

大型语言模型可以超越语义先验,学习上下文中呈现的输入-标签映射,这是模型规模的一种涌现能力。指令微调提高了输入-标签映射学习的能力,加强了语义先验。
Larger language models do in-context learning differently
J Wei, J Wei, Y Tay, D Tran, A Webson, Y Lu, X Chen, H Liu, D Huang, D Zhou, T Ma
[Google Research & Stanford University]
较大语言模型上下文学习的方式有所不同
要点:
-
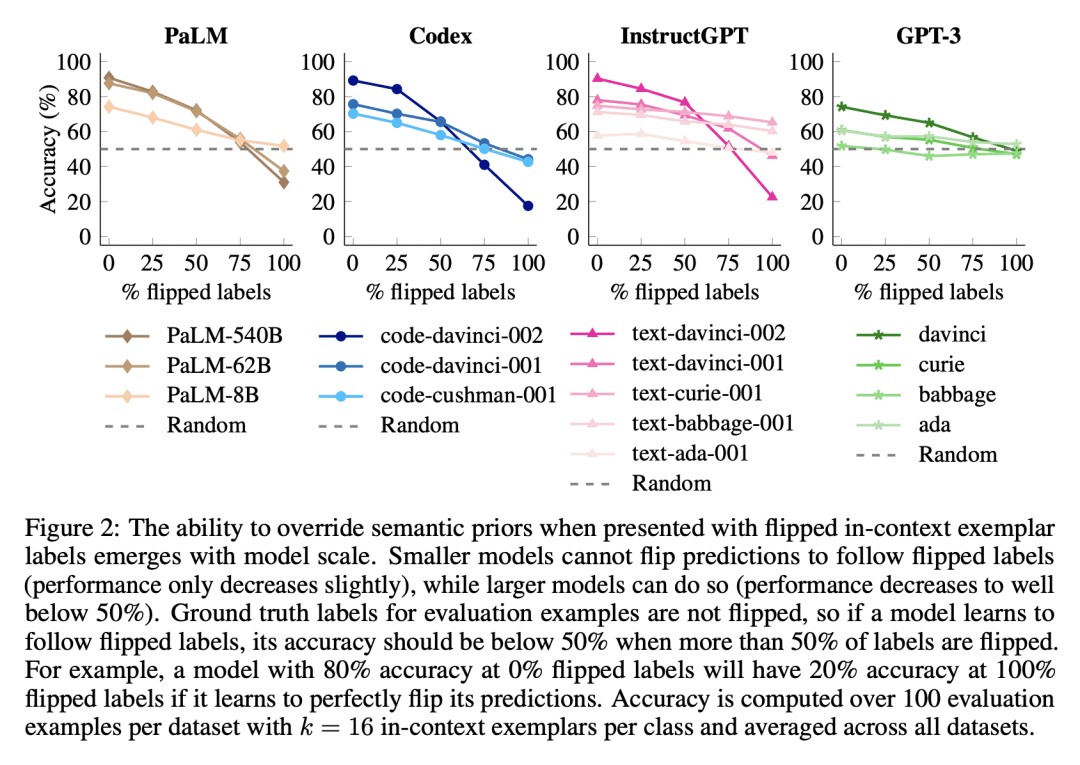
大型语言模型可以超越语义先验,学习在上下文中呈现的输入-标签映射,这是模型规模的一种涌现能力;
-
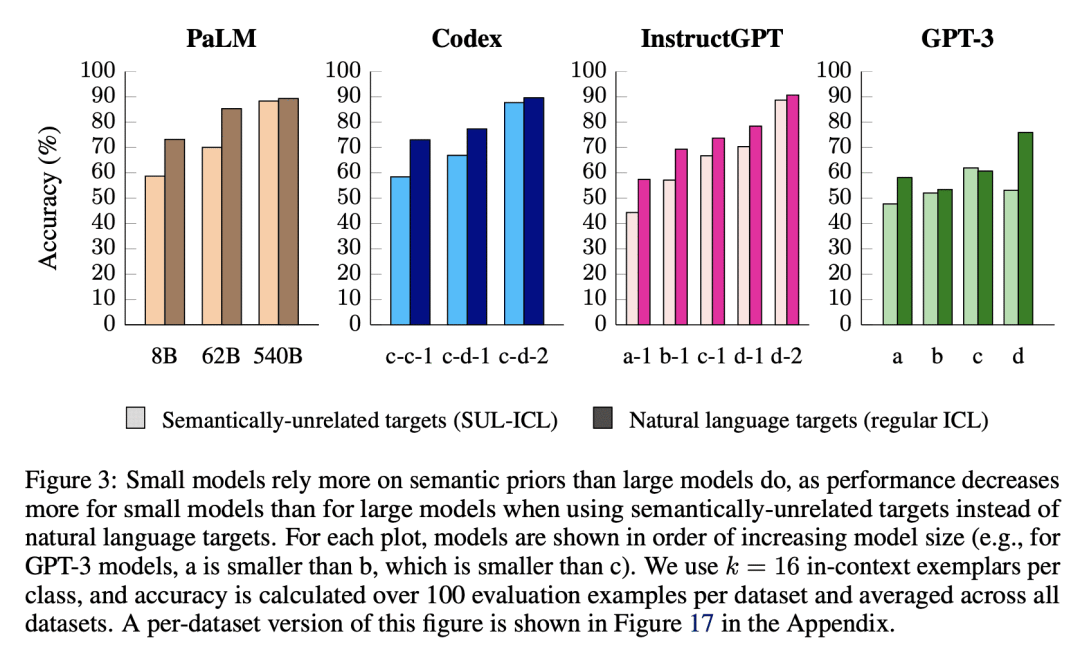
指令微调提高了输入-标签映射学习的能力,加强了语义先验;
-
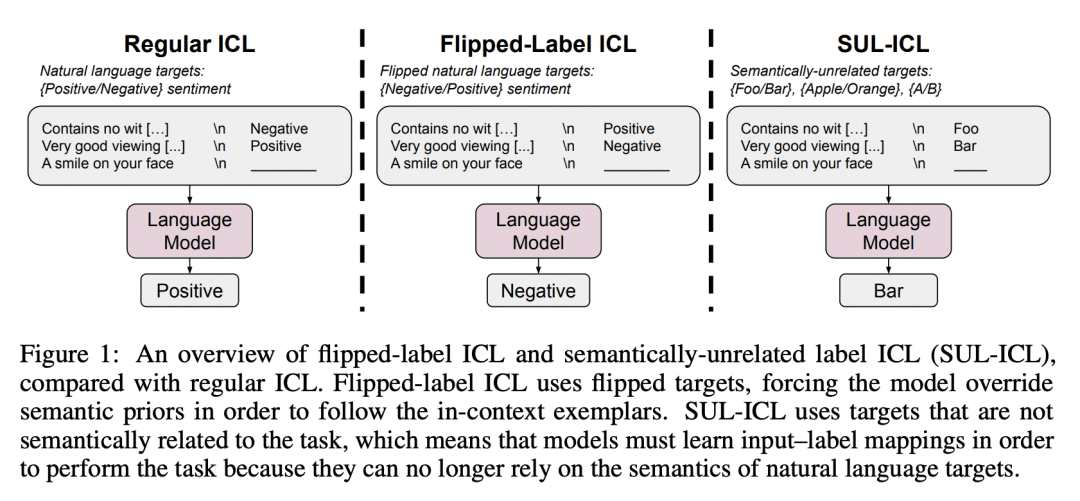
语义非相关标签上下文学习(SUL-ICL)从标签中去除语义,在 SUL-ICL 设置中成功进行 ICL 是模型规模的另一种涌现能力;
-
成功进行高维线性分类是随着模型规模扩大而涌现的,这表明更大的语言模型具有将输入映射到多类型标签的涌现能力,这是一种真正的符号推理,在该推理中,输入-标签映射可以为任意的符号学习。
论文:https://arxiv.org/abs/2303.03846

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢