
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
C Chi, S Feng, Y Du, Z Xu, E Cousineau, B Burchfiel, S Song
[Columbia University & Toyota Research Institute & MIT]
扩散策略:基于行动扩散的Visuomotor策略学习
要点:
-
扩散策略总是优于现有的最先进的机器人学习方法,其平均改进率为46.9%; -
扩散策略学习行动分布得分函数的梯度,并在推理过程中通过一系列随机的朗文动力学步骤对该梯度场进行优化; -
扩散策略可优雅地处理多模态的行动分布,适用于高维行动空间,表现出令人印象深刻的训练稳定性; -
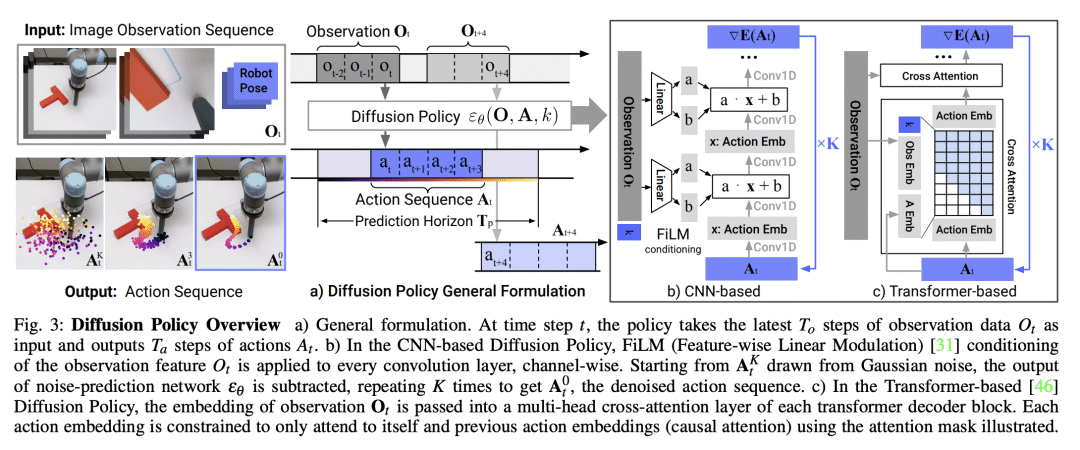
为充分释放扩散模型在物理机器人视觉运动策略学习中的潜力,技术上的贡献包括 receding horizon control、visual conditioning 和时间序列扩散 transformer。
一句话总结:
扩散策略是一种机器人行为生成的新方法,通过将机器人的视觉运动策略表示为条件去噪扩散过程,其性能始终优于现有方法,平均提高了46.9%。
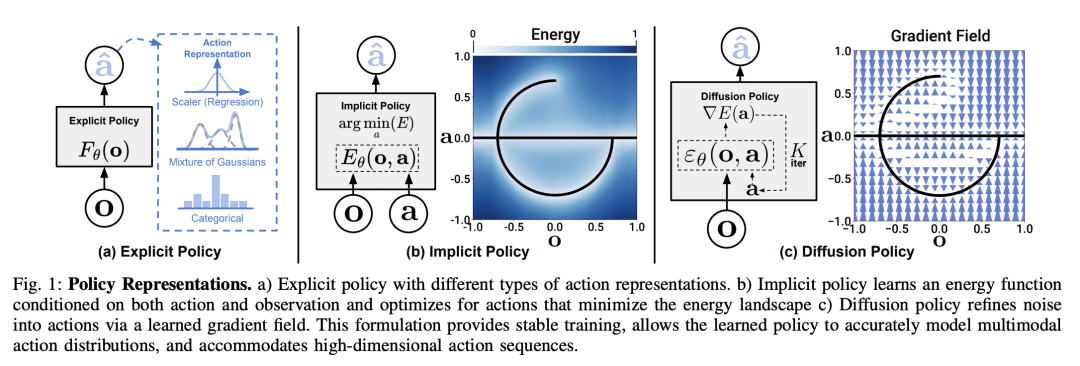
This paper introduces Diffusion Policy, a new way of generating robot behavior by representing a robot's visuomotor policy as a conditional denoising diffusion process. We benchmark Diffusion Policy across 11 different tasks from 4 different robot manipulation benchmarks and find that it consistently outperforms existing state-of-the-art robot learning methods with an average improvement of 46.9%. Diffusion Policy learns the gradient of the action-distribution score function and iteratively optimizes with respect to this gradient field during inference via a series of stochastic Langevin dynamics steps. We find that the diffusion formulation yields powerful advantages when used for robot policies, including gracefully handling multimodal action distributions, being suitable for high-dimensional action spaces, and exhibiting impressive training stability. To fully unlock the potential of diffusion models for visuomotor policy learning on physical robots, this paper presents a set of key technical contributions including the incorporation of receding horizon control, visual conditioning, and the time-series diffusion transformer. We hope this work will help motivate a new generation of policy learning techniques that are able to leverage the powerful generative modeling capabilities of diffusion models. Code, data, and training details will be publicly available.
论文链接:https://arxiv.org/abs/2303.04137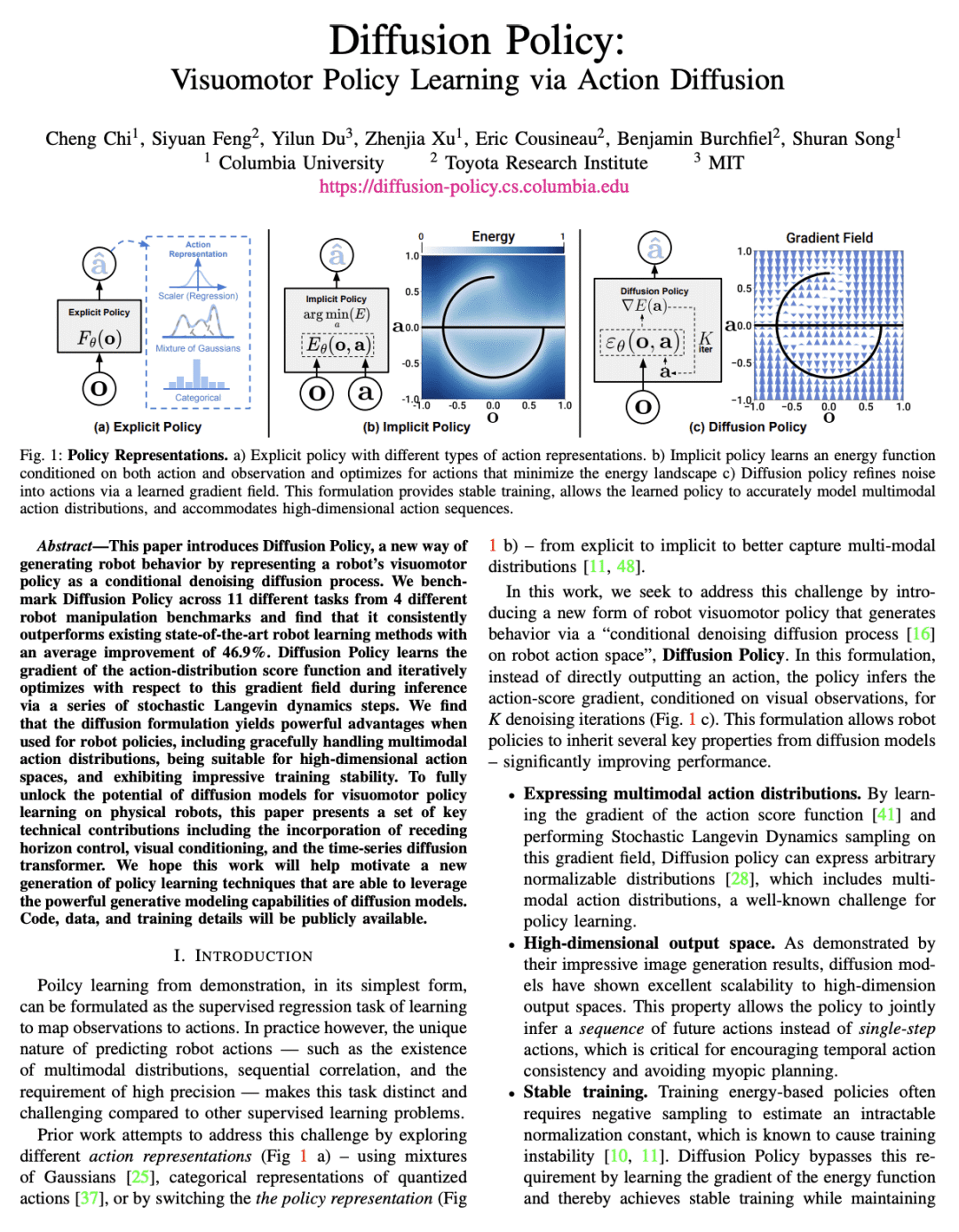

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢