
Hyena Hierarchy: Towards Larger Convolutional Language Models
论文地址:https://arxiv.org/abs/2302.10866
最近深度学习的进展在很大程度上依赖于Transformers 的使用,因为它们具有大规模学习的能力。然而,Transformers的核心构件,注意力运算器,在序列长度上表现出二次成本,限制了可获得的上下文数量。现有的基于低等级和稀疏近似的亚二次方方法需要与密集的注意力层相结合,以匹配Transformers ,这表明能力上存在差距。
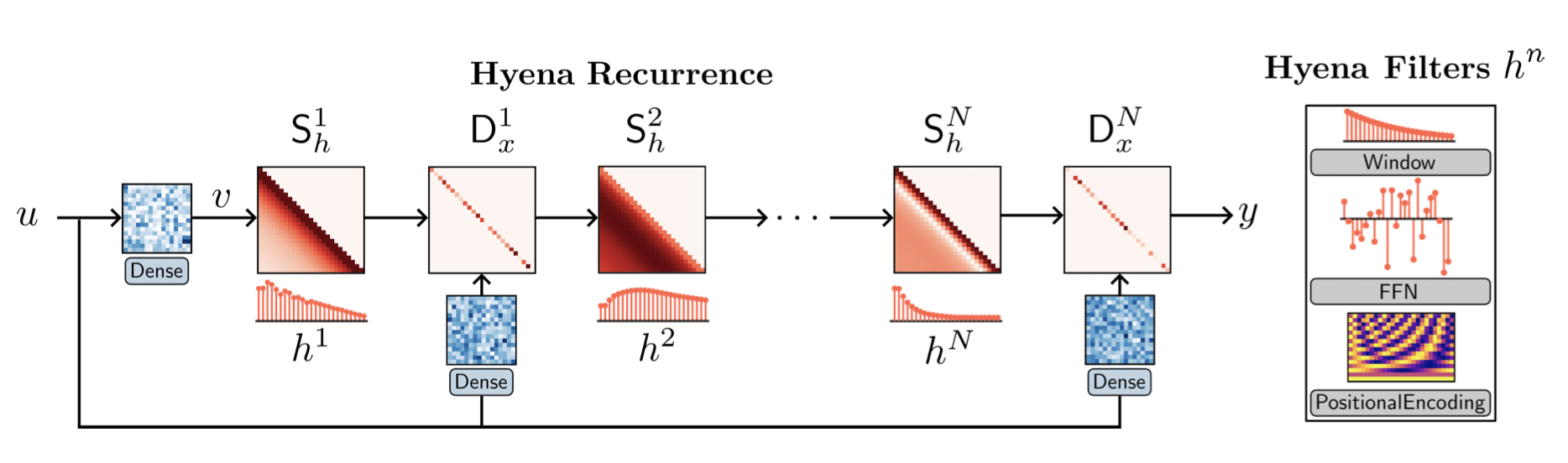
在这项工作中,我们提出了Hyena,这是一个亚二次方的注意力的替代品,通过交织隐式参数化的长卷积和数据控制的门控来构建。在对几千到几十万个符号序列的回忆和推理任务中,Hyena比依靠状态空间和其他隐式和显式方法的运算器提高了50分以上的准确性,与基于注意力的模型相匹配。
我们为标准数据集(WikiText103和The Pile)中的语言建模设定了一个新的无密集注意力架构的最先进技术,在序列长度为2K时,训练计算量减少20%,达到了Transformer的质量。在序列长度为8K时,Hyena算子的速度是高度优化的注意力的两倍,而在序列长度为64K时,速度是100倍。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢