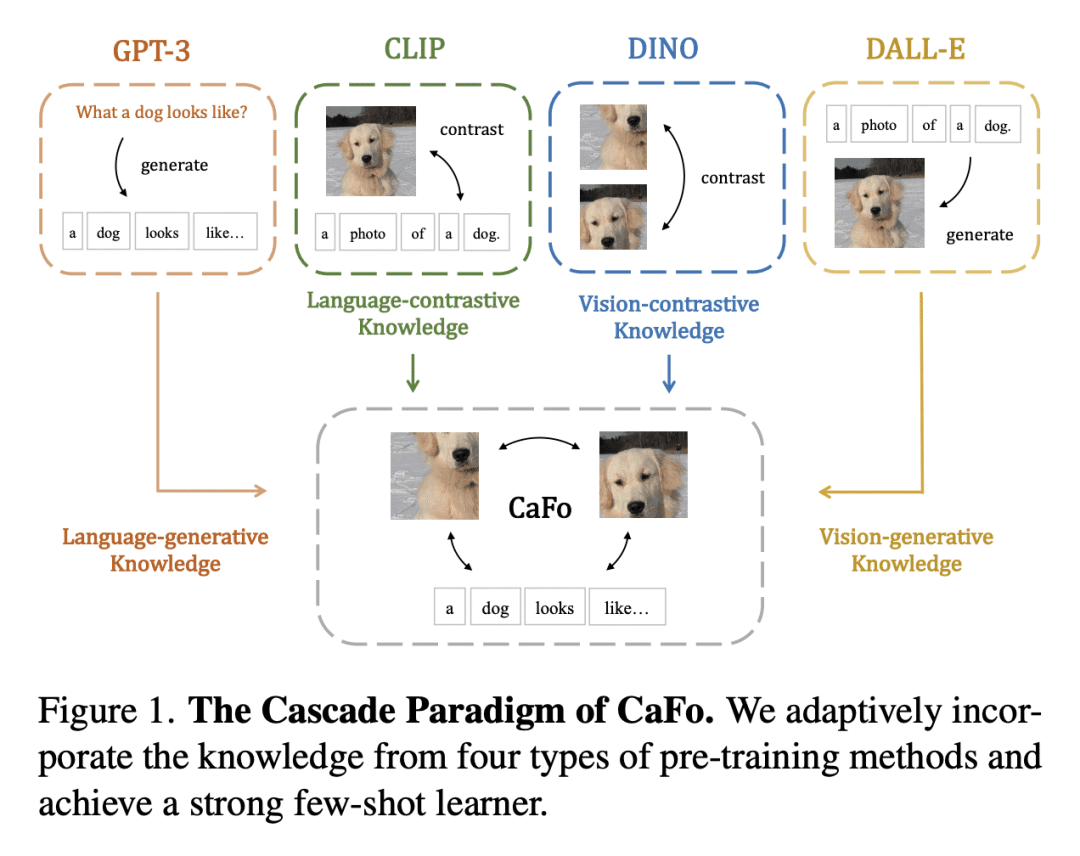
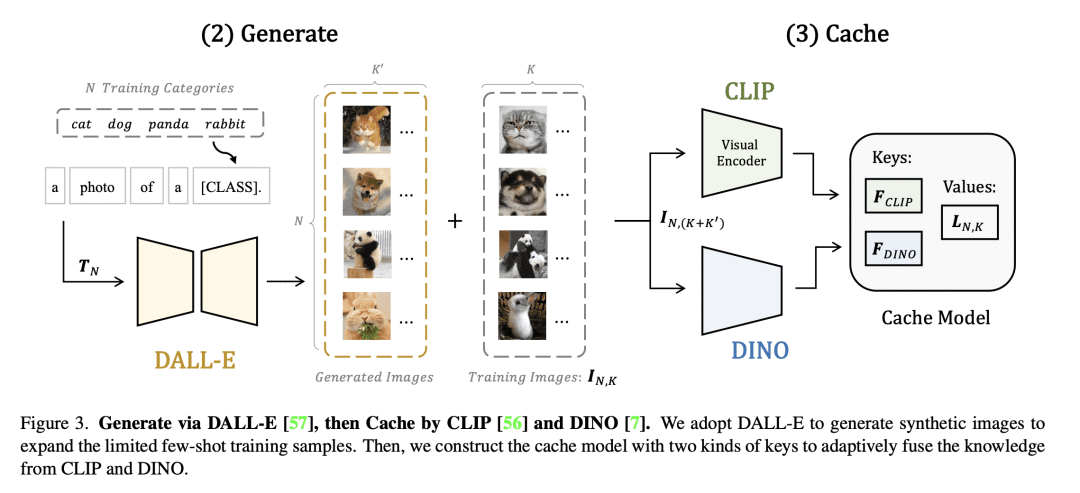
CaFo遵循"提示,生成,再缓存"的流水线,利用 GPT-3 产生提示 CLIP 的文本输入,采用 DALL-E 来扩展少样本训练数据,并引入一个可学习的缓存模型来自适应地混合来自 CLIP 和 DINO 的预测; -
CaFo 通过利用更多的语义提示,丰富有限的少样本训练数据,以及自适应地组合不同的预测,在11个数据集上实现了最先进的少样本学习性能,而不用额外的标注数据。
论文地址:https://arxiv.org/abs/2303.02151


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢