
近年来大规模视觉 Transformer 的蓬勃发展推动了计算机视觉领域的性能边界。视觉 Transformer 模型通过扩大模型参数量和训练数据从而击败了卷积神经网络。来自上海人工智能实验室、清华、南大、商汤和港中文的研究人员总结了卷积神经网络和视觉 Transformer 之间的差距。从算子层面看,传统的 CNNs 算子缺乏长距离依赖和自适应空间聚合能力;从结构层面看,传统 CNNs 结构缺乏先进组件。
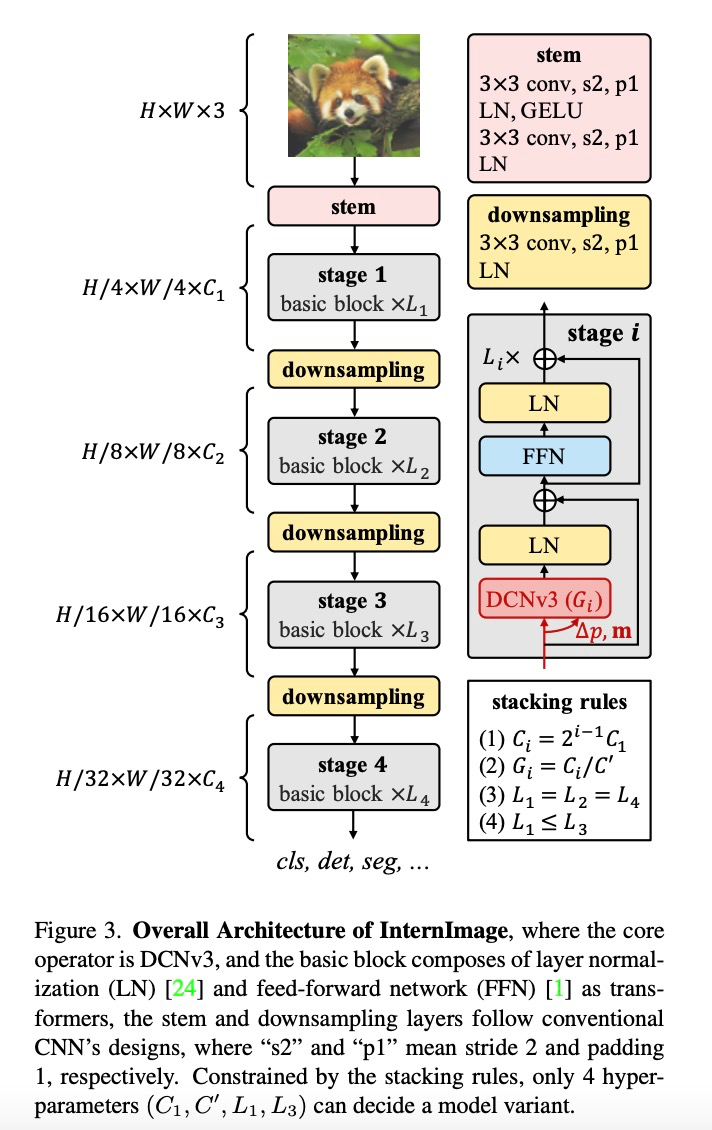
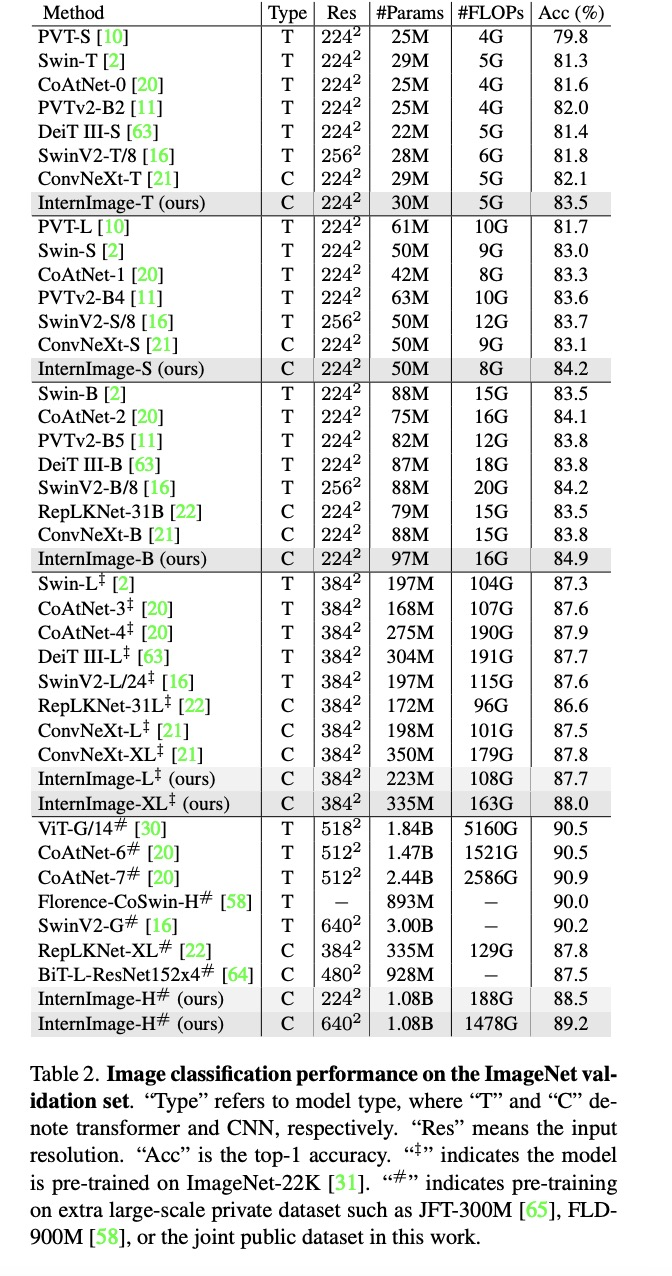
针对上述技术问题,来自浦江实验室、清华等机构的研究人员创新地提出了一个基于卷积神经网络的大规模模型,称为 InternImage,它将稀疏动态卷积作为核心算子,通过输入相关的信息为条件实现自适应空间聚合。InternImage 通过减少传统 CNN 的严格归纳偏置实现了从海量数据中学习到更强大、更稳健的大规模参数模式。其有效性在包括图像分类、目标检测和语义分割等视觉任务上得到了验证。并在 ImageNet、COCO 和 ADE20K 在内的挑战性基准数据集中取得了具有竞争力的效果,在同参数量水平的情况下,超过了视觉 Transformer 结构,为图像大模型提供了新的方向。
论文标题:InternImage: Exploring Large-Scale Vision Foundation Models with
Deformable Convolutions
论文链接:https://arxiv.org/abs/2211.05778
开源代码:https://github.com/OpenGVLab/InternImage
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢