
【推荐理由】:本文提出了Visual ChatGPT,它打开了将ChatGPT和视觉基础模型结合起来的大门,使ChatGPT能够处理复杂的视觉任务。
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
微软亚洲研究院
论文地址:https://arxiv.org/pdf/2303.04671.pdf
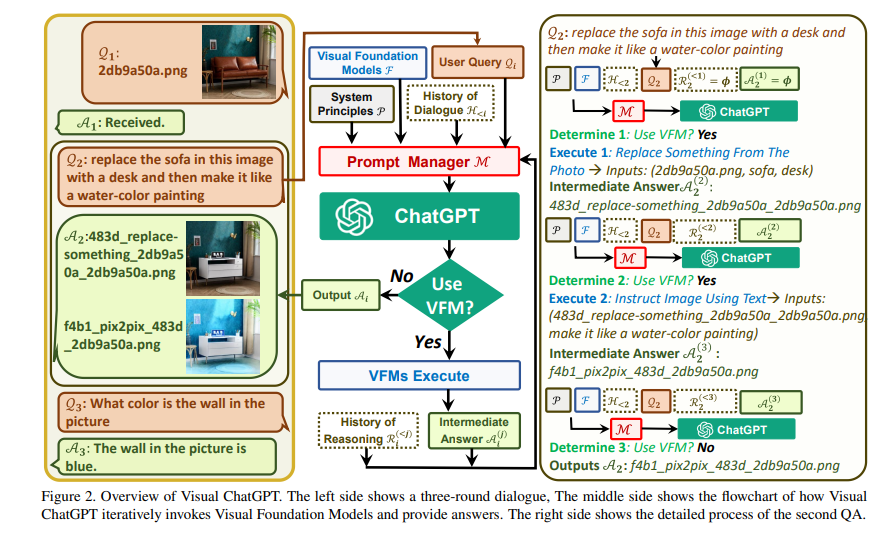
ChatGPT因其在许多领域具有卓越的对话能力和推理能力而引起了跨领域的关注。然而,由于ChatGPT是使用语言进行训练的,因此目前无法处理或生成来自视觉世界的图像。与此同时,像视觉Transformer或稳定扩散这样的视觉基础模型虽然展现出了很强的视觉理解和生成能力,但它们只是针对特定任务的专家,仅具有单一输入和输出的一轮固定任务。为此,我们建立了一个名为“Visual ChatGPT”的系统,结合了不同的视觉基础模型,使用户能够与ChatGPT交互,包括:1)发送和接收不仅是语言,还包括图像;2)提供需要多个AI模型多步协作的复杂视觉问题或视觉编辑指令;3)提供反馈并要求纠正结果。我们设计了一系列提示,将视觉模型信息注入到ChatGPT中,考虑到多个输入/输出模型和需要视觉反馈的模型。实验证明,Visual ChatGPT为借助视觉基础模型探究ChatGPT在视觉角色方面的能力开辟了大门。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢