
Introspective Cross-Attention Probing for Lightweight Transfer of Pre-trained Models
Y Dukler, A Achille, H Yang, V Vivek, L Zancato, B Bowman, A Ravichandran, C Fowlkes, A Swaminathan, S Soatto
[AWS AI Labs]
面向预训练模型轻量化迁移的内省交叉注意力研究
要点:
-
InCA 是一种轻量的迁移学习方法,可交叉关注预训练模型的任意激活层; -
InCA 实现了与完全微调相媲美的性能,其成本与只对最后一层进行微调相当,而不需要通过预训练的模型进行反向传播; -
InCA 具有多功能性,允许并行组合以及并行执行多个任务,并在 ImageNet-to-Sketch 多任务基准测试中取得了最先进的性能; -
InCA 能在单个GPU上以常规的批处理规模自适应 ViTG/14 或 ViT-L @ 384 分辨率模型,使用 ∼1% 的参数作为完全微调,并且能够为多个任务进行"一对多"的并行推理。
一句话总结:
InCA 是一种轻量且高效的迁移学习方法,可以达到与完全微调相当的性能,不需要通过预训练模型进行反向传播。
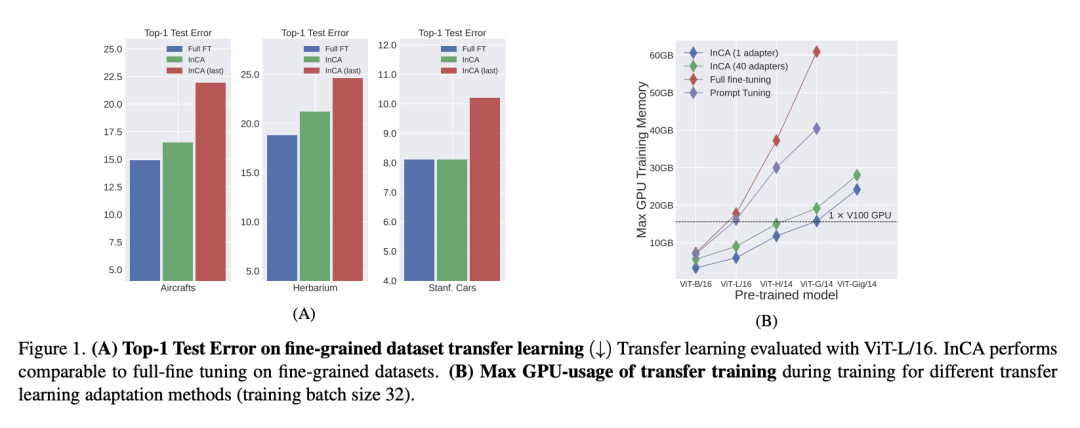
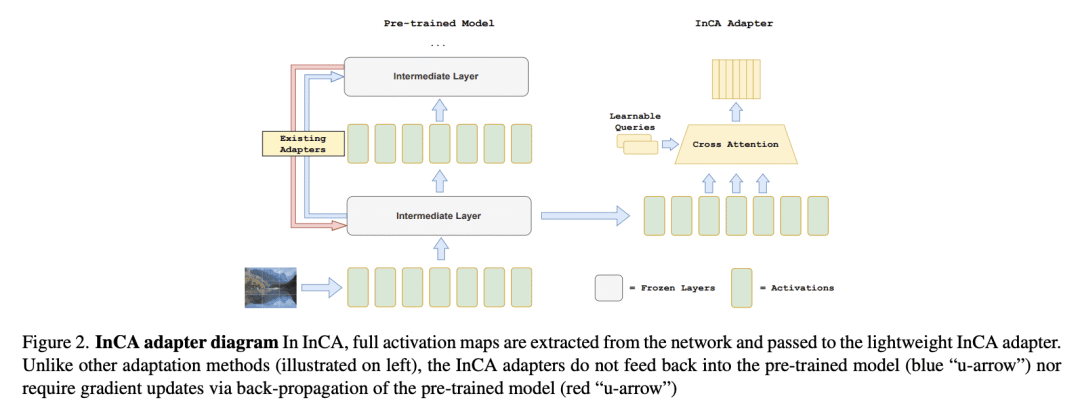
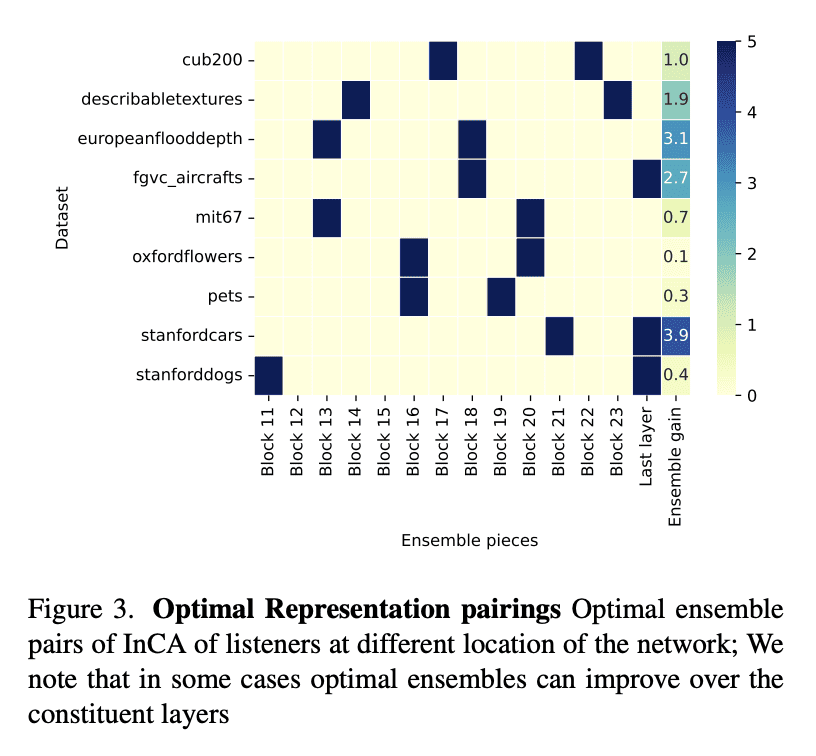
We propose InCA, a lightweight method for transfer learning that cross-attends to any activation layer of a pre-trained model. During training, InCA uses a single forward pass to extract multiple activations, which are passed to external cross-attention adapters, trained anew and combined or selected for downstream tasks. We show that, even when selecting a single top-scoring adapter, InCA achieves performance comparable to full fine-tuning, at a cost comparable to fine-tuning just the last layer. For example, with a cross-attention probe 1.3% the size of a pre-trained ViT-L/16 model, we achieve performance within 0.2% of the full fine-tuning paragon at 51% training cost of the baseline, on average across 11 downstream classification tasks. Unlike other forms of efficient adaptation, InCA does not require backpropagating through the pre-trained model, thus leaving its execution unaltered at both training and inference. The versatility of InCA is best illustrated in fine-grained tasks, which may require accessing information absent in the last layer but accessible in intermediate layer activations. Since the backbone is fixed, InCA allows parallel ensembling as well as parallel execution of multiple tasks. InCA achieves state-of-the-art performance in the ImageNet-to-Sketch multi-task benchmark.
论文链接:https://arxiv.org/abs/2303.04105
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢