
ODISE 是一种新方法,将预训练的文本-图像扩散和判别模型统一起来,在开放词表全景分割和语义分割任务中的表现超过了以往的最先进水平。
标题:Open-Vocabulary Panoptic Segmentation with Text-to-Image Diffusion Models
作者:J Xu, S Liu, A Vahdat, W Byeon, X Wang, S D Mello
[NVIDIA & UC San Diego]
项目地址:https://jerryxu.net/ODISE/
论文地址:https://arxiv.org/abs/2303.04803
-
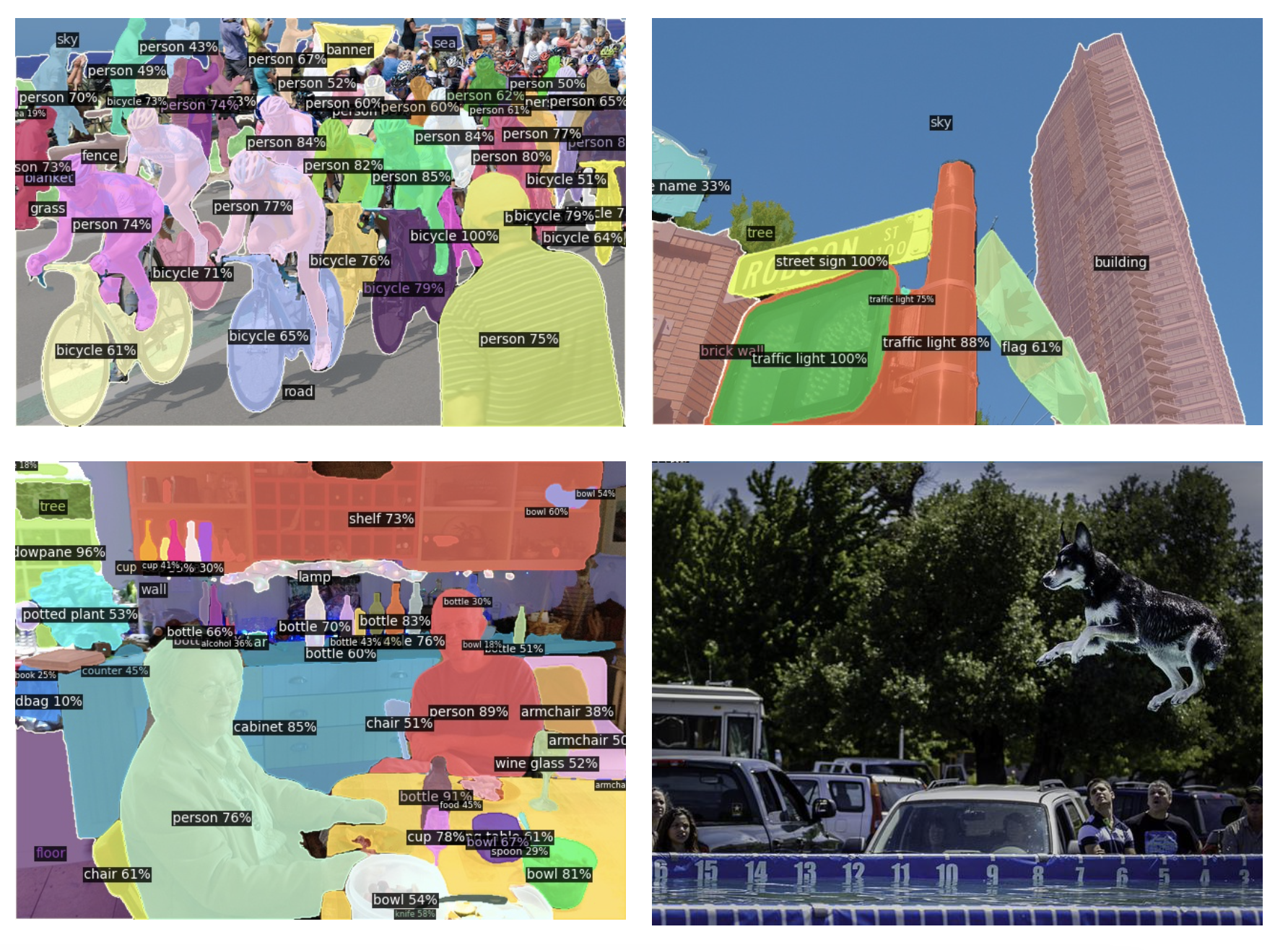
ODISE 提出一个管道,利用文本-图像扩散和判别模型进行开放词表全景分割; -
ODISE 在全景和语义分割任务中都以明显的优势超过了之前最先进的方法; -
文本-图像扩散模型的内部表示空间,与现实世界中的开放概念高度相关,使其对下游识别任务有价值; -
ODISE 证明了文本-图像生成模型在开放词表分割任务中的巨大潜力,并达到了一个新水平。
基于开放词汇DIffusion的泛光分离,它统一了预先训练的文本图像扩散和判别模型,以执行开放词汇泛光分割。文本到图像的扩散模型显示了生成具有不同开放词汇语言描述的高质量图像的非凡能力。这表明他们的内部表示空间与现实世界中的开放概念高度相关。
另一方面,像CLIP这样的文本图像判别模型擅长将图像分类为开放式词汇标签。我们建议利用这两个模型的冻结表示来执行野外任何类别的泛光学分割。我们的方法在开放词汇泛观和语义分割任务上都具有显著优势,优于以前的技术水平。特别是,仅通过COCO培训,我们的方法在ADE20K数据集上实现了23.4 PQ和30.0 mIoU,与之前最先进的技术相比,8.3 PQ和7.9 mIoU绝对改进。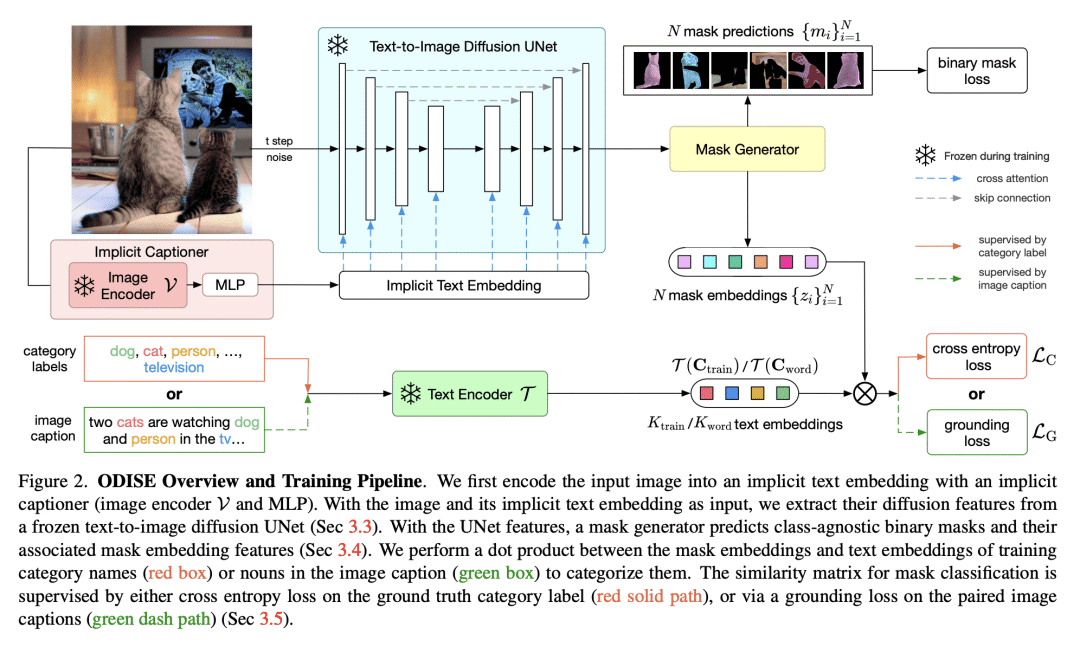
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢