
此项技术应用在信息化生活的方方面面,如百度 推出的图片搜索功能,为跨模态信息检索提供便利;小红书 中应用此技术优化封面图像,使得笔记的吸引力大大增加;大众点评中保证图文的高相关性,帮助消费者遴选高优质信息等等。这些无不为我们的生活带来了诸多便利,因此,本文旨在研究图文匹配中自适应的特征聚合、训练目标方法,从而进一步提升实际应用效果。
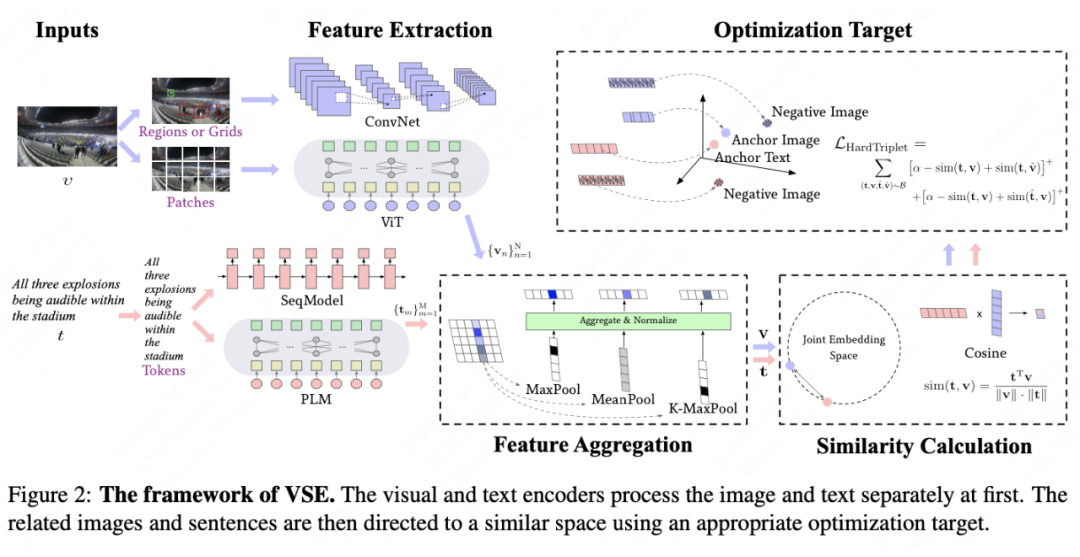
特征抽取:图像和文本特征首先由各自独立的视觉和文本编码器提取;
其中,特征抽取和相似性计算的方式较为固定。前者强依赖于计算机视觉(Computer Vision, CV)和自然语言处理(Natural Language Processing, NLP)领域的进步与发展,而后者则通常采用余弦距离(Cosine Similarity)度量语义相似程度。因此,为了提升 VSE 模型的效果,本文将改进的重点放在了提升特征映射以及优化目标上,为方便后续研究者使用,本文代码已公开。

论文链接:https://arxiv.org/abs/2210.02206
代码链接:https://github.com/96-Zachary/vse_2ad
模型
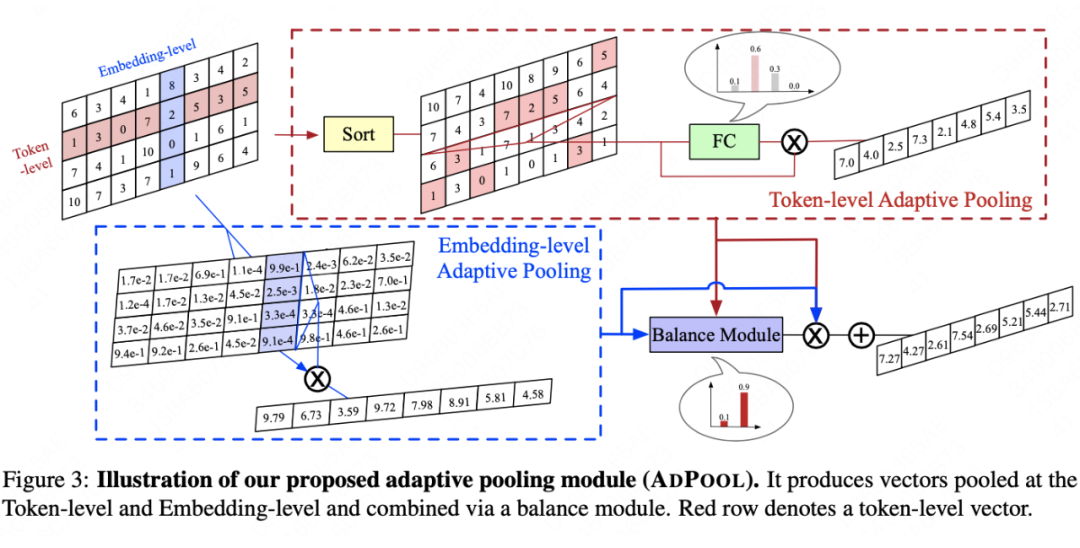
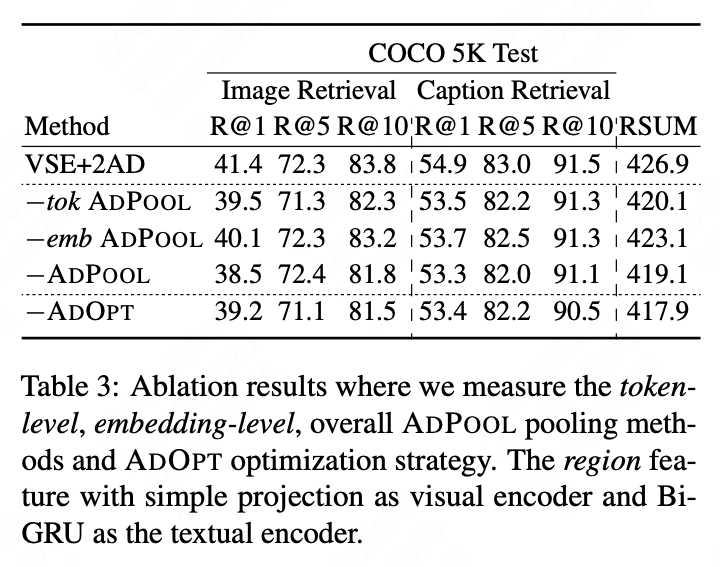
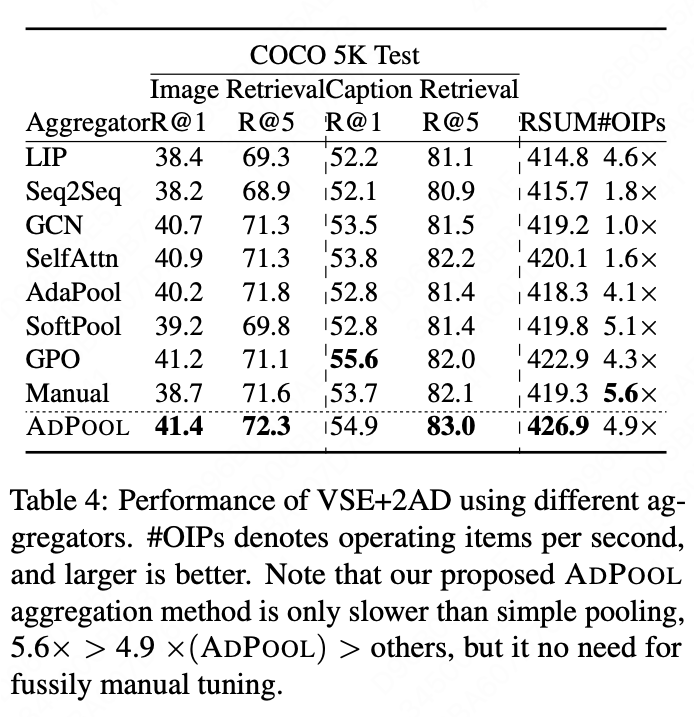
自适应特征聚合,顾名思义是将特征矩阵抽象成特征向量。常用的方法是池化操作(Pooling),然而一般的池化方法(Mean/Max/K-Max)无法同时适配视觉特征和文本特征,而找到最优的特征组合往往需要大量的时间,且在不同数据分布下这种组合往往是不同的。基于此问题,本文提出了一种自适应的 Pooling 策略,从 token-level 和 Embedding-level 两个维度分别计算,并最终融合在一起。
Token-level Pooling:首先,无论是 Mean—Pooling、Max—Pooling 还是 KMax—Pooling,都可以认为是一种先将值按照特征维度进行排序,随后分配静态的权重来抽取特征向量。以 Max-Pooling 为例,他的权重中最大值对应了 1,其余均为 0。
本文也延续此“排序-权重分配”的策略进行自适应特征聚合,其中将权重的确定过程交给模型自动化学习,使用一层全连接网络。实验发现,仅考虑 Token-level Pooling 得到的权重与 Mean—Pooling/KMax—Pooling 分布很相似,因此,从更多元化和普适的角度出发需要考虑更多维的设计;
Embedding-Level Pooling:按照输入粒度进行 Softmax 的 weight-sum,使得特征矩阵中更加显著的特征值被赋予更多的权重,此过程不涉及参数学习过程;
自适应优化目标
自适应优化目标,顾名思义是为模型在不同的训练阶段找到最合适的优化目标。首先我们需要一套评判模型阶段性能力的标准,其次我们需要根据不同的阶段为模型设计不同的优化目标。
表征学习中常常使用 Aligment 和 Uniformity 来评判模型能力,其中,Aligment 用来判断相似样本间的聚合程度,Uniformity 则用来反映不同样本映射到表征空间的分散程度(理想情况下不同样本表征应尽量分散,从而体现其差异化)。通过此两标准,我们可以设计一个范围为 [0,1] 的比率值,其中,值为 1 时模型效果最差,越接近 0 表示模型效果越好。
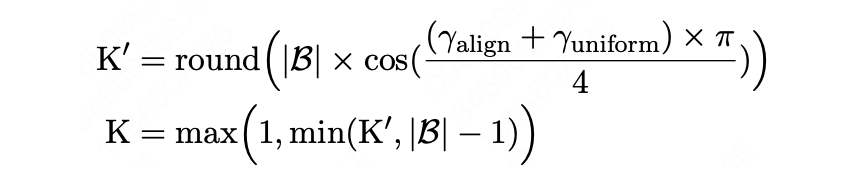
VSE 模型常构造三元训练目标,原点(anchor)、与之对应的正样本(positive)以及与之对应的负样本(negative)。基于度量模型得到的比率值,我们为模型不同训练阶段选择不同数量的负样本,当模型训练伊始、表现较差时,为模型选择更多的负样本可以帮助模型拟合,快速提升区分样本差异的能力;当模型训练逐渐熟练、表现较好时,为模型选择最难的一个或几个负样本(Hard Negative Samples)则能帮助模型区分细致化差异,提升模型能力。
实验结果
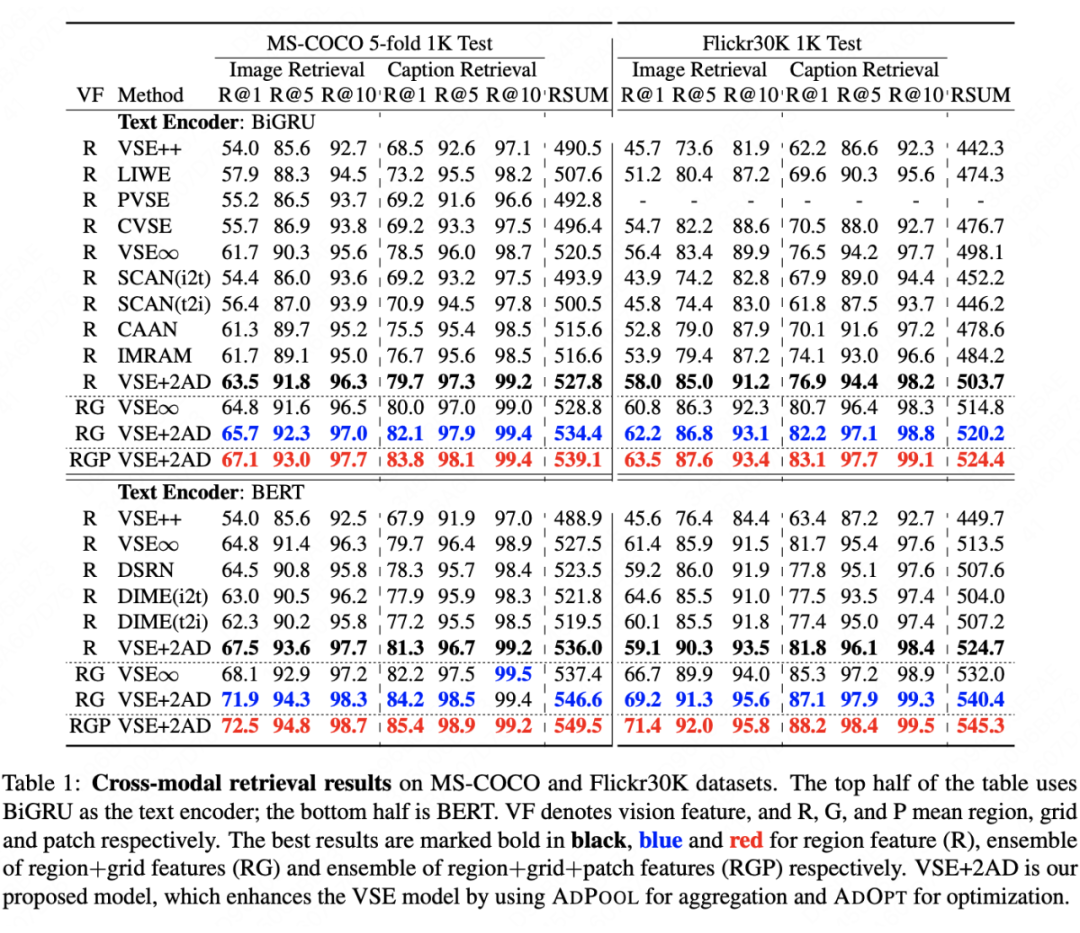
本文在两个公开数据集上进行实验来验证模型的准确性和速度,分别是 MS-COCO 和 Flickr30K(最常用的图文检索数据集)。
实验中,我们对不同的图文编码器进行组合以验证本文所提方法的鲁棒性,前文有提到过 VSE 模型的效果依赖于 CV 和 NLP 领域的发展。文本/图像编码器组合分别是:BiGRU/Faster-RCNN、BiGRU/Vit、BERT/Faster-RCNN、BERT/Vit。评测指标选择 Recall@K,其中 K=1,5,10 以及对以上指标的加和形式的 RSUM。

总结
本文在当前图文表征的 VSE 框架下,改进并提出了自适应特征聚合方法和自适应优化目标。与之前的方法不同,本文所提的两个自适应模块可以即插即用应用到其他相似框架下,且均由模型在训练过程中自动化进行,无需冗杂的调参便可提升模型表现。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢