
Prismer实现了微调和少量的学习视觉语言推理性能,与当前最先进的技术具有竞争力,同时需要减少两个数量级的训练数据。Prismer是一个数据和参数高效的视觉语言模型,它利用了一群多样化的、预先训练有素的领域模型。

网站: https://shikun.io/projects/prismer
Github: github.com/NVlabs/Prismer
作者:Shikun Liu、Linxi Fan、Edward Johns、Zhiding Yu、Chaowei Xiao和Anima Anandkumar
一作是英伟达优秀暑期实习生。

大型预训练模型在广泛的任务中表现出卓越的泛化能力。然而,就训练和推理所需的计算资源以及对大量训练数据的需求而言,这些能力的成本很高。视觉语言学习中的问题可以说更具挑战性。这个领域是语言处理的严格超级集,同时也需要视觉和多模态推理特有的额外技能。一个典型的解决方案是使用大量的图像文本数据来训练一个巨大的整体模型,该模型学会从头开始,同时在同一通用架构中开发这些特定于模式的技能。
相反,我们研究了一种替代方法,通过不同和独立的子网络(称为“专家”)学习这些技能和领域知识。因此,每个专家都可以针对特定任务进行独立优化,允许使用特定于领域的数据和架构,这些数据和架构在单个大型网络中是不可行的。这可以提高培训效率,因为该模型可以专注于整合专业技能和领域知识,而不是试图同时学习所有内容,使其成为缩小多模式学习的有效方法。为了实现这一目标,我们提出了Prismer,这是一个视觉条件的自回归文本生成模型,经过训练可以更好地使用各种预先培训的领域专家来完成开放式视觉语言推理任务。
Prismer的关键设计元素包括:i)用于网络规模知识的强大视觉和语言模型,以及ii)特定模式的视觉专家编码多种类型的视觉信息,包括低级视觉信号(如深度)和高级视觉信号(如实例和语义标签)作为辅助知识的一种形式。所有专家模型都是单独预训练和冻结的,并通过一些轻量级可训练组件连接,这些组件仅占总网络参数的20%左右。
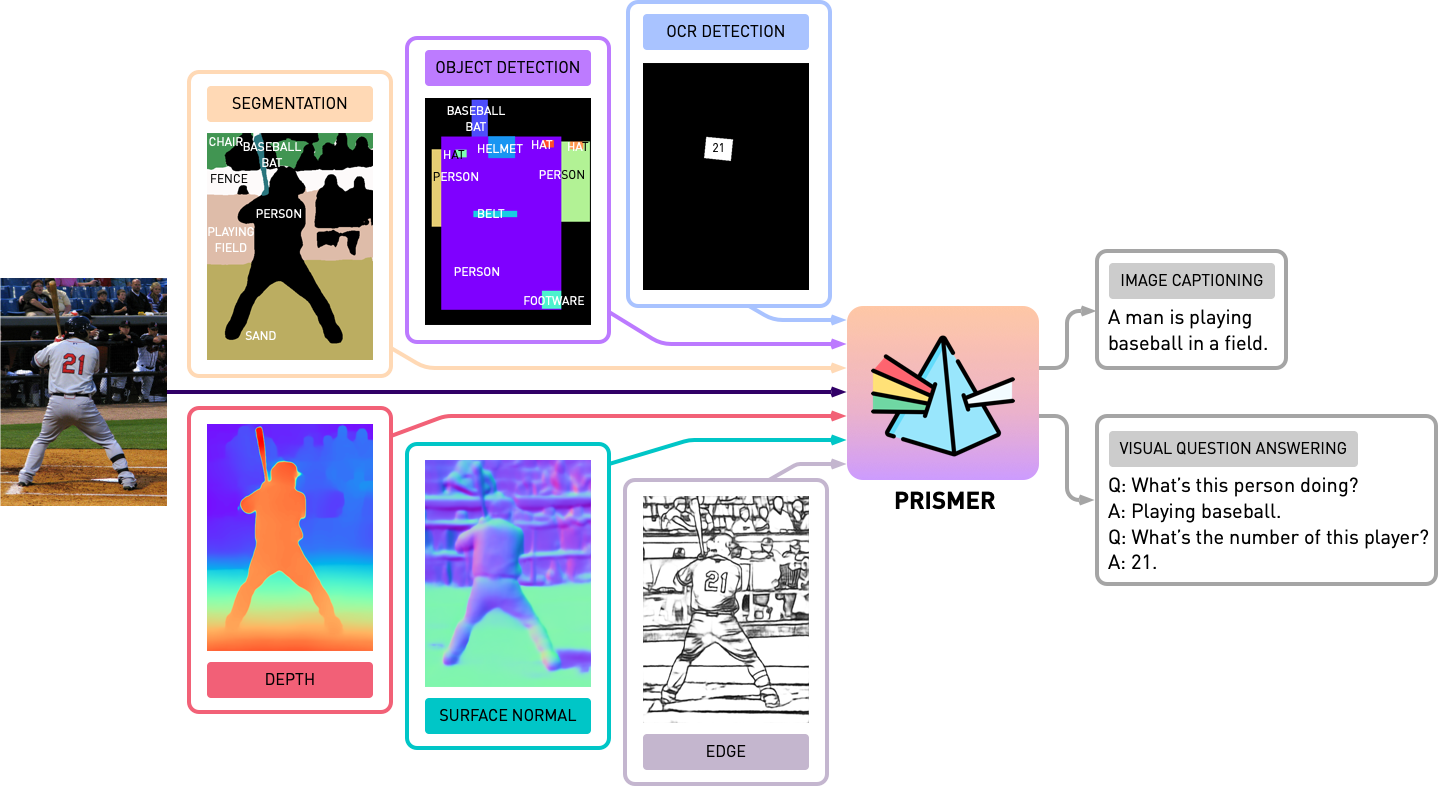
Prismer是一个数据高效的视觉语言模型,通过其预测的多模态信号利用各种预先培训的专家。它可以执行视觉语言推理任务,如图像字幕和VQA。
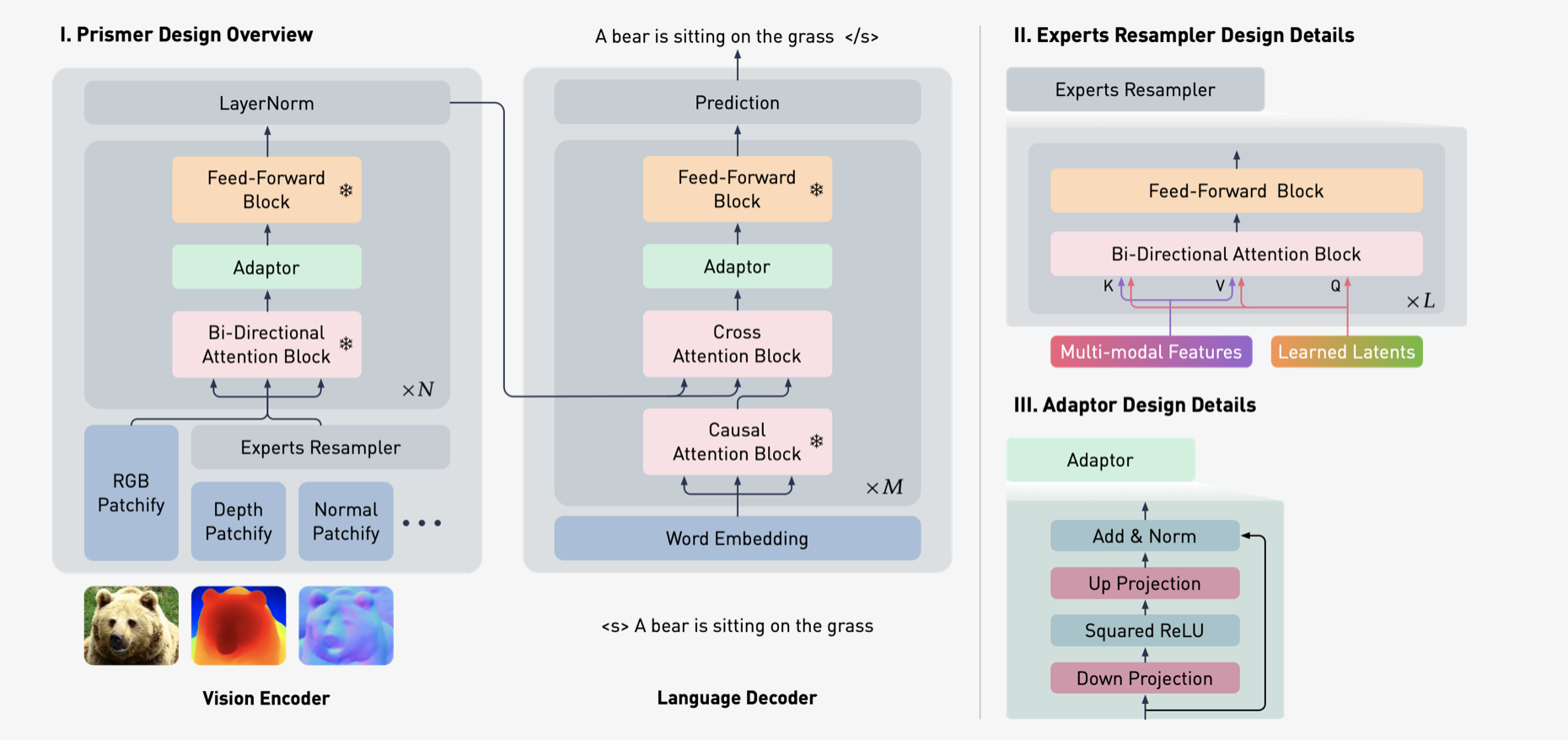
Prismer模型设计
Prismer是一个编码器-解码器变压器模型,它利用了现有预先培训的专家库。它由一个视觉编码器和一个自动回归语言解码器组成。视觉编码器将RGB图像及其相应的多模态标签作为输入(例如,深度、表面法线、分割标签,由冷冻预培训的专家预测),并输出一系列RGB和多模态特征。
然后,语言解码器通过交叉注意受这些多模态功能为条件,并生成一系列文本令牌。Prismer旨在充分利用预先培训的专家,同时将可培训参数的数量保持在最低限度。为此,预先培训的专家的大多数网络权重被冻结,以保持他们学到的知识的完整性并防止灾难性的遗忘。
为了链接多模态标签以及Prismer的视觉和语言部分,我们插入了两种类型的参数效率可训练组件:专家重新采样器:专家重新采样器学习预定义的潜伏输入查询数量,以交叉参加从所有多模态特征连接的扁平嵌入,灵感来自感知器和火烈鸟模型。然后,重新采样器将多模态特征压缩为数量少得多的令牌,等于学习的潜在查询数量,作为一种辅助知识蒸馏形式。
适配器:适配器具有编码器解码器设计,首先将输入特征向下投影到更小的尺寸,应用非线性,然后将特征向上投影到原始输入尺寸。通过剩余连接,我们初始化所有权重接近零的适配器,以近似恒等函数。结合语言解码器中的标准交叉注意力块,该模型能够在使用配对图像文本数据的预训练期间从特定领域的仅视觉和仅语言的骨干顺利过渡到视觉语言模型。
Prismer是一个生成模型,用单个目标训练,以自动递归预测下一个文本令牌。因此,我们将所有视觉语言推理任务重新制定为语言建模或前缀语言建模问题。例如,给定多模态令牌和作为前缀的问题,模型为视觉问题回答任务生成答案;给定多模态令牌,模型为图像字幕任务生成标题。一旦我们有了前缀提示,我们可以像在开放式设置中那样以自回归的方式对输出文本进行采样;或者我们可以像在封闭式设置中一样,从固定的完成集中对对对数可能性进行排序。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢