
谷歌上线了一个炸弹级模型——足足有5620亿参数!PaLM-E 是一个具身语言模型,结合了现实世界的传感器模态进行接地(grounded)语言推理,并在各种任务和具身体中表现出积极的迁移。
D Driess, F Xia, M S. M. Sajjadi
[Robotics at Google & Google Research]
PaLM-E: 具身多模态语言模型
要点:
-
PaLM-E 是一个具身语言模型,将现实世界的传感器模态纳入语言模型,以建立词和感知之间的联系; -
PaLM-E 在各种具身推理任务上取得了最先进的性能,包括连续的机器人操纵规划、视觉问答和描述,以及一般的视觉语言任务; -
PaLM-E 中使用的新的架构理念,如神经场景表征和实体标记的多模态标记,在摄取多模态信息方面特别有效; -
扩大语言模型规模带来了灾难性遗忘的明显减少,同时成为一个具身的主体,使 PaLM-E 能展示多模态思维链推理和对多个图像进行推理的能力等新兴能力。

PaLM-E 将真实世界的传感器信号与文本输入相结合,建立语言和感知的链接。规模最大的模型“PaLM-E-562B”具有562B个参数,将540B的PaLM和22B的ViT集成在一起,这是目前报道的最大的视觉-语言模型。模型输入包括视觉、连续状态估计值和文本输入。作者在多个任务(包括顺序机器人操作规划、视觉问答和字幕生成)中进行了端到端的训练,并通过评估表明,其模型能够有效地解决各种推理任务,并且在不同的观察模态和多个实体上表现出了积极的转移。该模型在进行机器人任务训练的同时,还具有先进的视觉-语言任务表现,并随着规模的增大保持了通用的语言能力。
论文:https://arxiv.org/abs/2303.03378
推特:https://twitter.com/DannyDriess/status/1632904675124035585
PaLM-E 是什么
PaLM-E是一个单一通用的多模态语言模型,可用于感知推理任务、视觉语言任务和语言任务。它将来自视觉语言领域的知识转化为体验推理的知识,从具有复杂动态和物理约束的环境中进行机器人规划,到回答关于可观察世界的问题,都可轻松搞定!
它支持多模态输入,来自任意模态(例如图像、三维表示或状态,绿色和蓝色)的输入插入文本token(橙色)旁边作为LLM的输入,进行端到端的训练。
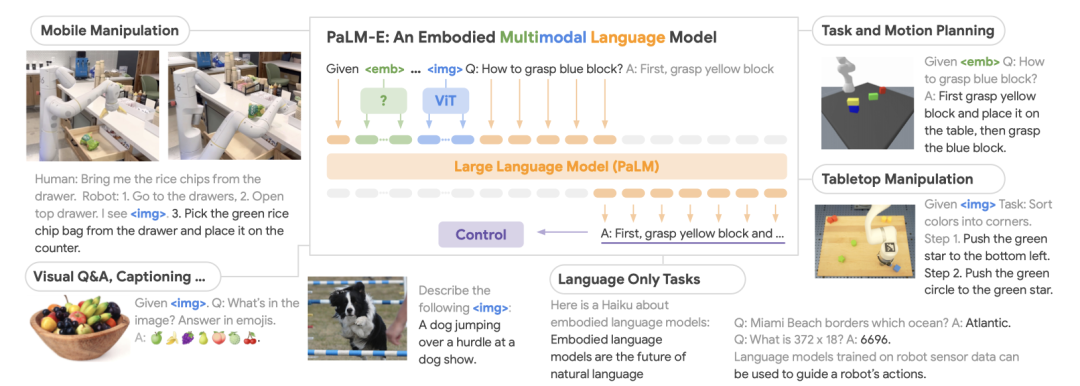
PaLM-E的主要架构思想:将连续的、可感知的观察数据注入预先训练的语言模型的嵌入空间中,以使其能够理解这些连续数据。这是通过将连续观测数据编码为与语言嵌入空间中的语言标记具有相同维度的向量序列来实现的。这种连续信息以类似于语言标记的方式注入语言模型中。
PaLM-E是一个仅具有解码器的语言模型,可以自动地根据前缀或提示生成文本完成结果。该模型使用预先训练的语言模型PaLM,并将其赋予感知推理的能力。

模型在真实世界里的表现如何
文章视频原地址:https://mp.weixin.qq.com/s/yZt3sEQPzVjnIvqXsNOnPA
我们展示了几个示例视频,展示了如何使用PaLM-E在两个不同的真实实体上规划和执行长期任务。请注意,所有这些结果都是使用同一模型在所有数据上训练得出的。在第一个视频中,我们执行了一个长期指令“从抽屉里拿来米饼”,其中包括多个规划步骤,以及整合了机器人摄像头的视觉反馈。最后,在同一机器人上展示另一个示例,指令是“给我带一个绿色的星星”。绿色的星星是这个机器人没有直接接触过的物品。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢