
谷歌在去年11月宣布了1000种语言模型,该模型将支持世界上1000种最常的语言,然而,其中一些语言被不到2000万人使用,因此一个核心挑战是如何支持使用者相对较少或可用数据有限的语言。
3月6日,谷歌在官网博客上发布了分享更多关于通用语音模型(USM)的分析信息。USM是一个最先进的语音模型系列,其2B参数训练有1200万小时的语音和280亿个文本句子,跨越300多种语言。
谷歌博客地址:https://ai.googleblog.com/2023/03/universal-speech-model-usm-state-of-art.html
通用语音模型(USM)是一系列最先进的语音模型,其2B参数训练有1200万小时的语音和280亿行文本,涵盖300多种语言。USM用于YouTube(例如,用于隐藏式字幕),可以在英语和普通话等广泛使用的语言上执行自动语音识别(ASR),也可以在旁遮普语、阿萨姆语、Santhali、巴厘语、肖纳语、马达加语、卢干达语、罗、班巴拉语、索加、马宁卡语、科萨语、阿坎语、林加拉语、奇切瓦语、恩科雷语、恩泽马语等语言上执行自动语音识别(ASR)。其中一些语言只有不到2000万人使用,因此很难找到必要的训练数据。
利用大型无标签的多语言数据集来预训练我们模型的编码器,并对一组较小的标记数据进行微调,使我们能够识别这些代表性不足的语言。此外,我们的模型培训过程对适应新语言和数据是有效的。
跨多种语言的性能
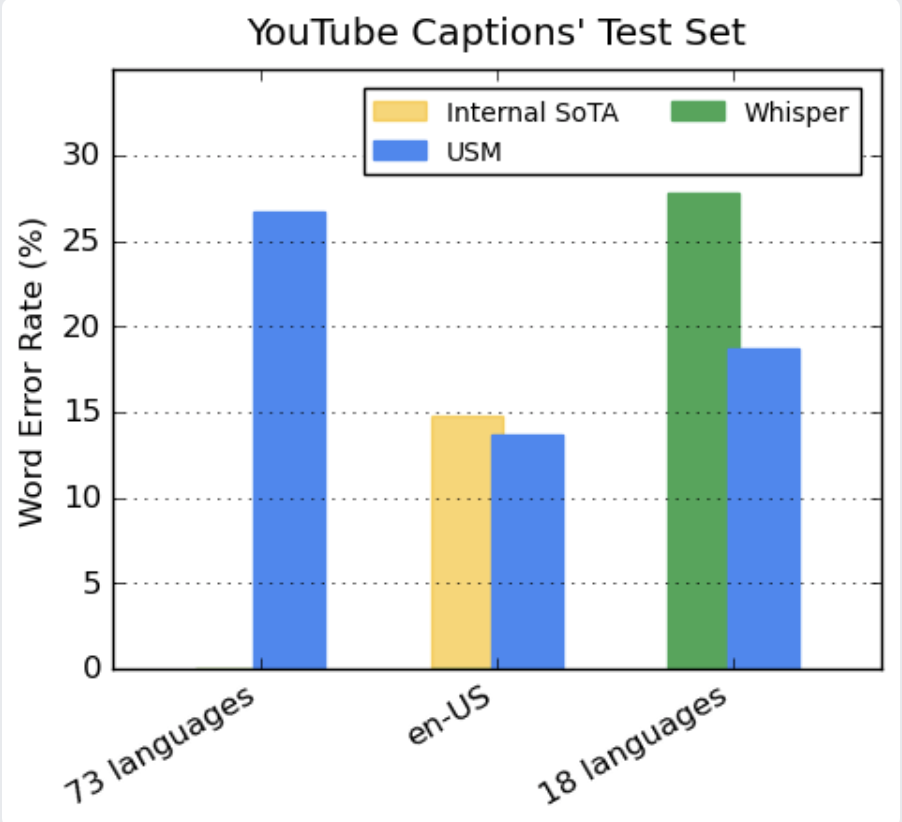
我们的编码器通过预培训整合了300多种语言。我们通过对YouTube Caption的多语言语音数据进行微调,展示了预训练编码器的有效性。受监督的YouTube数据包括73种语言,每种语言的平均数据时间不到3000小时。尽管监督数据有限,但该模型在73种语言中的平均单词错误率(WER;越低越好),这在我们以前从未实现过里程碑。对于en-US,与当前内部最先进的模型相比,USM的WER相对较低6%。最后,我们与最近发布的大型模型Whisper(large-v2)进行比较,该模型经过超过40万小时的标记数据训练。为了进行比较,我们只使用Whisper可以用低于40%的WER成功解码的18种语言。与这18种语言的Whisper相比,我们的模型平均WER相对较低32.7%。
推广到下游ASR任务
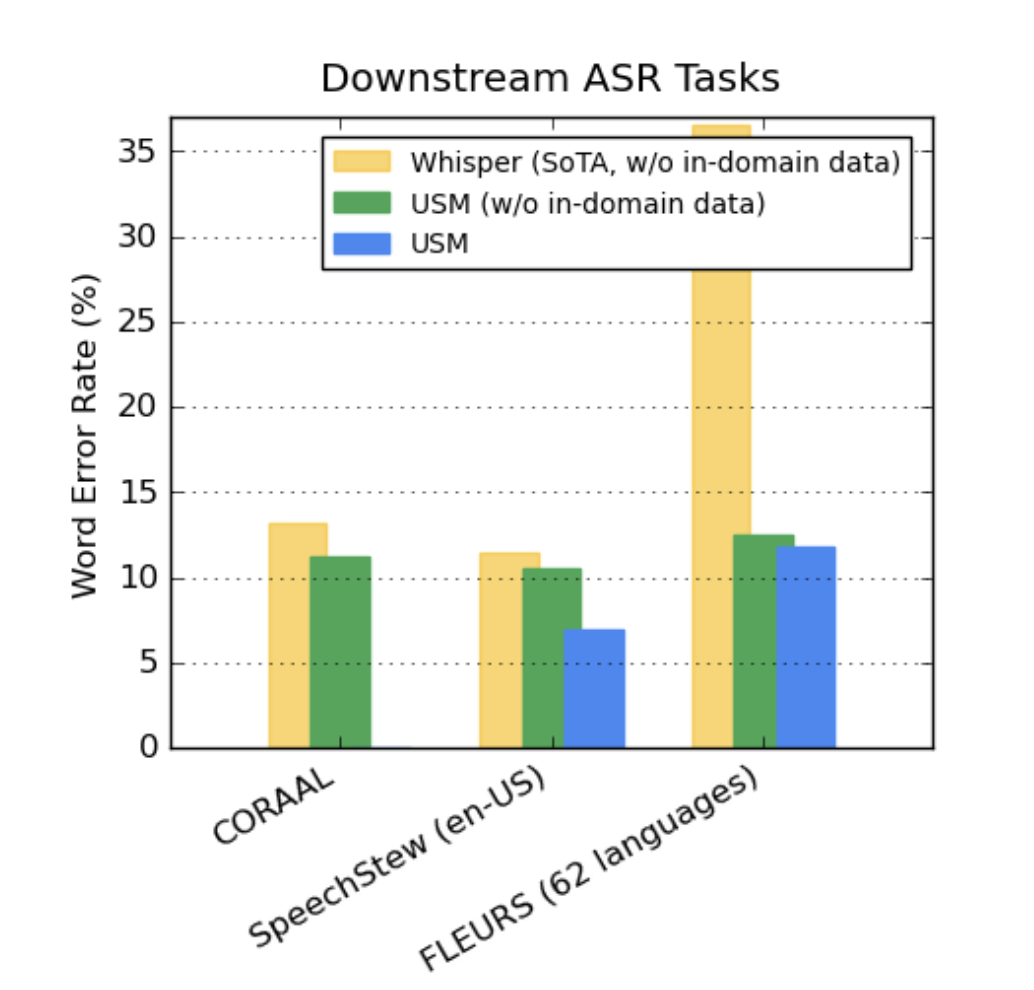
在公开的数据集上,与Whisper相比,我们的模型在CORAAL(非裔美国人的方言英语)、SpeechStew(英语)和FLEURS(102种语言)上显示出较低的误码率。我们的模型在有和没有域内数据训练的情况下都取得了较低的误码率。对FLEURS的比较报告了与Whisper模型支持的语言重合的语言子集(62种)。对于FLEURS,没有域内数据的USM的误码率比Whisper低65.8%,有域内数据的误码率相对低67.8%。
高级自动语音翻译(AST)
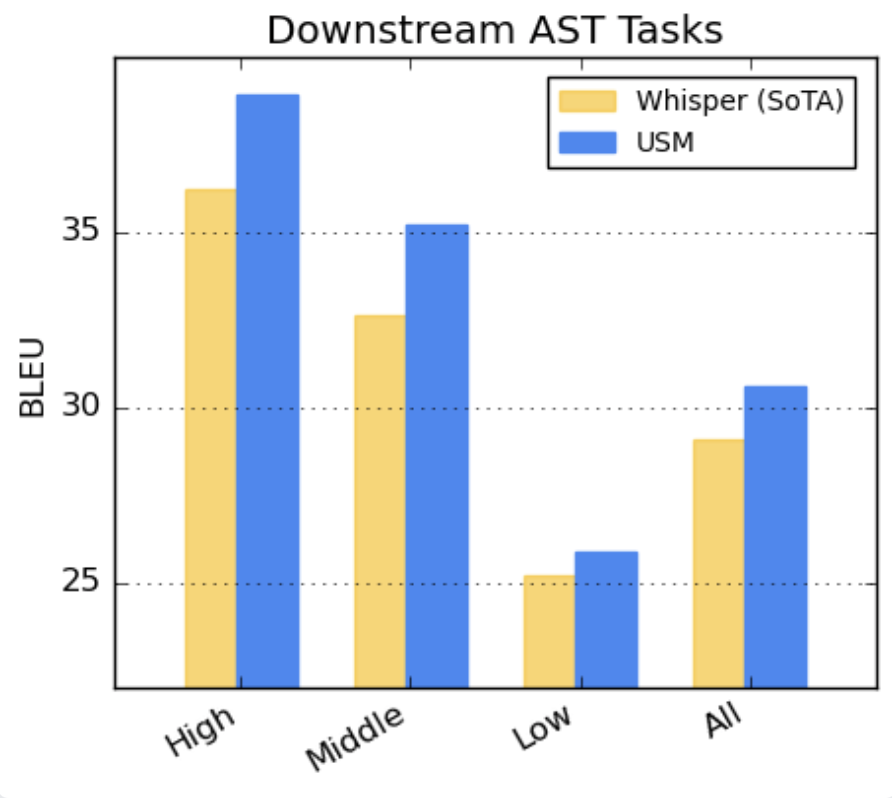
对于语音翻译,我们在CoVoST数据集上微调USM。我们根据资源可用性将语言分为高、中、低,并计算每个部分的BLEU分数。如图所示,USM在所有细分市场的表现都优于Whisper。越高对BLEU更好。
论文地址:https://arxiv.org/abs/2303.01037
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
API入口:点击这里
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢