
本文源自本周二的一则新闻,该新闻报道前 OpenAI 联合创始人&主席的 Elon Musk 正在接洽曾在 DeepMind & OpenAI 任职的工程师 Igor Baushkin,从而组建一个新的 AI 实验室以及 ChatGPT 的替代品,可能的名称为 Based AI 以及 TruthGPT。
本篇将主要围绕这起事件分 2 节进行展开,第 3 节是一个古早的创业故事:
- OpenAI 的初衷与 Musk 的执念
- Igor Bauschkin 会是下个“AK”么?
- 微软弃婴,20 年前的“ChatGPT
01 OpenAI 的初衷与 Musk 的执念
根据外媒报道,Elon Musk 正与 AI 研究人员接洽,希望组建一个新的 AI 研究实验室以开发 ChatGPT 的替代品,其中就包括上周刚离开 Alphabet 旗下 DeepMind 部门的工程师 —— Igor Bauschkin👇

Musk 其实还在 Twitter 上发了一个表情包,名为「Based AI」的 Doge 手持大棒打跑了 「Woke AI」以及「Closed AI」,不知道是不是分别暗指 DeepMind 和 OpenAI 这两家 :D,但无论如何还会出现一个第三方,并且是 Musk 主导的,暂且叫「Based AI」。
那么这个「Based AI」想做什么呢?其实又回到了 OpenAI 成立之初,Elon Musk 所畅想的愿景与使命,毕竟 OpenAI 现在的状态可不是原先 Musk 所想的那样,OpenAI 成立之初非营利的性质是为了防止 Google 作恶,现在 OpenAI 变成了另一个硅谷巨头微软变相控制的企业,且以盈利导向,好家伙,非但原先的假想敌没干掉,还一下变成俩,这怎么搞?
回到当年 OpenAI 成立不久,Musk 还同 Greg Brockman、Sam Altman 以及 Ilya Sutskever 一同署名了一篇文章《OpenAI technical goals,OpenAI’s mission is to build safe AI, and ensure AI’s benefits are as widely and evenly distributed as possible 》,也是登在 OpenAI 官网的唯一一篇Musk 以作者身份署名的文章,开头如下:
大概意思是 OpenAI 的技术目标是构建安全的 AI,确保 AI 的利益尽可能的防范和均匀分布,而 Musk 对于目前 AI 的态度就好像对待 Twitter 一样,作为 Twitter 的深度用户,看到平台上的内容和信息集中而不均匀,或者叫中心化,这对于每一个内容消费者来说并不是好事。
对于 Elon Musk 而言,训练一个聊天机器人不是最终目的,“我们需要 TruthGPT”,提高大语言模型的推理能力和真实性才是更重要的,即模型的可用性和可靠性。
打个比方,作为用户,不管是“搜索”还是“聊天”,得到的结果无非是「人类生产+算法分发」或者「人类生产+ AI 加工」,AI 到一定程度实现生成即分发,两者还有区别么?区没区别其实也不重要,但是效果一样,终端用户是否依然受限于一个信息茧房之中?或者更严重?
这里不具体讨论 Musk 主观想法,别人也难猜到,但是客观分析他的言论,确实存在“信息茧房”的问题。
无论是推荐算法分发的时代,还是接下来生成式 AI 时代,用户如果都是被动获取来自机器派送的信息,那么一方面将受限于用户自己在屏幕的每一次点击、滑动、停留以及互动,另一方面也受限于用户当前的认知与语言框架,更可能本身 AI 训练的数据集都是被修饰过的。
除此之外,生成式 AI 可能也会生产出一堆“噪音”,“噪音”可能比人类生产的“噪音”还要高效,那么就更加难以分辨出真正的“信号”,这个过程有点像是你用某搜索引擎搜索,得到的结果都是人家 SEO 精心优化好的。
这一点其实在 Musk 对于教育的看法上有些吻合。Musk 在公开场合曾表示教育的本质是把数据(案例)和算法(方法)下载到大脑里,大部分知识可以在网上免费搜到,那么在网上冲浪本身也带有边刷边学的场景在,如果数据和算法是不安全的,那么也将会影响下一个“Musk”。
所以,结合 TruthGPT 的话题反过来想,不管是 UGC 还是 AIGC,用户只要在网络上获取的是“噪音”而不是“信号”,那么体验总归是不好的,这也是为什么强调 “Truth”。
未来如何,这很难预测,但应对“噪音”这个问题,Musk 本人也曾提过他的思维框架,这可能是一种可行的“降噪”方式 —— “你需要有一个这样的立场,从某种程度上假设自己是错的,你的目标打从一开始就不是分出对错,而是随着时间的推移减少错误”,这样就避免了过早下结论导致出错的可能性,并且保持稳扎稳打的心态。
02 Igor Bauschkin 会是下个“AK”么
细聊下Musk 想招纳的这个帅哥 Igor Bauschkin 履历与经历,也许他会是下一个“Andrej Karpathy”,OpenAI 的创始团队成员,ex 特斯拉 AI 总监👇

Bauschkin 是物理学+计算机背景 ,在 DeepMind 和 OpenAI 都工作过,也接手过 Gopher 和 GPT 两大模型。2015 年,Bauschkin 在德国多特蒙德工业大学获得物理学硕士学位,在读书期间还报名了 CERN(欧洲核子研究中心)暑期学生计划,该计划也为 Igor Bauschkin 这样理工科背景的学生提供机器学习相关课程的机会。
在正式步入 AI 领域前,Bauschkin 毕业后在 CERN 进行大型强子对撞机研究工作,在那里通过 LHCb 实验分析粒子衰变,期间在许多物理学相关期刊发表了多篇论文。
Bauschkin 在机器学习领域的研究最早可以追溯至 2018 年在 ICML 国际会议上与人合著发表的《Synthesizing programs for images using reinforced adversarial learning》,主要讲述在无监督情况下,通过分布式强化学习来进行模型训练,从而合成图像。
2017 年,Bauschkin 加入当时已经被 Google 收购的 DeepMind 担任 Research Engineer,主要负责自然语言处理和强化学习方面的研究。
2019 年 1 月,DeepMind 在官方博客更新了一篇《Alphastar: Mastering the real-time strategy game starcraft ii 》的文章,AlphaStar 是 DeepMind 开发的第一个击败顶级职业玩家的人工智能,当时AI 以 5:0 的比分击败了职业选手,Bauschkin 是 AlphaStar Team 的主要成员之一,文章讲述了 AlphaStar 是如何通过深度神经网络训练的。同年 11 月,相关研究《Grandmaster level in StarCraft II using multi-agent reinforcement learning》登上《Nature》。
2020 年 11 月,Bauschkin 离职,加入已经成立满 5 年的 OpenAI 担任 Technical Staff,期间参与了 GPT-
3、DALL-E 和 CLIP 项目的开发
Bauschkin 还是另一篇 DeepMind 在 2021 年发表的论文《Scaling Language Models: Methods, Analysis & Insights from Training Gopher》合著者。
这篇论文讲述了基于 Google Transformer 的各种语言模型在规模与性能上的比对,从数千万参数的模型再到 2800 亿参数量量的 Gopher 模型,研究人员发现规模收益主要体现在阅读理解和内容审查方面,而在逻辑和数学推理的收益较小,比如 Gopher 模型在以下几个垂直知识领域甚至超过了当时的 GPT-3 和人类专家。
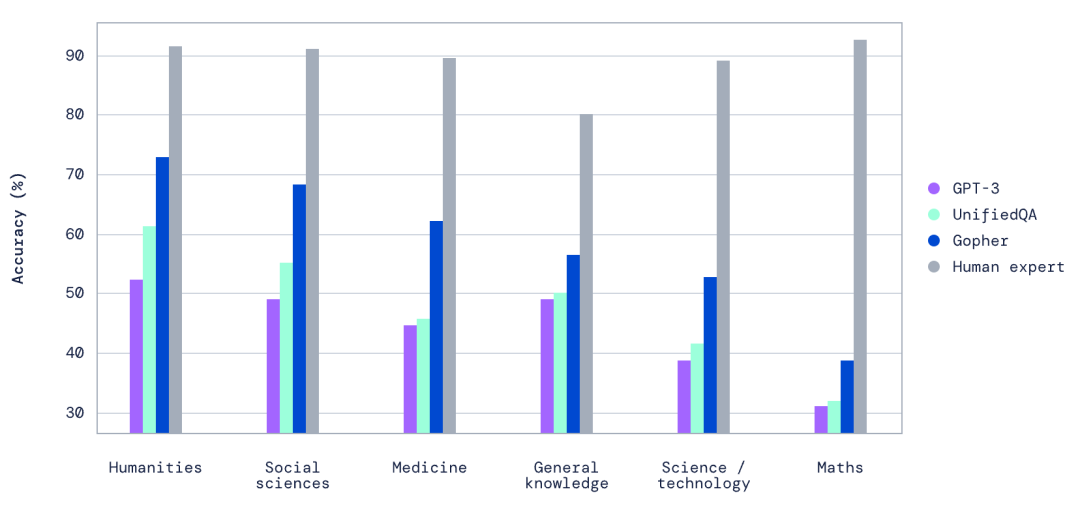
Gopher 模型和 GPT-3 模型两者都基于 Google 的 Transformer 神经网络架构开发,也都是预训练模型,在参数规模上前者达 2800 亿,后者为 1750 亿,但由于在训练数据集以及训练方式的差异,两者的表现也不同,就好比 28 岁的 A 和 17 岁的 B 一起考试,你很难说 A 会因为年龄大更聪明,又或者 B 更年轻而跑更快。
Gopher 模型也能实现 ChatGPT 那样的聊天,DeepMind 在文章里还公开过一些 QA 案例。

2022 年 4 月,Bauschkin 从 OpenAI 离开,再次回归 DeepMind,担任 Senior Staff Research Engineer,在短短停留 11 个月后宣布离开。
根据 Igor Bauschkin 在接受媒体采访时表示,目前还没有正式签署 Elon Musk 的项目,但希望和 Musk 一起在大语言模型领域进行研究,论实力 Musk 无论在想象力、执行力、财力还是组织力上都是满级的存在,作为 OpenAI 的早期发起人他具备另起炉灶的要素,Musk 的 BasedAI 以及 Truth GPT 还是值得期待的。
03 微软弃婴,20 年前的“ChatGPT”
聊完今时今日 Musk 与他的 AI 大计,就到了本期的最后一节,主要讲述微软与 20 年前火极一时,不亚于今天 ChatGPT 的一款产品,它们很相似,但可能走着不同的命运。
这款产品叫做 SmarterChild,可能是最早的互联网模因(“梗”)之一,当时是一款主要内嵌在即时通讯软件内的 ToC 聊天机器人,当然它也有 ToB 的形态,一个类订阅号的 Bot 来提供营销服务;它所呈现的个性并不基于技术,而是基于 Bot 背后编辑团队的创意,最终它被微软收购,被微软应用在旗下的产品当中。
2000 年,Tim Kay 和姐夫Robert Hoffer,外加一个纽约的广告狂人 Peter Levitan 创立了 ActiveBuddy,Inc 这家公司。
2001年6月,ActiveBuddy在 AIM(AOL Instant Messenger)上推出名为 SmarterChild 的聊天机器人,就像是在电脑端 QQ 好友列表里添加 ChatGPT;同月,大洋彼岸的 OICQ 也正式更名为 QQ 并推出了经典的企鹅 logo。
根据联合创始人 Hoffer 描述,SmarterChild 自 2001 年 6 月推出后,是有史以来第一个互联网模因,当时每天的新增用户按「万」为计量单位,甚至超过了 Twitter 的增速。PS:大概是2006 年前后的数据,因为 Twitter 最早版本是 2006 年 3月推出的。
2003 年纽约时报的一篇文章显示,每天有 25 万人与 SmarterChild 聊天,按照今天的话说是 DAU 为 25 万,在其生命周期内总共在 AOL、MSN 以及 Yahoo 平台三大平台的即时通讯软件上吸引了超过 3000 万的用户,巅峰时期占所有 IM 通讯软件流量的 5%,每天接受数亿条消息。
当然,故事的结局是 SmarterChild 没有活到成年,不然现在也没有 ChatGPT 什么事了,原因自然和微软脱不了干系。
最初 SmarterChild 的产品 Demo 来源于联合创始人 Kay 在车库里的尝试,通过代码连接一个名为“ActiveBuddy”的好友代理来查股票代码,之后又支持了 AOL聊天模块上的文字冒险游戏“Colossal Cave Adventure”、MIT 的问答系统“Boris Katz Start”以及更广泛的数据库,包括访问新闻、天气、股票、电影、体育等数据和各类如计算器和翻译的工具。PS:害,这不就是今天的 Microsoft Bing 么?原来早就有了。
投资了 Siri、Uber、Epic、Chime 的投资人——Menlo Venture 道合伙人 Shawn Carolan 回忆道:“首次接触 Siri 时,当时的 SmarterChild 已经拥有 1000 万用户,每天收到 10 亿条消息”。实际上,Siri 成立于 2007 年,2008 年初拿到 Carolan 的投资,当时的 SmarterChild 已经处于产品生命周期尾声了。
ActiveBuddy,Inc 成立之初曾筹集到数千万美元,商业化策略主要是为英国摇滚乐队 Radiohead、电影《王牌大贱谍》、《体育新闻》 、英特尔以及 Keebler 等 B 端客户提供 IM 营销服务。
举个例子,Radiohead 当时在其第 5 张专辑《Amnesiac》中推出名为 GoolyMinotaur(Gooly) 的角色,Gooly 也是 ActiveBuddy 推出的定制化音乐机器人。
用户可以通过 AOL 的即时通讯软件 AIM 添加 SmarterChild 为好友,并从聊天框里获得乐队巡演、简介、音乐下载以及工作室的独家内容,就理解成微信里面的企业订阅号吧....根据统计当时这个“订阅号”曾向 100 万用户发送大约 6000 万条消息推送。

SmarterChild 早期产品成功的原因主要归纳为 4 点:
- 产品形态:SmarterChild 本质是一款聊天机器人,通过文本与用户交互,20多年前 128kbps 的网速下载 1 秒的音频需要 16000 字节,而文本仅 90 字节,在有限的网速下文本作为媒介具备明显传输优势;
- 兼容性:SmarterChild 不是客户端产品,不需要下载和安装,用户通过当时的 IM 平台即可添加 SmarterChild 到好友列表里,如同今天活在 Discord 社区里的 Midjourney;
- 社交属性:按照当时的网络环境,上网聊天的是一群感时髦的孩子,他们通常在放学后拨号上网,并在睡前迎来又一波流量高峰,对 Ta 们来说通过 SmarterChild 获取信息不重要,社交、好奇与打发时间才是更重要的;
- 个性:对,你没看错,这是 SmarterChild 的第一位投资人 —— Hoffer 的朋友,当时在 Pixar 担任 2D 动画师的 Doug Frankel 投资了 ActiveBuddy 约 400 万美元,Frankel 当时表示 SmarterChild 有点点“坏”,它会 PUA 用户,这不是因为当时的技术有多先进,更谈不上 AI,而是聊天机器人背后的编辑们是一群充满创意和恶搞的群体,用户喜欢的这种“坏”,就好比《狂飙》里的强哥。
Hoffer 曾表示“当拥有一个具有个性的角色时,可能面临的不是技术问题,而是编辑问题,作为角色的塑造方,你必须愿意激怒 50% 的用户,这也是大公司做不好和不敢做的原因”。PS:今天 Google 复现了这个 Bug~
Kay 这么形容当时互联网泡沫前后发生的变化 —— 互联网泡沫破灭前,人们在说“哦,你有一个商业模式并不重要,吸引眼球才是最重要的” ,而当互联网泡沫破灭后,人们在说“你必须赚钱。”
2000 年的互联网泡沫破灭后,当时广告行业处于下行周期,投资机构也变得谨慎,而 SmarterChild 业务发展和商业化也正需要更多的工程师、脚本编辑团队和业务开发人员。
ActiveBuddy 终于获得了一家名为 Wit Soundview 的风投机构支持,但这家机构缺乏远见,以激进的方式推动管理层将公司商业化,最终导致了核心团队的流失,包括那些有趣的编辑们,公司的业务也面临转型,聚焦 B 端服务,开始为 Comcast 和 Cox 等大型传播集团提供定制服务,2003 年公司更名为 Conversagent,2006 年再次更名为 Colloquis,最终在 2006 年 10 月被微软以 4600 万美元收购。
微软收购 Colloquis 的本意是将这家公司的对话技术推向其现有的客户,Colloquis 的相关产品包括后来的 Windows Live Service Agents,可以在 Windows Live Messenger 上提供服务机器人,以及 Colloquis Answer Suite。
同样,微软这边也是以商业化为目的,2007 年微软发布了圣诞老人机器人,由于这款产品向未成年发布了攻击性的暗示,最终在 2009 年被微软喊“Cut”。
至于为什么?原因是那时聊天机器人的底层能力远比不上今时今日大模型所表现出的“类人”能力,更需要编辑们生产的“数据”和内容审核,但微软恰恰不是一家内容公司,激进的商业化反过来加剧了管理的混乱,早期成员流失。
回顾 SmarterChild 这款产品的一生,将它比作 20 多年前手工版的“ChatGPT”并不为过,两者有许多相似的地方,相同的地方不列举了,而不同的地方,例如技术与商业环境今非昔比、今天的微软也比 2007 年那会儿支棱多了、大语言模型的学习效率与 GPT 模型肉眼可见的演化,以及 OpenAI LP 与微软之间复杂的条款约定,而并非 100% 所有。
最后,与其推测 OpenAI 版的“SmarterChild”未来会如何?倒不如顺着 Musk 的逆向思维,看看 ChatGPT 是否已经避开了当年 SmarterChild 的一些覆辙?另外还具备了哪些新的竞争优势?
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢